
环境:springboot2.3.8.RELEASE+Redis
bloomfilter相关知识参考


布隆过滤器(Bloom Filter)是由布隆(Burton Howard Bloom)在1970年提出的。它实际上是由一个很长的二进制向量(位向量)和一系列随机映射函数组成,布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率(假正例False positives,即Bloom Filter报告某一元素存在于某集合中,但是实际上该元素并不在集合中)和删除困难,但是没有识别错误的情形(即假反例False negatives,如果某个元素确实没有在该集合中,那么Bloom Filter 是不会报告该元素存在于集合中的,所以不会漏报)。因此,Bloom Filter不适合那些“零错误”的应用场合。而在能容忍低错误率的应用场合下,Bloom Filter通过极少的错误换取了存储空间的极大节省。
BloomFilter在判断数据是否时,如果判断的数据存在那有可能不存在,如果不存在那就是真的不存在。为何?BloomFilter本身就是用一个很长的二进制位来表示数据是否存在。在标记一个数据时是通过N个Hash函数来计算当前的值,每一个hash函数将对应的值进行计算会得到一个整数,然后就把对应的整数位设置为1。所以当你通过N个Hash函数计算后返回数据存在,那有可能是不存在的,因为有可能某一个二进制位可能是其它某个数据计算后设置为1的。如果二进制位足够长,使用的Hash函数比较得多,那么错误率就相对的比较少,但是这样效率就会相应的降低。
优点:
相比于其它的数据结构,布隆过滤器在空间和时间方面都有巨大的优势。布隆过滤器存储空间和插入/查询时间都是常数,取决于hash函数的个数k(O(k))。另外, Hash 函数相互之间没有关系,方便并行实现。布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势。
缺点:
布隆过滤器的缺点和优点一样明显。误算率(False Positive)是其中之一。随着存入的元素数量增加,误算率随之增加。但是如果元素数量太少,则使用散列表足矣。
另外,一般情况下不能从布隆过滤器中删除元素. 我们很容易想到把位列阵变成整数数组,每插入一个元素相应的计数器加1, 这样删除元素时将计数器减掉就可以了。然而要保证安全的删除元素并非如此简单。首先我们必须保证删除的元素的确在布隆过滤器里面. 这一点单凭这个过滤器是无法保证的。另外计数器回绕也会造成问题。
以上简单介绍了BloomFilter,接下来看看如何在项目中使用。
- 相关依赖
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>30.1-jre</version>
</dependency>
</dependencies>- 相关配置
spring:
redis:
host: localhost
port: 6379
password:
database: 3
lettuce:
pool:
maxActive: 8
maxIdle: 100
minIdle: 10
maxWait: -1
---
# 自定义相关的属性配置
bf:
expected-insertions: 10001
fpp: 0.01 @Component
@ConfigurationProperties(prefix = "bf")
public class BloomFilterProperties {
/**
* 预期插入量
*/
private Long expectedInsertions = 1000L;
/**
* 误判率(大于0,小于1.0)
*/
private Double fpp = 0.001D;
public Long getExpectedInsertions() {
return expectedInsertions;
}
public void setExpectedInsertions(Long expectedInsertions) {
this.expectedInsertions = expectedInsertions;
}
public Double getFpp() {
return fpp;
}
public void setFpp(Double fpp) {
this.fpp = fpp;
}
}- BloomFilter核心类
@Component
public class RedisBloomFilter {
/**
* 二进制位大小(多少位)
*/
private Long numBits ;
/**
* hash函数个数
*/
private Integer numHashFunctions ;
private Funnel<CharSequence> funnel = Funnels.stringFunnel(Charset.forName("UTF-8")) ;
@Resource
private StringRedisTemplate stringRedisTemplate ;
@Resource
private BloomFilterProperties prop ;
@PostConstruct
public void initRedisBloomFilter() {
this.numBits = optimalNumOfBits(prop.getExpectedInsertions(), prop.getFpp()) ;
this.numHashFunctions = optimalNumOfHashFunctions(prop.getExpectedInsertions(), numBits) ;
}
/**
* <p>
* 最佳的位数(二进制位数)
* </p>
* <p>时间:2021年2月7日-上午10:13:43</p>
* @author xg
* @param expectedInsertions 预期插入的数量
* @param fpp 错误率大于0,小于1.0
* @return long
*/
public long optimalNumOfBits(long expectedInsertions, double fpp) {
if (fpp == 0) {
fpp = Double.MIN_VALUE;
}
return (long) (-expectedInsertions * Math.log(fpp) / (Math.log(2) * Math.log(2)));
}
/**
* <p>
* 最佳的Hash函数个数
* </p>
* <p>时间:2021年2月7日-上午10:17:26</p>
* @author xg
* @param expectedInsertions 预期插入的数量
* @param numBits 根据optimalNumOfBits方法计算的最佳二进制位数
* @return int
*/
public static int optimalNumOfHashFunctions(long expectedInsertions, long numBits) {
return Math.max(1, (int) Math.round((double) numBits / expectedInsertions * Math.log(2)));
}
// 存数据
public boolean put(String key, String value) {
byte[] bytes = Hashing.murmur3_128().hashObject(value, funnel).asBytes();
long hash1 = lowerEight(bytes);
long hash2 = upperEight(bytes);
boolean bitsChanged = false;
long combinedHash = hash1;
for (int i = 0; i < numHashFunctions; i++) {
long bit = (combinedHash & Long.MAX_VALUE) % numBits ;
// 这里设置对应的bit为1
stringRedisTemplate.opsForValue().setBit(key, bit, true) ;
combinedHash += hash2;
}
return bitsChanged;
}
// 判断数据是否已经存在
public boolean mightContain(String key, String value) {
byte[] bytes = Hashing.murmur3_128().hashObject(value, funnel).asBytes();
long hash1 = lowerEight(bytes);
long hash2 = upperEight(bytes);
long combinedHash = hash1;
for (int i = 0; i < numHashFunctions; i++) {
long bit = (combinedHash & Long.MAX_VALUE) % numBits ;
// 这里判断redis中对应位是否为1
if (!stringRedisTemplate.opsForValue().getBit(key, bit)) {
return false;
}
combinedHash += hash2;
}
return true;
}
private long lowerEight(byte[] bytes) {
return Longs.fromBytes(bytes[7], bytes[6], bytes[5], bytes[4], bytes[3], bytes[2], bytes[1], bytes[0]);
}
private long upperEight(byte[] bytes) {
return Longs.fromBytes(bytes[15], bytes[14], bytes[13], bytes[12], bytes[11], bytes[10], bytes[9], bytes[8]);
}
}以上核心类,大部分是从Guava中抄过来的,毕竟相关的数学知识也不懂啊(基本知道也不知道是为啥)。
- 测试
- 先存入数据
@Resource
private RedisBloomFilter redisBloomFilter ;
@GetMapping("/a")
public Object addItem() {
IntStream.range(1, 10001).forEach(i -> {
redisBloomFilter.put("bit.a", UUID.randomUUID().toString()) ;
});
return "success" ;
}存入10000个数据。
- 判断数据是否存在
@GetMapping("/e")
public Object exist(String value) {
int errors = 0 ;
for (int i = 0; i < 100; i++) {
if (redisBloomFilter.mightContain("bit.a", UUID.randomUUID().toString())) {
errors += 1 ;
}
}
return errors / 10000d ;
}这里我们用100个全新的UUID来判断错误率。
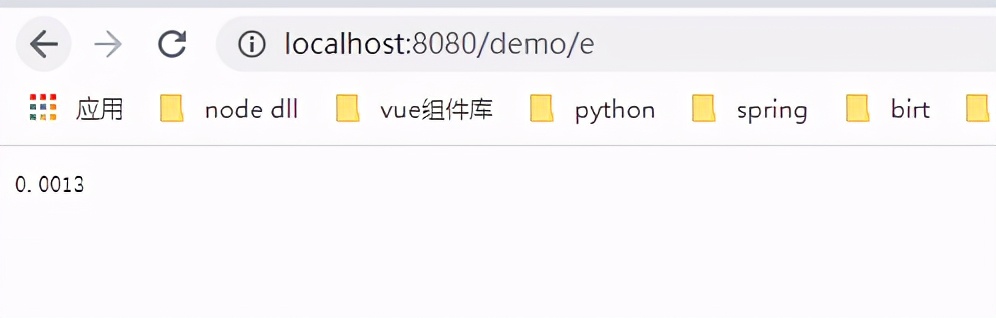
测试1000个值
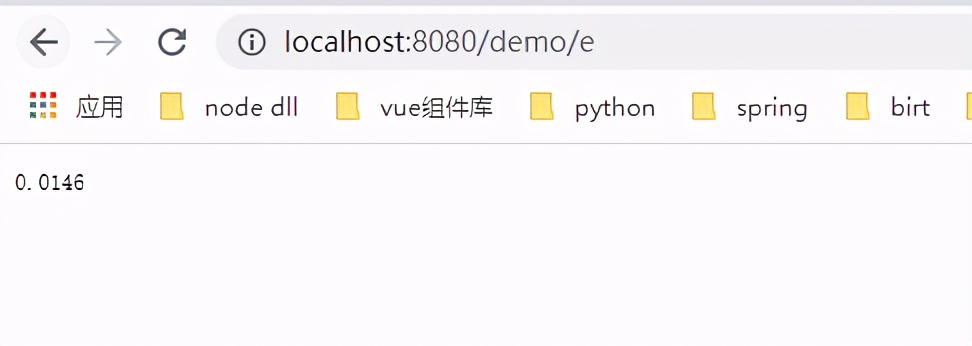
明显错误率上升了,但都控制在0.01。
完毕!!!
给个关注+转发呗谢谢






版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/80034.html

