
一、简介
Hadoop是一个开源框架,允许使用简单的编程模型在跨计算机集群的分布式环境中存储和处理大数据。它的设计是从单个服务器扩展到数千个机器,每个都提供本地计算和存储
二、准备工作
1、准备三台服务器
10.0.7.62 woniu、10.0.7.63 woniu1、10.0.7.30 woniu2
2、部署NTP服务器进行时间同步(可忽略)
https://blog.csdn.net/u011374856/article/details/103307623
3、配置主机名跟IP地址映射
https://blog.csdn.net/u011374856/article/details/103310847
4、ssh免密码登录
https://blog.csdn.net/u011374856/article/details/103311150
5、安装JDK8(三台主机都安装)
https://blog.csdn.net/u011374856/article/details/103309826
三、Hadoop下载
下载地址:http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.15.1.tar.gz
注:其他大数据组件也可在 http://archive.cloudera.com/cdh5/cdh/5 版本库中找到
四、Hadoop安装
1、集群结构
| NameNode | SecondaryNameNode | DataNode | NodeManager | ResourceManager | |
| woniu | √ | √ | √ | ||
| woniu1 | √ | √ | √ | √ | |
| woniu2 | √ | √ |
2、解压压缩包
tar -zxvf hadoop-2.6.0-cdh5.15.1.tar.gz3、创建以下目录
/home/data/hadoop/dfs/data
/home/data/hadoop/dfs/name
/home/data/hadoop/temp4、配置环境变量
#配置当前用户环境变量
vi ~/.bash_profile
#在文件中添加如下命令,记得切换自己文件路径
export HADOOP_HOME=/home/app/hadoop-2.6.0-cdh5.15.1
export PATH=$HADOOP_HOME/bin:$PATH
#立即生效
source ~/.bash_profile5、进入hadoop配置文件目录
cd /home/app/hadoop-2.6.0-cdh5.15.1/etc/hadoop6、配置hadoop命令环境变量
#编辑hadoop-env.sh
vi hadoop-env.sh
#编辑yarn-env.sh
vi yarn-env.sh
#编辑mapred-env.sh
vi mapred-env.sh
#三个文件都添加JAVA_HOME
export JAVA_HOME=/home/app/jdk1.8.0_231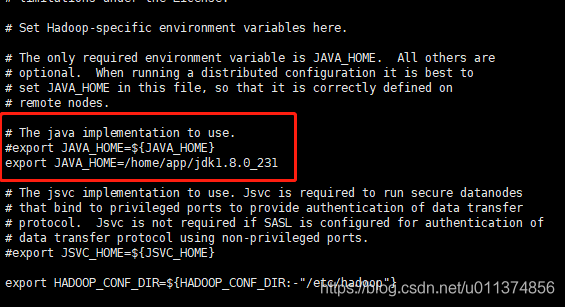
7、 编辑core-site.xml
#编辑core-site.xml
vi core-site.xml
#在文件中添加如下命令
<configuration>
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://woniu:6001</value>
</property>
<!-- 指定hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/data/hadoop/temp</value>
</property>
</configuration> 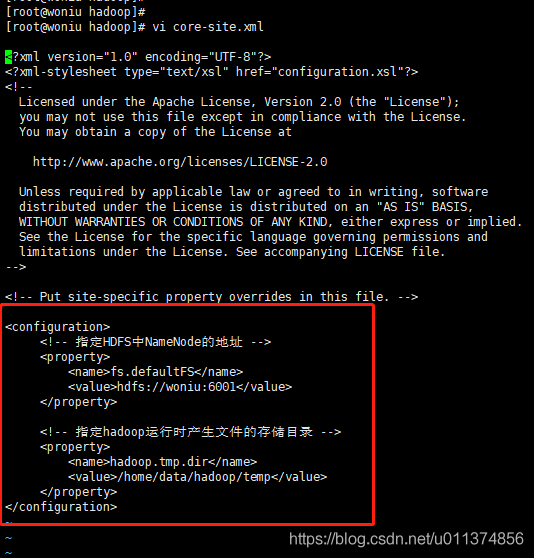
8、编辑hdfs-site.xml
#编辑hdfs-site.xml
vi hdfs-site.xml
#在文件中添加如下命令
<configuration>
<!-- 设置dfs副本数 -->
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 设置secondname的端口 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>woniu1:6002</value>
</property>
<!-- name目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/data/hadoop/dfs/name</value>
</property>
<!-- data目录 -->
<property>
<name>dfs.namenode.data.dir</name>
<value>/home/data/hadoop/dfs/data</value>
</property>
</configuration>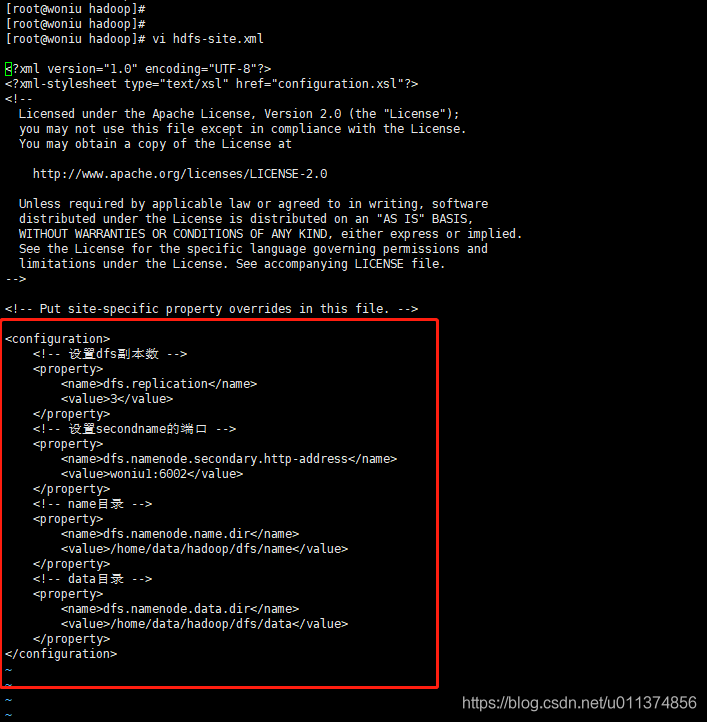
9、编辑mapred-site.xml
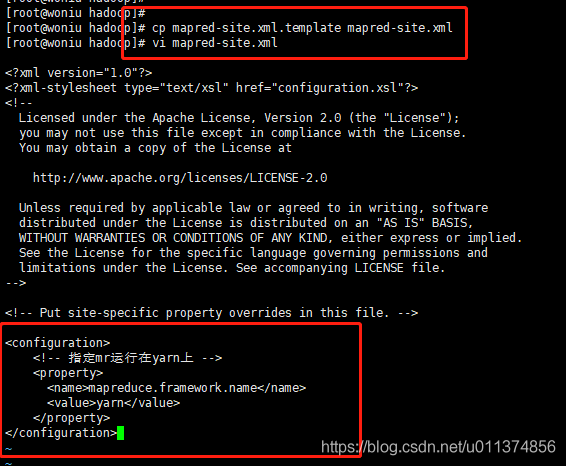
#拷贝一份mapred-site.xml
cp mapred-site.xml.template mapred-site.xml
#编辑mapred-site.xml
vi mapred-site.xml
#在文件中添加如下命令
<configuration>
<!-- 指定mr运行在yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
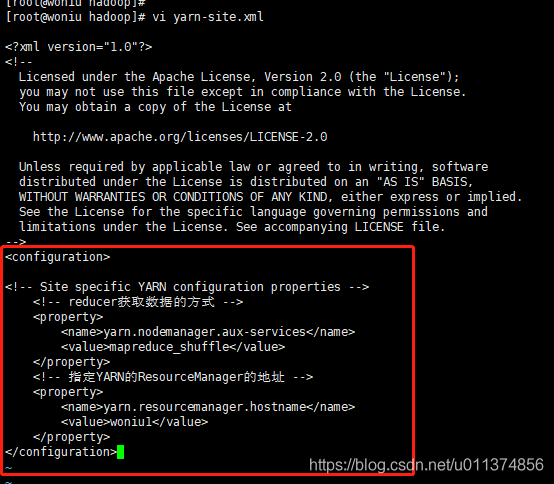
10、编辑yarn-site.xml
#编辑yarn-site.xml
vi yarn-site.xml
#在文件中添加如下命令
<configuration>
<!-- reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>woniu1</value>
</property>
<!-- 该节点上YARN可使用的物理内存总量,默认是8192(MB)-->
<!-- 注意,如果你的节点内存资源不够8GB,则需要调减小这个值 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>6144</value>
</property>
<!-- 单个任务可申请最少内存,默认1024MB -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<!-- 单个任务可申请最大内存,默认8192MB -->
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>6144</value>
</property>
</configuration>
11、编辑slaves
#编辑slaves
vi slaves
#在文件中删除
删除localhost
#在文件中添加如下
woniu
woniu1
woniu2
12、 复制hadoop文件夹到另一台主机,注意:在拷贝目录下(例如:/home/app/)执行
#复制到woniu1主机
scp -r hadoop-2.6.0-cdh5.15.1/ root@woniu1:/home/app/
#复制到woniu2主机
scp -r hadoop-2.6.0-cdh5.15.1/ root@woniu2:/home/app/五、Hadoop启动
1、第一次启动需要格式化(注意:只有第一次需要)
hadoop namenode -format2、启动&停止hdfs
#启动hdfs
./start-dfs.sh
#停止hdfs
./stop-dfs.sh3、启动&停止yarn
注意:Namenode和ResourceManger,不是同一台机器,不能在NameNode上启动 yarn,应该在ResouceManager所在的机器上启动yarn
#启动yarn
./start-yarn.sh
#停止yarn
./stop-yarn.sh4、查看进程
jps六、可视化平台
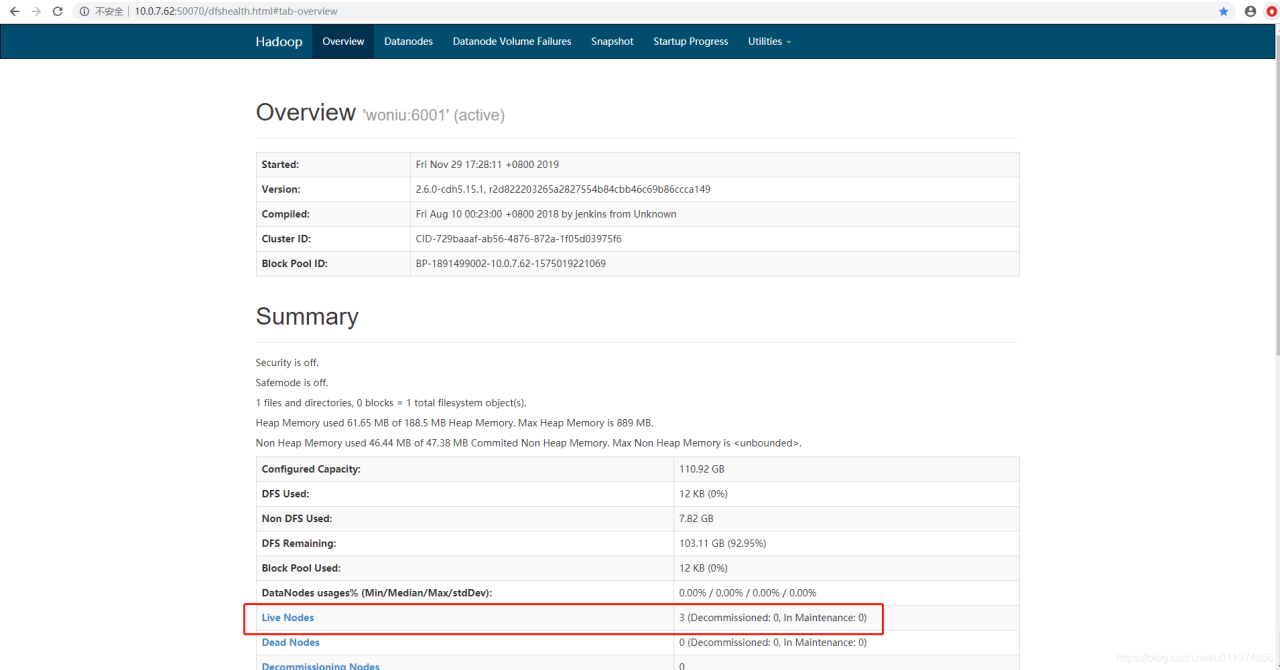
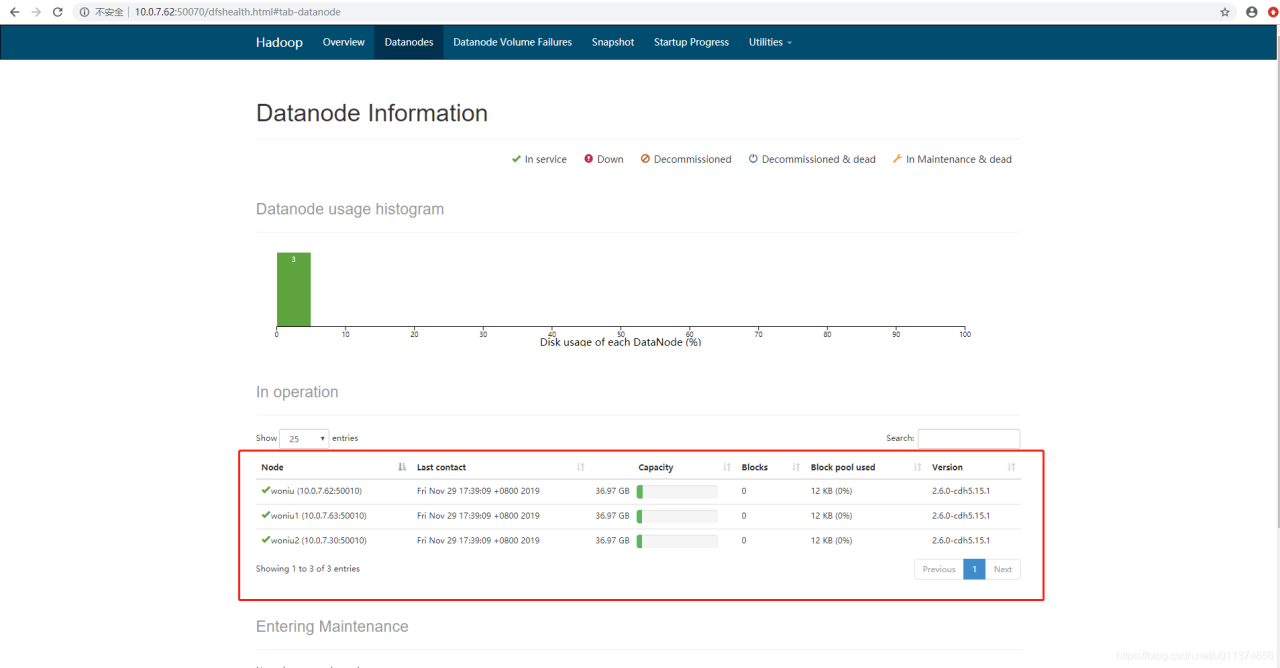
1、hdfs平台
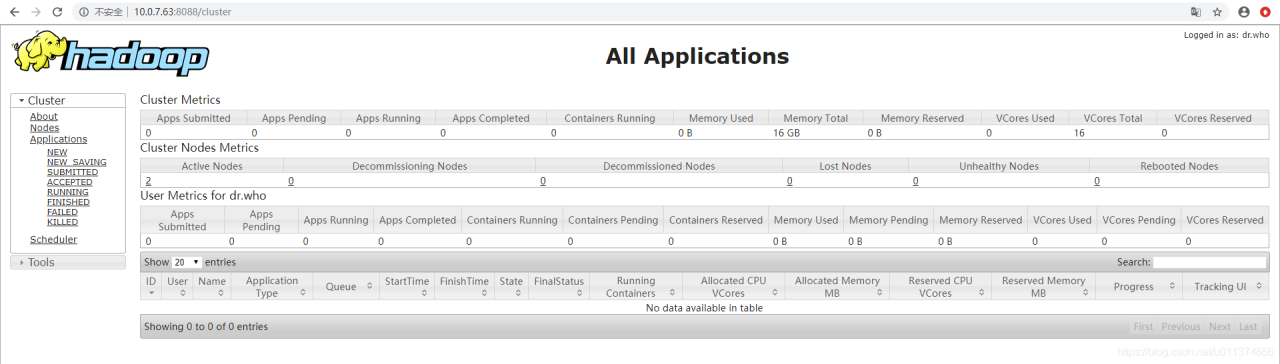
2、yarn平台
七、部署成功
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/78065.html

