
环境准备
HashMap基本介绍
- HashMap是【key-value】对的方式来存储数据的;
- key不能重复,但是值可以重复,允许使用null键和null值;
- 如果添加相同的key,则会覆盖原来的key-value,等同于修改(key不会替换,value会替换);
- 与HashSet一样,不保证映射的顺序,因为底层是以hash表的方式来存储的;
- HashMap没有实现同步,因此是线程不安全的;
HashMap底层结构
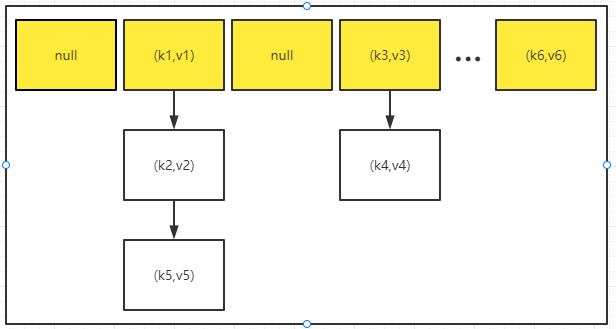
扩容机制
- HashMap底层维护了Node类型的数组table,默认为null;
- 当创建对象时,将加载因子loadfactor初始化为0.75;
- 当添加key-value时,通过key的哈希值得到在table的索引。然后判断该索引是否有元素,如果没有元素直接添加。如果该索引处有元素,继续判断该元素的key是否和准备加入的key相等,如果相等,则直接替换val;如果不相等需要判断是树结构还是链表结构,做出不同处理。如果添加时发现容量不够,则需要扩容;
- 第1次添加,则需要扩容table容量为16,临界值threshold为12;
- 以后再扩容,则需要扩容table容量为原来的2倍,临界值为原来的2倍,即24,依此类推;
- 在Java8中,如果一条链表的元素个数超过TREEIFY_THRESHOLD(默认是8),并且table的大小 >= MIN_TREEIFY_CAPACITY(默认64),就会进化树化(红黑树);
源码分析
@SuppressWarnings("all")
public class HashMapSource {
public static void main(String[] args) {
HashMap map = new HashMap();
map.put("java", 10);
map.put("php", 10);
map.put("java", 20);
}
}
1.执行构造器 new HashMap();
初始化加载因子 this.loadFactor = DEFAULT_LOAD_FACTOR 0.75
Node<K,V>[] table = null
2.执行put,先调用hash(key)
public V put(K key, V value) {
return putVal(// hash(key), key, value, false, true);
}
// 计算 Kay 的 hash 值
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
3.执行putVal
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
// 如果底层的table数组为null,或者length == 0 ,就扩容到16
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
// 取出hash值对应的table的索引位置的Node,如果为null,就直接把加入的K-V创建newNode放入
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
// 如果table的索引位置的key的hash和新加入的hash相同,并且 对象相同或者equals()比较后相同
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 已经树化
else if (p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// 死循环比较,直到插入链表后停止循环
for (int binCount = 0; ; ++binCount) {
// 如果整个链表,没有和他相同,就加到该链表的最后
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
// 加入后,判断当前链表的个数,是否已经到达8个,到8个进行 treeifyBin 会判断是扩容还是树化
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
// 判断是否有相同的,如果有就break 走更新
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
// 更新操作
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value; // 替换
afterNodeAccess(e);
return oldValue;
}
}
// 每增加newNode就++
++modCount;
// 到了临界值后就扩容
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
treeifyBin
转成红黑树
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
// 如果table == null , 或者大小没有到 64,不树化,先扩容数组!
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
// 树化
else if ((e = tab[index = (n - 1) & hash]) != null) {
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
hd.treeify(tab);
}
}
测试扩容
1.put第1个元素时进行第一次扩容,size=16;
2.put第9个元素时进行第二次扩容,size=32,链表已经9个元素了;
3.put第10个元素时进行第三次扩容,size=64,此时已经满足树化条件了;
4.put第11个元素时进行树化,HashMap$Node => HashMap$TreeNode
import java.util.HashMap;
/** @author Strive */
@SuppressWarnings("all")
public class HashMapSource2 {
public static void main(String[] args) {
HashMap map = new HashMap();
for (int i = 1; i <= 12; i++) {
map.put(new A(i), "hello");
}
System.out.println("hashMap=" + map);
}
}
class A {
private int num;
public A(int num) {
this.num = num;
}
@Override
public int hashCode() {
return 100;
}
@Override
public String toString() {
return "\nA{" + "num=" + num + '}';
}
}
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/78407.html

![[springMVC学习]6、视图解析器,debug源码](https://www.bmabk.com/wp-content/uploads/2022/05/post-loading-480x300.gif)