
文章目录
前言
为什么要学习 string 类呢?
C 语言中,字符串是以 \0 结尾的一些字符的集合,为了操作方便,C 标准库中提供了一些 str 系列的库函数,但是这些库函数与字符串是分离开的,不太符合 OOP 的思想,而且底层空间需要用户自己管理,稍不留神可能还会越界访问。
在 OJ 中,有关字符串的题目基本以 string 类的形式出现,而且在常规工作中,为了简单、方便、快捷,基本都使用 string 类,很少有人去使用 C 库中的字符串操作函数。
参考文档:string类的文档介绍
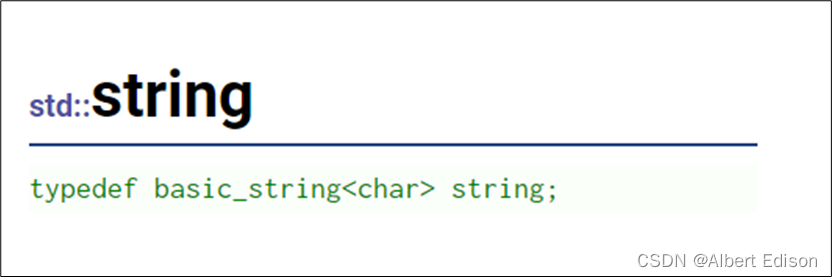
1. 标准库中的 string 类
(1)字符串是表示字符序列的类。
(2)标准的字符串类提供了对此类对象的支持,其接口类似于标准字符容器的接口,但添加了专门用于操作单字节字符字符串的设计特性。
(3)string 类是使用 char(即作为它的字符类型),使用它的默认 char_traits 和分配器类型。
(4)string 类是 basic_string 模板类的一个实例,它使用 char 来实例化 basic_string 模板类,并用 char_traits 和 allocator 作为 basic_string 的默认参数。
(5)这个类独立于所使用的编码来处理字节:如果用来处理多字节或变长字符(如 UTF-8)的序列,这个类的所有成员(如长度或大小)以及它的迭代器,将仍然按照字节(而不是实际编码的字符)来操作。
思考一下,为什么 string 是一个 basic_string ?
是因为编码的原因。编码的本质就是:内存当中存的全是 0 和 1,那么如果我要把它显示成对应的文字,比如:英文、中文、韩文等等,只能通过编码显示出来。
它是怎么显示出来的呢?
很简单,就是在显示之前,拿了一个值去查表,这个表就是值和显示值的映射表。
❗❗❗ 总结
(1)string 是表示字符串的字符串类。
(2)该类的接口与常规容器的接口基本相同,再添加了一些专门用来操作 string 的常规操作。
(3)string 在底层实际是:basic_string 模板类的别名,typedef basic_string<char, char_traits, allocator> string;
(4)不能操作多字节或者变长字符的序列。
注意:在使用 string 类时,必须包含 #include <string> 头文件以及 using namespace std;
2. string类对象的常见构造
官方文档给出了以下几种定义方式(我们只需要掌握几种即可)。
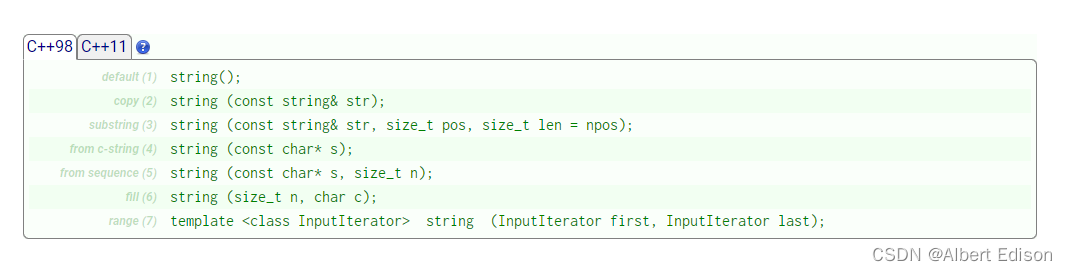
(1)无参构造
构造空的 string 类对象,即空字符串
string();
代码示例
int main()
{
string s1;
return 0;
}
(2)带参构造
用一个常量字符串来构造 string 类对象
string (const char* s);
代码示例
int main()
{
string s2("hello world");
return 0;
}
(3)拷贝构造
拿一个已经存在的对象去初始化另一个未存在的对象(加引用是为了减少拷贝)
string (const string& str);
代码示例
int main()
{
string s2("hello world");
string s3(s2);
return 0;
}
(4)用 n 个字符 c 去初始化
string 类对象中包含 n 个字符 c
string (size_t n, char c);
代码示例
int main()
{
// 用10个x去初始化s4对象
string s4(10, 'x');
return 0;
}
(5)用字符串的前 n 个字符去初始化
string (const char* s, size_t n);
代码示例
int main()
{
// 用字符串的前4个字符去初始化s5对象
string s5("https://cplusplus.com/reference/string/string/string/", 4);
return 0;
}
(6)从一个 string 对象的 pos 位置开始,拿 len 个字符去初始化
string (const string& str, size_t pos, size_t len = npos);
代码示例
int main()
{
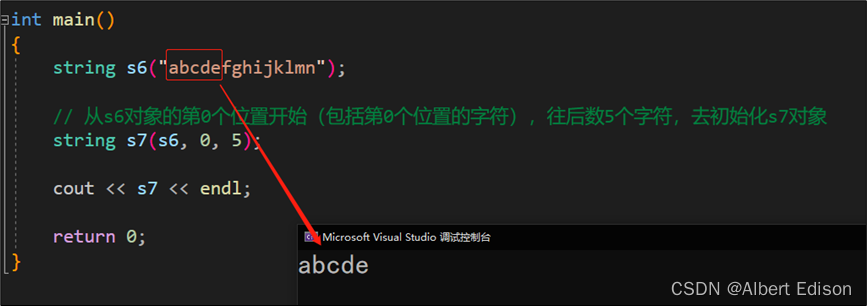
string s6("abcdefghijklmn");
// 从s6对象的第0个位置开始(包括第0个位置的字符),往后数5个字符,去初始化s7对象
string s7(s6, 0, 5);
cout << s7 << endl;
return 0;
}
可以打印看下结果:
大家有没有发现,len 是给了缺省值 nops 的,那么 npos 到底是什么呢?
npos 其实是 string 类里面的一个静态成员变量,给的值是 -1。
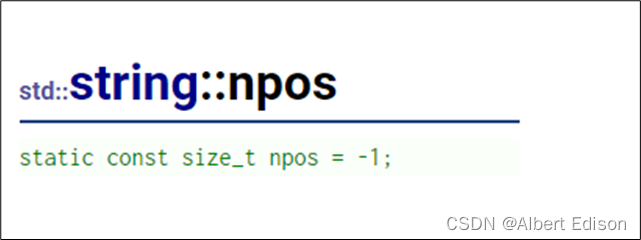
但是这里是用 size_t 无符号来修饰的,也就是说无符号的 -1,那么它的补码是全 1,也就是整型的最大值(42 亿多)。
所以 npos 在这里的寓意就是:从 pos 位置开始,往后取 42 亿多个字符。
当然,肯定不会有人傻到去写那么长的字符,所以换句话说,如果不给 len 的值,那么就是有多少取多少。
代码示例
int main()
{
string s6("abcdefghijklmn");
// 从s6对象的第0个位置开始, 有多少取多少
string s8(s6, 0);
cout << s8 << endl;
return 0;
}
运行结果:

3. string类对象的容量操作
我们将要学习以下的函数接口
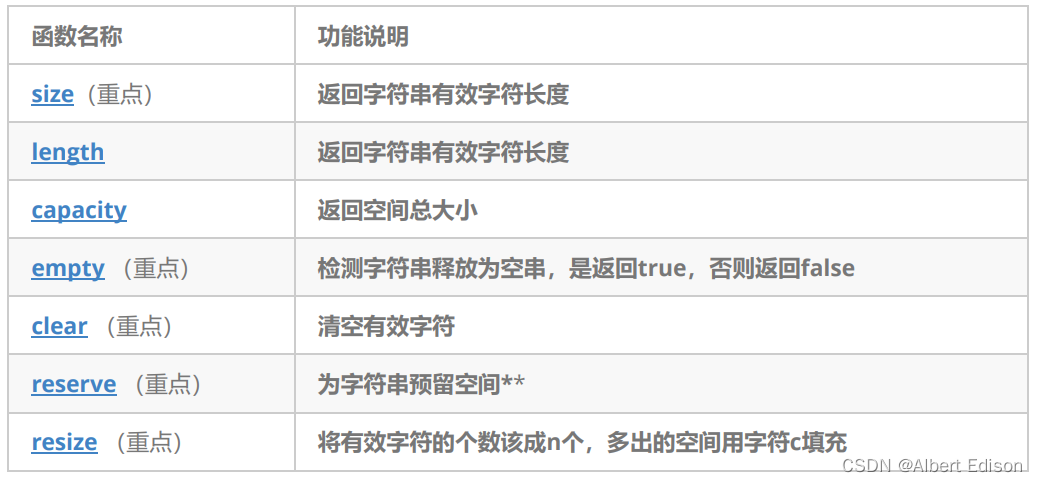
🍑 size
返回字符串有效字符长度
size_t size() const;
代码示例:
int main()
{
string s1("hello world");
cout << s1.size() << endl;
return 0;
}
运行结果
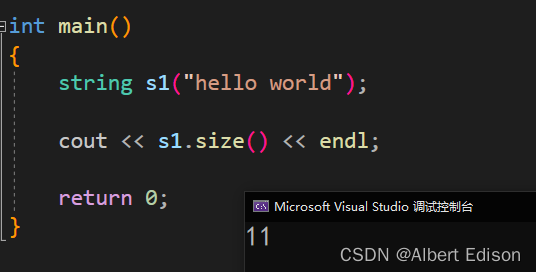
🍑 length
返回字符串有效字符长度(和 size 一样)
size_t length() const;
代码示例
int main()
{
string s2("hello world");
cout << s2.length() << endl;
return 0;
}
运行结果
size 与 length 方法底层实现原理完全相同,引入 size 的原因是为了与其他容器的接口保持一致,所以一般情况下基本都是用 size。
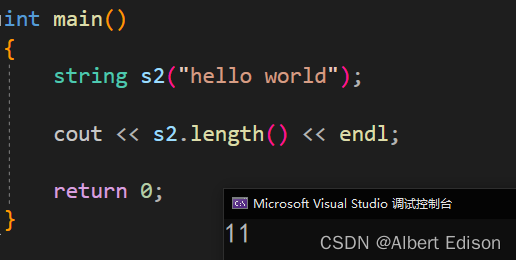
🍑 max_size
返回字符串可以达到的最大长度。
size_t max_size() const;
代码示例
int main()
{
string s3("hello world");
cout << s3.max_size() << endl;
return 0;
}
运行结果
这个实际上就是告诉你,字符串最大能开多长,但是这个函数在实际中并没有什么太大的用处。
🍑 capacity
返回分配的存储空间容量的大小
size_t capacity() const;
代码示例
int main()
{
string s4("hello world");
cout << s4.capacity() << endl;
return 0;
}
运行结果
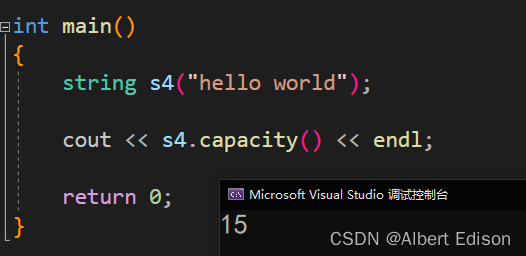
可以看到,这里默认的容量就是 15,那么 string 类的对象是如何扩容的呢?
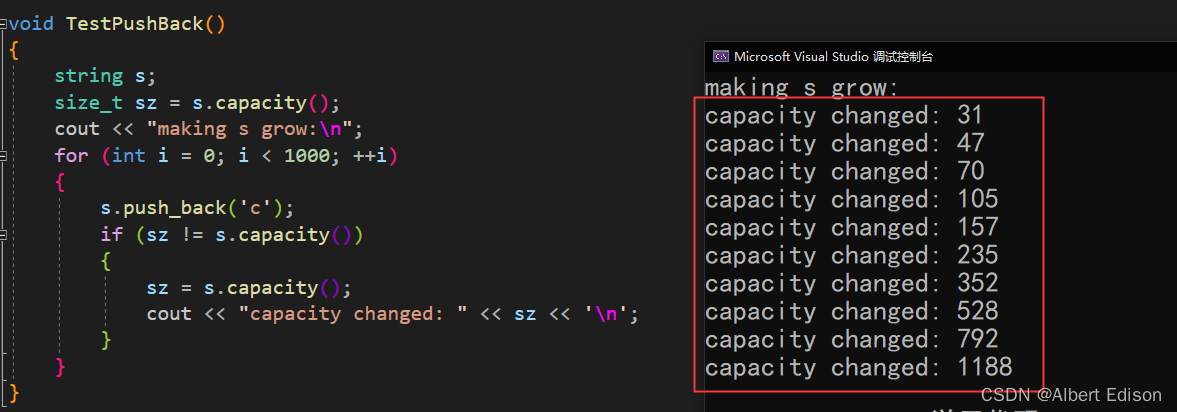
我这里写了一个测试代码,运行以后可以看到,在 VS 下,大约是按照 1.5 倍进行扩容的。
那么 Linux 平台下又是不一样的,它是按照 2 倍进行扩容的,为什么呢?
因为 VS 是 PJ 版本的,它是微软进行维护的;而 g++ 是由开源社区维护的;
但是 STL 并没有明确的规定扩容的机制,所以不同平台是不一样的。
另外扩容也是有代价的,需要开新的空间,然后去释放旧的空间,那么有什么方法能够减少扩容呢?
这就需要我们的 reserve 函数了。
🍑 reserve
为字符串预留空间
void reserve (size_t n = 0);
假设我事先知道要插入 1000 个字符,那么我们可以使用 reserve 提前开好空间
int main()
{
string s;
s.reserve(1000); // 提前开好空间
size_t sz = s.capacity();
cout << "making s grow:" << endl;;
cout << "capacity changed:" << sz << endl;
for (int i = 0; i < 1000; ++i)
{
s.push_back('c');
if (sz != s.capacity())
{
sz = s.capacity();
cout << "capacity changed: " << sz << endl;;
}
}
return 0;
}
运行结果
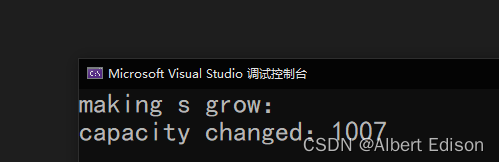
使用 reserve 改变当前对象的容量大小,并提前开空间:
1)当 n 大于对象当前的 capacity 时,将 capacity 扩大到 n 或大于 n。
2)当 n 小于对象当前的 capacity 时,什么也不做。
3)注意:此函数对字符串的 size 没有影响,并且无法更改其内容。
代码示例
void TestString8() {
string s("HelloWorld");
cout << s << endl; //HelloWorld
cout << s.size() << endl; //10
cout << s.capacity() << endl; //15
cout << endl;
//reverse(n)当n大于对象当前的capacity时,将当前对象的capacity扩大为n或大于n
s.reserve(20);
cout << s << endl; //HelloWorld
cout << s.size() << endl; //10
cout << s.capacity() << endl; //31
cout << endl;
//reverse(n)当n小于对象当前的capacity时,什么也不做
s.reserve(2);
cout << s << endl; //HelloWorld
cout << s.size() << endl; //4
cout << s.capacity() << endl; //31
}
运行结果
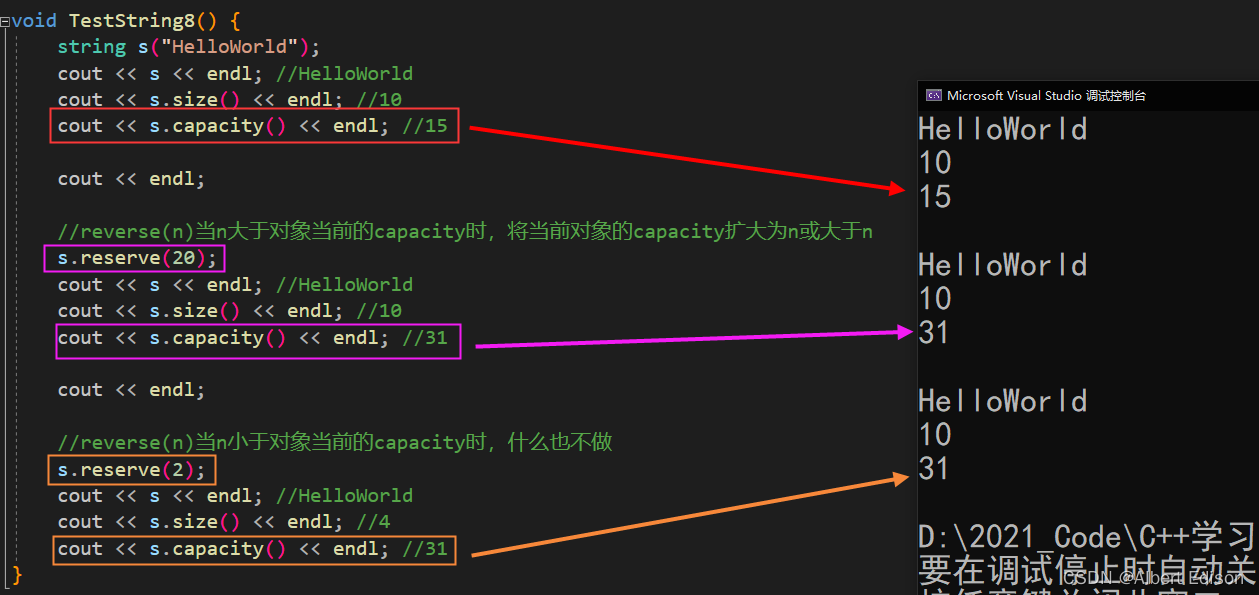
总结:
void reserve (size_t n = 0):为 string 预留空间,不改变有效元素个数,当 reserve 的参数小于 string 的底层空间总大小时,reserver 不会改变容量大小。
🍑 resize
将有效字符的个数改成 n 个,多出的空间用字符 c 填充
void resize (size_t n);void resize (size_t n, char c);
使用 resize 改变当前对象的有效字符的个数:
1)当 n 大于对象当前的 size 时,将 size 扩大到 n,扩大的字符为 c,若 c 未给出,则默认为 \0。
2)当 n 小于对象当前的 size 时,将 size 缩小到 n。
注意:若给出的 n 大于对象当前的 capacity,则 capacity 也会根据自己的增长规则进行扩大。
代码示例
void TestString8() {
string s1("HelloWorld");
//resize(n)n大于对象当前的size时,将size扩大到n,扩大的字符默认为'\0'
s1.resize(20);
cout << s1 << endl; //HelloWorld
cout << s1.size() << endl; //20
cout << s1.capacity() << endl; //31
cout << endl;
string s2("HelloWorld");
//resize(n, char)n大于对象当前的size时,将size扩大到n,扩大的字符为char
s2.resize(20, 'x');
cout << s2 << endl; //HelloWorldxxxxxxxxxxxxxxxx
cout << s2.size() << endl; //20
cout << s2.capacity() << endl; //31
cout << endl;
string s3("HelloWorld");
//resize(n)n小于对象当前的size时,将size缩小到n
s3.resize(2);
cout << s3 << endl; //He
cout << s3.size() << endl; //2
cout << s3.capacity() << endl; //15
}
运行结果
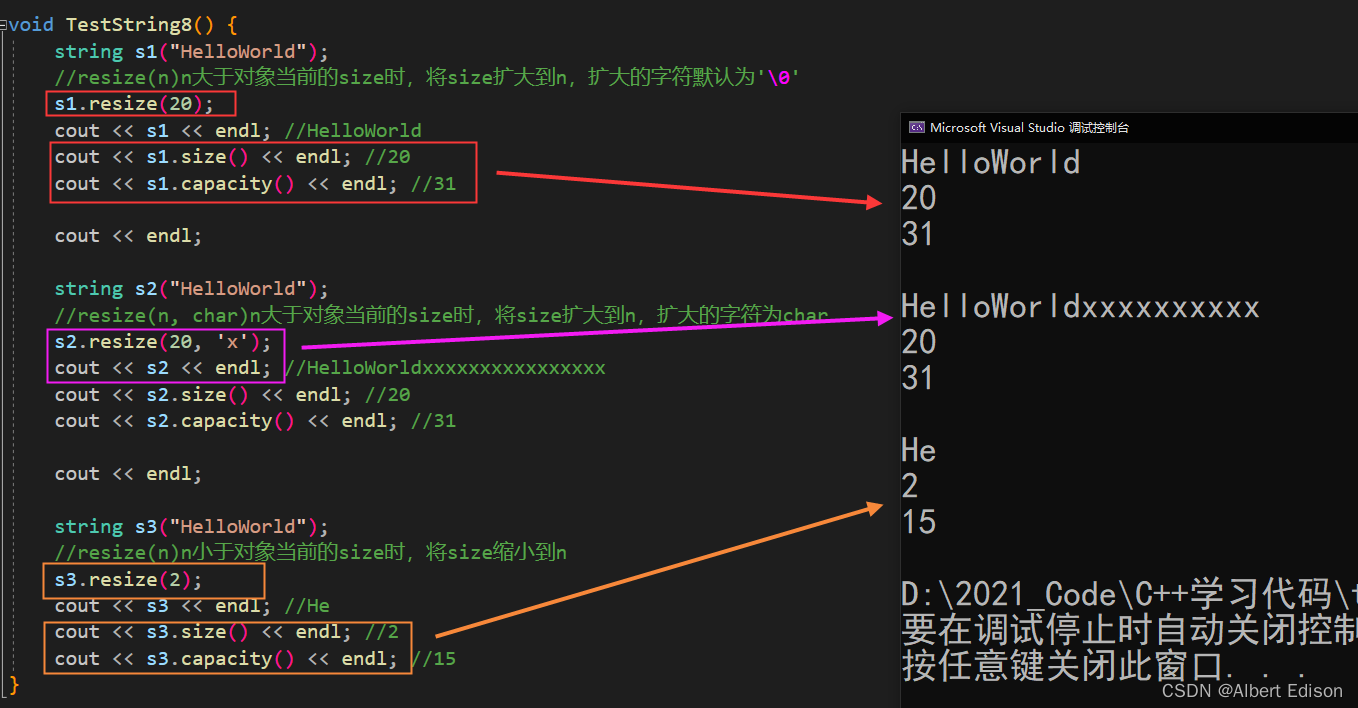
其实,reserve 的作用就是开空间,而 resize 是开空间+初始化。
关于 reserve 和 resize,它们在 VS 下都不会缩容量。
但是可以看到我们扩容的时候,明明是申请的 20 个空间,为什么打印出来有 31 个呢?这是因为 capacity 的内存对齐。
这里可以简单解释一下:系统去申请内存,需要按照整数倍去对齐的,就算我们不对齐,那么系统也会自动去对齐的;
假设我们申请了 99 个空间,但是系统一般不会给你 99 个,在一般情况下,会按照 2 的倍数去给你申请对齐。
为什么要申请对齐呢?是因为和内存的效率以及内存碎片有关。
🍑 clear
擦除字符串的内容,该字符串变为空字符串(长度为 0 个字符)。
使用 clear 删除对象的内容,删除后对象变为空字符串,但是对象的容量不会被清理掉
void clear();
代码示例
int main()
{
string s1("hello world");
cout << s1 << endl; //HelloWorld
cout << s1.size() << endl; //11
cout << s1.capacity() << endl; //15
cout << endl;
s1.clear();
cout << s1 << endl; //空
cout << s1.size() << endl; //0
cout << s1.capacity() << endl; //15
return 0;
}
运行结果
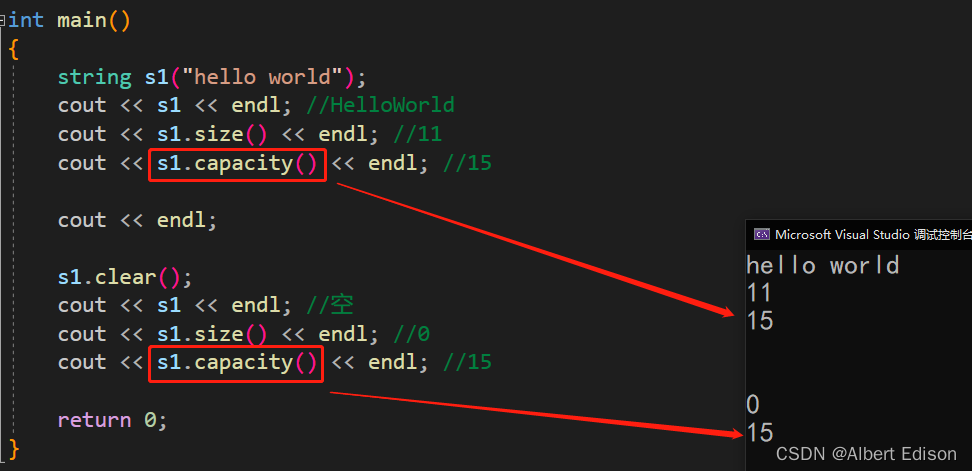
总结:clear 只是将 string 对象中有效字符清空,不改变底层空间大小。
🍑 empty
判断字符串是否为空
如果字符串长度为 0,则为 true,否则为 false。
bool empty() const;
代码示例
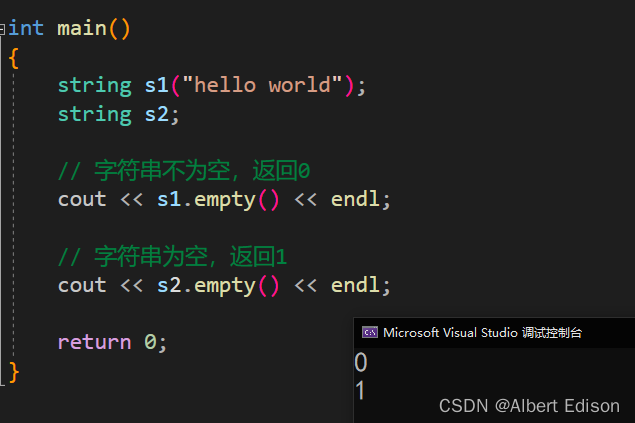
int main()
{
string s1("hello world");
string s2;
// 字符串不为空,返回0
cout << s1.empty() << endl;
// 字符串为空,返回1
cout << s2.empty() << endl;
return 0;
}
运行结果
🍑 总结
(1)size 与 length 方法底层实现原理完全相同,引入 size 的原因是为了与其他容器的接口保持一致,一般情况下基本都是用 size。
(2)clear 只是将 string 中有效字符清空,不改变底层空间大小。
(3)resize(size_t n) 与 resize(size_t n, char c) 都是将字符串中有效字符个数改变到 n 个,不同的是当字符个数增多时:resize(n) 用 0 来填充多出的元素空间,resize(size_t n, char c) 用字符 c 来填充多出的元素空间。
(4)resize 在改变元素个数时,如果是将元素个数增多,可能会改变底层容量的大小,如果是将元素个数减少,底层空间总大小不变。
(5)reserve(size_t res_arg=0) 为 string 预留空间,不改变有效元素个数,当 reserve 的参数小于 string 的底层空间总大小时,reserver 不会改变容量大小。
4. string类对象的访问及遍历操作
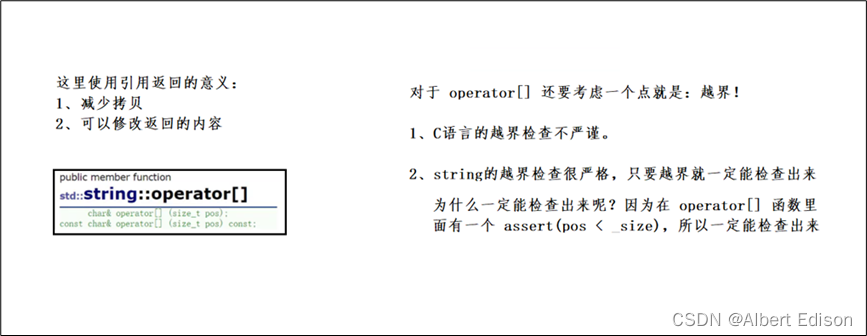
🍑 [ ] + 下标
string 类 对 [ ] 运算符进行了重载,所以我们可以直接使用 [ ]+下标 访问对象中的元素。
并且该重载使用的是 引用返回,所以我们可以通过 [ ]+下标 修改对应位置的元素。
char& operator[] (size_t pos);
const char& operator[] (size_t pos) const;
代码示例
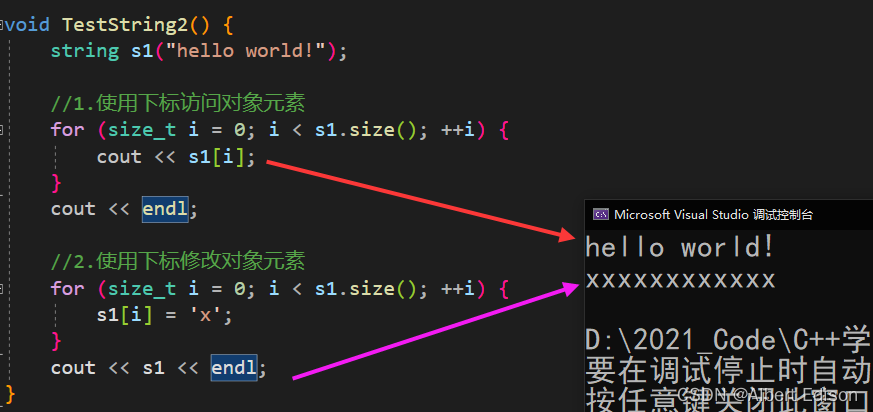
int main()
{
string s1("hello world!");
//1.使用下标访问对象元素
for (size_t i = 0; i < s1.size(); ++i) {
cout << s1[i];
}
cout << endl;
//2.使用下标修改对象元素
for (size_t i = 0; i < s1.size(); ++i) {
s1[i] = 'x';
}
cout << s1 << endl;
}
运行看一下结果
❗❗❗ 重点补充
思考一下,为什么重载了两个 [] 函数呢?
其实,对于 [] 的重载大约是按照下面这样来实现的
class string
{
public:
// 可读可写
char& operator[](size_t pos)
{
return _str[pos];
}
// 只读
const char& operator[](size_t pos) const
{
return _str[pos];
}
private:
char* _str;
size_t _size;
size_t _capacity;
};
int main()
{
string s1("hello");
cout << s1[0] << endl; // 读
s1[0] = 'x'; // 写
return 0;
}
s1 去调用 operator[],operator[] 返回的是 pos 这个位置字符的别名,也就是数组里面第 pos 个位置。
s1[0] 的意思是:我这里传给 pos 的值是 0,那就是第 0 个位置字符的别名,那这个 x 是赋给表达式返回值上的,这个表达式就是函数调用。
那如果我们定义了一个 const 类型的 string 对象呢?
int main()
{
string s1("hello");
const string s2("world");
s1[0] = 'x'; // 写
s2[0] = 'y'; // 编译会报错
return 0;
}
此时编译器会报错,因为 s2[0] 会去调用 const operator[],而 const 修饰的对象是只读的,所以这里属于权限的放大。
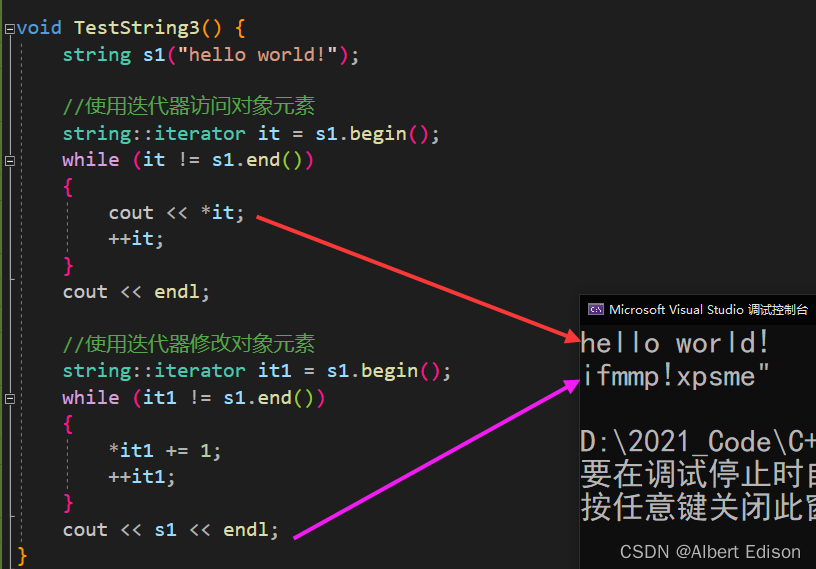
🍑 begin + end(迭代器)
begin 获取一个字符的迭代器 + end获取最后一个字符下一个位置的迭代器
代码示例
void TestString3() {
string s1("hello world!");
//使用迭代器访问对象元素
string::iterator it = s1.begin();
while (it != s1.end())
{
cout << *it;
++it;
}
cout << endl;
//使用迭代器修改对象元素
string::iterator it1 = s1.begin();
while (it1 != s1.end())
{
*it1 += 1;
++it1;
}
cout << s1 << endl;
}
运行看一下结果
对于迭代器,可以理解为像指针一样的东西,或者说就是指针。
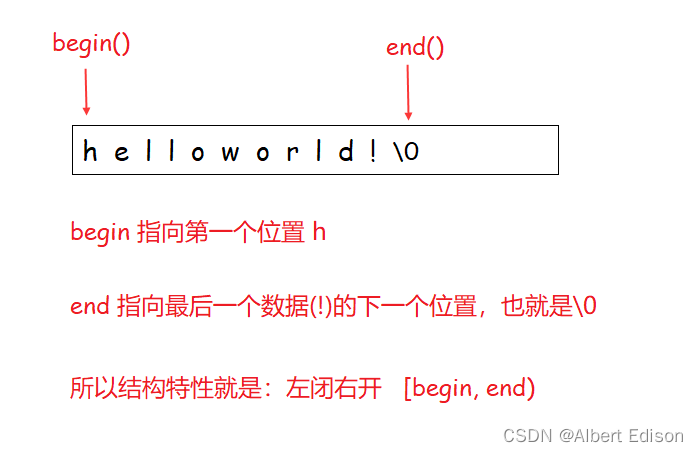
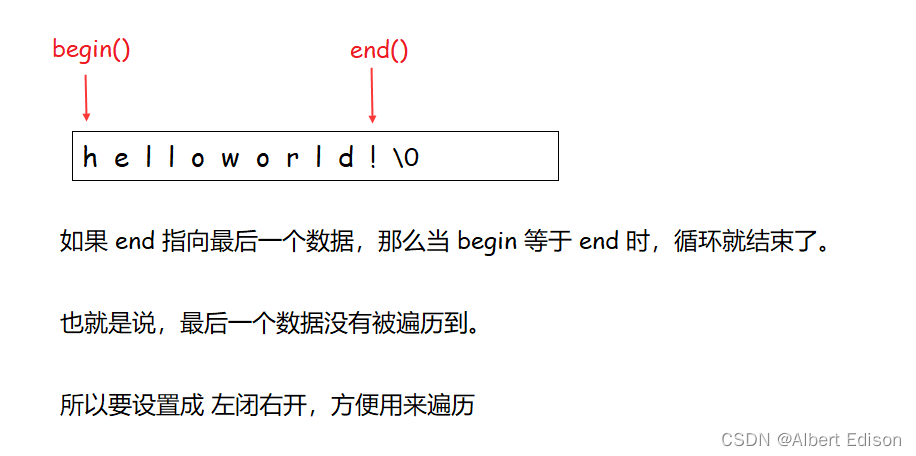
为什么是 左闭右开 呢?
🍑 范围for
使用范围 for 访问对象中的元素,它的原理就是被替换成了迭代器。
有一点要注意,如果我们是通过范围 for 来修改对象的元素,那么接收元素的变量 e 的类型必须是引用类型,否则 e 只是对象元素的拷贝,对 e 的修改不会影响到对象的元素。
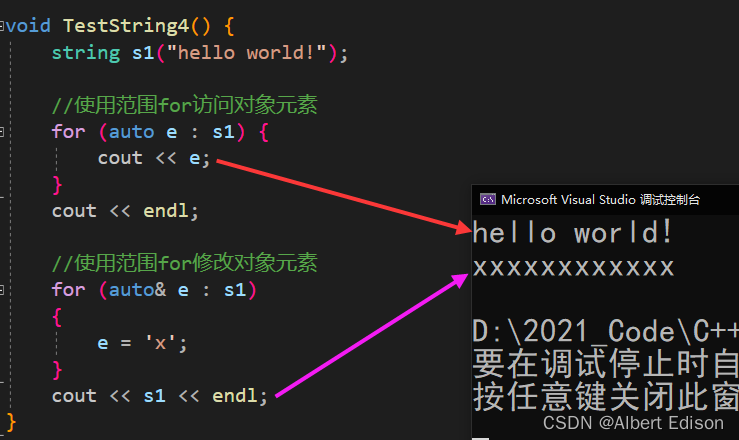
void TestString4() {
string s1("hello world!");
//使用范围for访问对象元素
for (auto e : s1) {
cout << e;
}
cout << endl;
//使用范围for修改对象元素
for (auto& e : s1)
{
e = 'x';
}
cout << s1 << endl;
}
运行看一下结果
我们可以看下范围 for 的汇编,其实底层就是拿迭代器实现的

🍑 at
因为 at 函数也是使用的引用返回,所以我们也可以通过 at 函数修改对应位置的元素。
char& at (size_t pos);const char& at (size_t pos) const;
代码示例
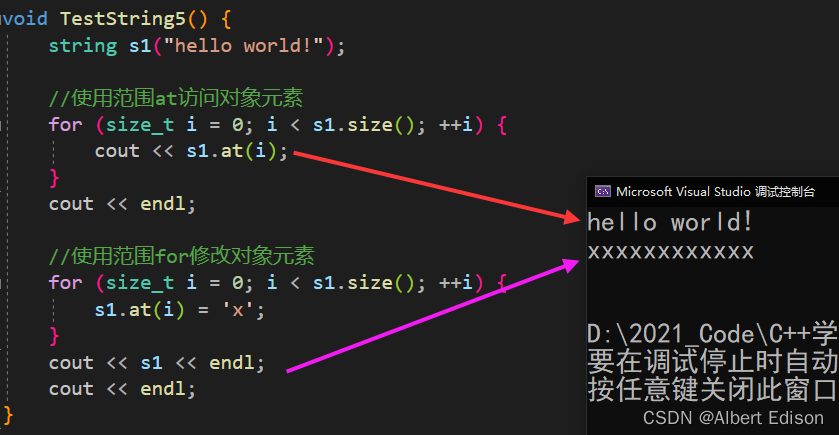
void TestString5() {
string s1("hello world!");
//使用范围at访问对象元素
for (size_t i = 0; i < s1.size(); ++i) {
cout << s1.at(i);
}
cout << endl;
//使用范围for修改对象元素
for (size_t i = 0; i < s1.size(); ++i) {
s1.at(i) = 'x';
}
cout << s1 << endl;
cout << endl;
}
运行看一下结果
🍑 at 和 [ ] 的区别
可以看到 at 和 operator[ ] 都是返回对字符串中位置位置的字符的引用。
那么它们的差异是什么呢?
那就是对于越界的检查不同!
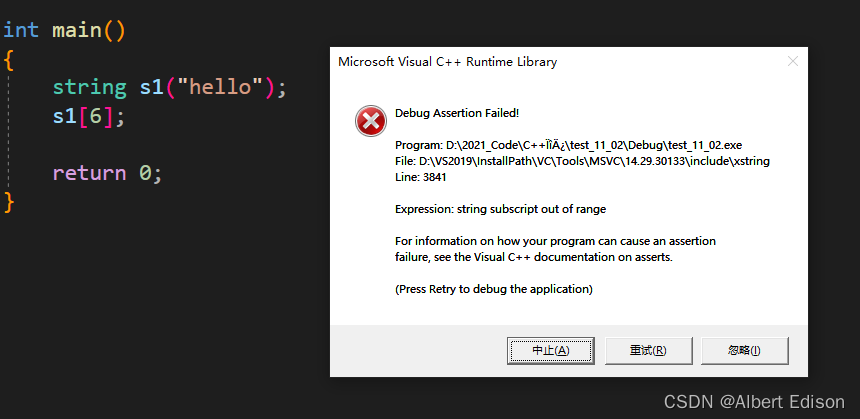
(1)operator[ ]
如果 pos 越界了,那么就会有一个断言的检查(断言是一种更加暴力的检查)
int main()
{
string s1("hello");
s1[6];
return 0;
}
运行结果:
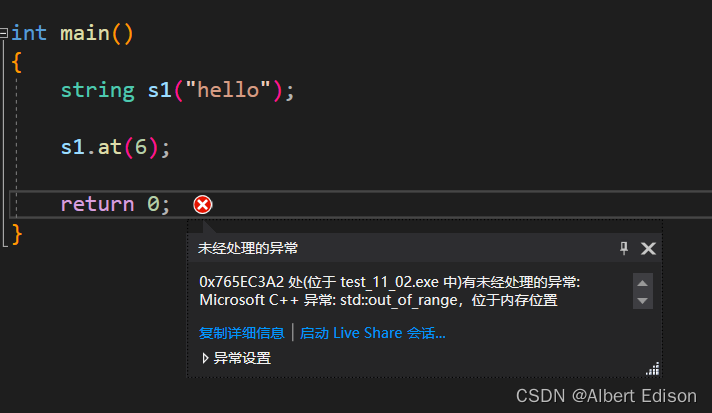
(1)at
at 对于越界的检查不会显得那么暴力,而是会给我们抛异常
int main()
{
string s1("hello");
s1.at(6);
return 0;
}
运行结果
那么对于抛出来的异常,我们可以进行捕获,并打印出错误的原因
void Testat() {
string s1("hello");
s1.at(6);
}
int main()
{
try
{
Testat();
}
catch (const exception& e) {
cout << e.what() << endl;
}
return 0;
}
运行结果
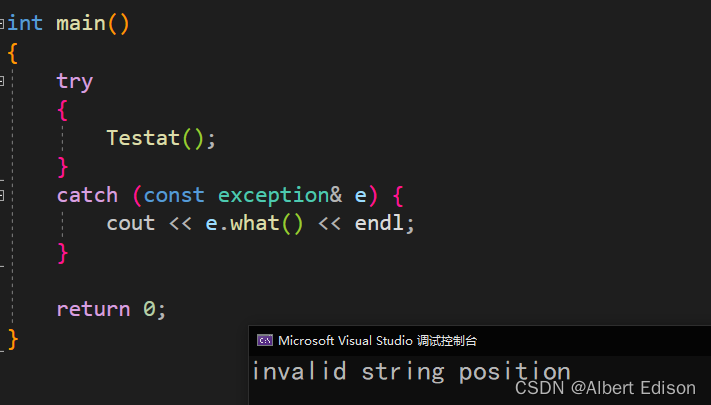
at 和 [] 虽然功能一样,但是它们处理错误的方式不同,并且 [] 用的更多一点。
5. string类对象的操作
对于对象的修改操作,主要可以分为:插入、拼接、删除、查找。
🍑 insert
insert 的接口有很多,实际上用的不多,我们挑几个来演示。

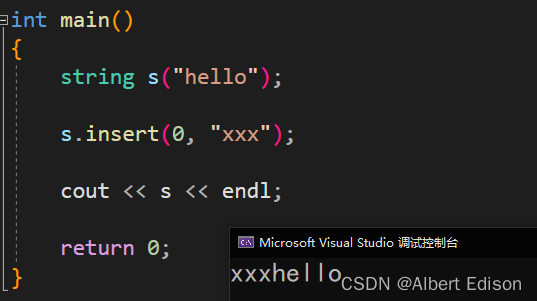
(1)在 pos 位置插入一个常量字符串
string& insert (size_t pos, const string& str);
代码示例
int main()
{
string s("hello");
// 在第0个位置插入字符串xxx
s.insert(0, "xxx");
cout << s << endl;
return 0;
}
运行结果
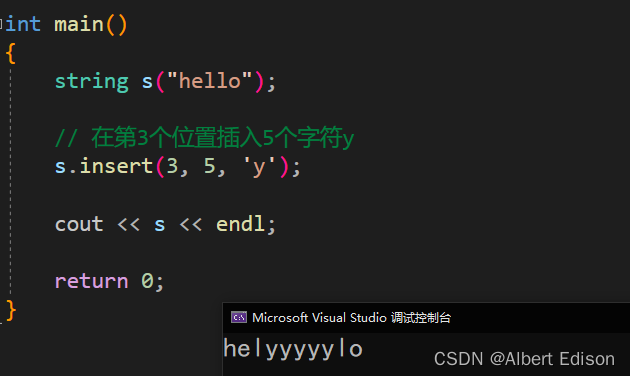
(2)在 pos 位置插入 n 个字符串 c
string& insert (size_t pos, size_t n, char c);
代码示例
int main()
{
string s("hello");
// 在第3个位置插入5个字符y
s.insert(3, 5, 'y');
cout << s << endl;
return 0;
}
运行结果
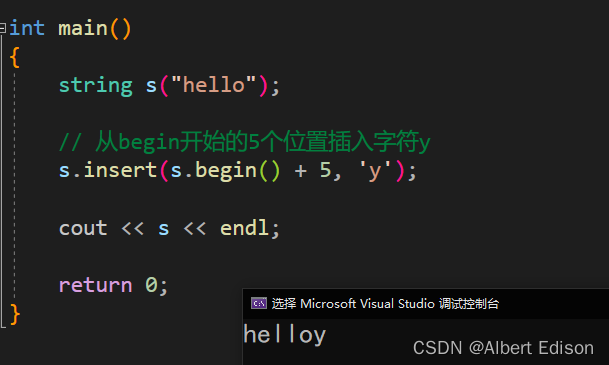
(3)使用迭代器来进行插入
iterator insert (iterator p, char c);
代码示例
int main()
{
string s("hello");
// 从begin开始的5个位置插入字符y
s.insert(s.begin() + 5, 'y');
cout << s << endl;
return 0;
}
运行结果
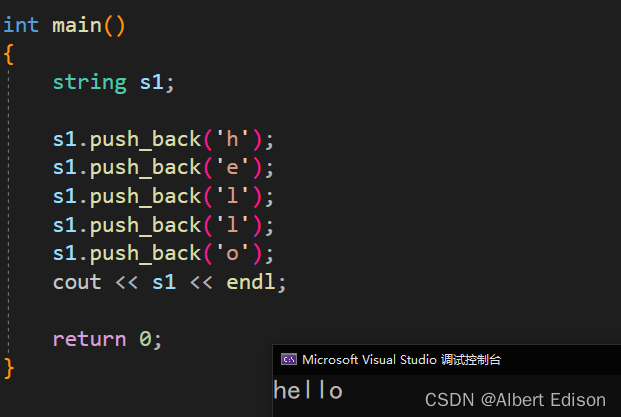
🍑 push_back
将字符 c 追加到字符串的末尾,将其长度增加 1。也就是尾插
void push_back (char c);
代码示例
int main()
{
string s1;
s1.push_back('h');
s1.push_back('e');
s1.push_back('l');
s1.push_back('l');
s1.push_back('o');
cout << s1 << endl;
return 0;
}
运行结果
🍑 append
在字符串后追加一个字符串,还是演示几个常用的。

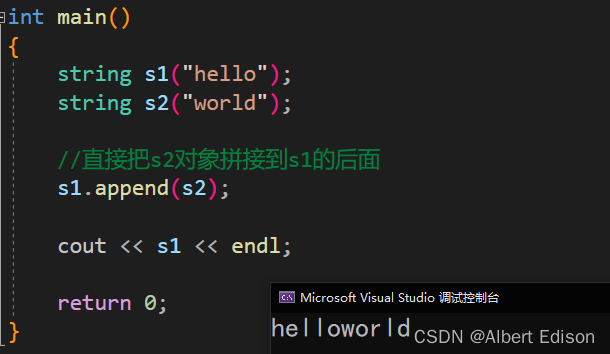
(1)插入一个 string 对象
string& append (const string& str);
代码示例
int main()
{
string s1("hello");
string s2("world");
//直接把s2对象拼接到s1的后面
s1.append(s2);
cout << s1 << endl;
return 0;
}
运行结果
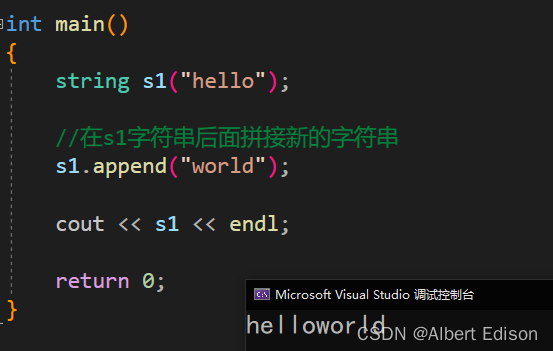
(2)插入一个常量字符串
string& append (const char* s);
代码示例
int main()
{
string s1("hello");
//在s1字符串后面拼接新的字符串
s1.append("world");
cout << s1 << endl;
return 0;
}
运行结果
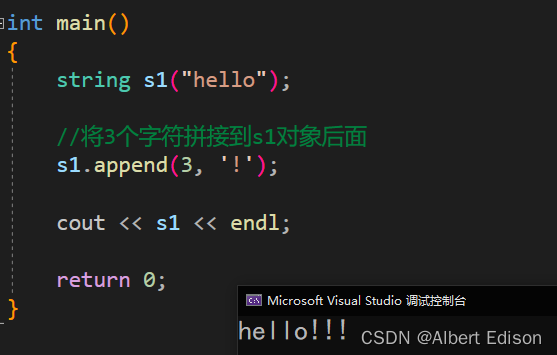
(3)插入 n 个字符 c
string& append (size_t n, char c);
代码示例
int main()
{
string s1("hello");
//将3个字符拼接到s1对象后面
s1.append(3, '!');
cout << s1 << endl;
return 0;
}
运行结果
🍑 operator+=
string 类中对 += 运算符进行了重载,重载后的 += 运算符支持 string 类的复合赋值、字符串的复合赋值以及字符复合的赋值。

(1)插入一个 string 对象
string& operator+= (const string& str);
代码示例
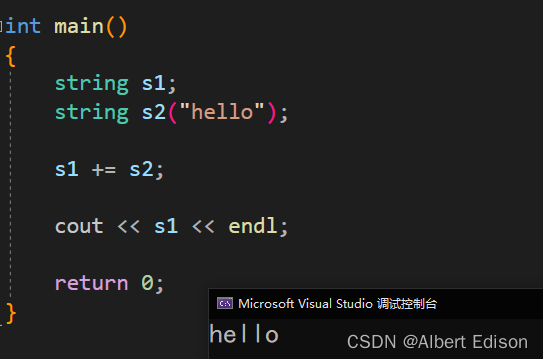
int main()
{
string s1;
string s2("hello");
s1 += s2;
cout << s1 << endl;
return 0;
}
运行结果
(2)插入一个常量字符串
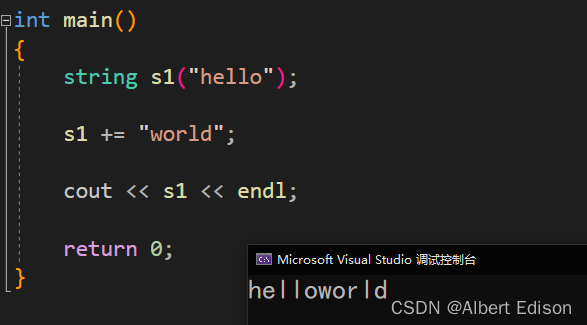
string& operator+= (const char* s);
代码示例
int main()
{
string s1("hello");
s1 += "world";
cout << s1 << endl;
return 0;
}
运行结果
(3)插入一个字符
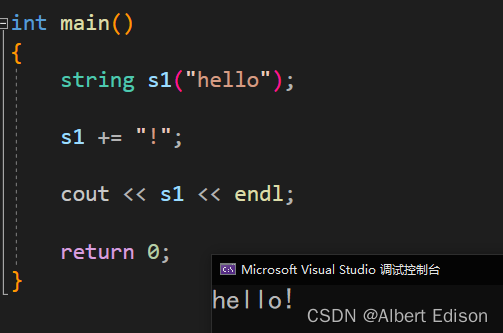
string& operator+= (char c);
代码示例
int main()
{
string s1("hello");
s1 += "!";
cout << s1 << endl;
return 0;
}
运行结果
总结
在 string 尾部追加字符时,s.push_back(c) 、 s.append(1, c) 、 s += 'c' 三种的实现方式差不多,一般情况下 string 类的 += 操作用的比较多,+= 操作不仅可以连接单个字符,还可以连接字符串。
另外,对 string 操作时,如果能够大概预估到放多少字符,可以先通过 reserve 把空间预留好。
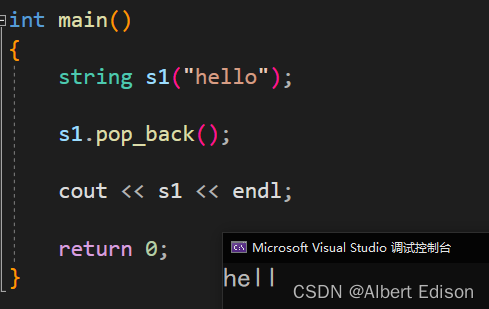
🍑 pop_back
删除最后一个字符
void pop_back();
代码示例
int main()
{
string s1("hello");
s1.pop_back();
cout << s1 << endl;
return 0;
}
运行结果
🍑 erase
从字符串中删除字符

(1)从 pos 位置开始,删除 len 个字符
这里的 len 是给了缺省值 npos 的。
string& erase (size_t pos = 0, size_t len = npos);
代码示例
int main()
{
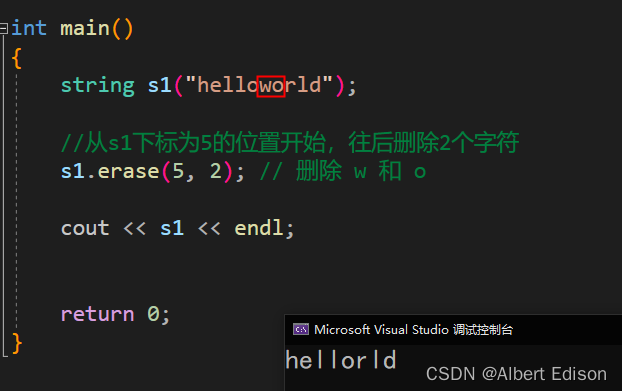
string s1("helloworld");
//从s1下标为5的位置开始,往后删除2个字符
s1.erase(5, 2); // 删除 w 和 o
cout << s1 << endl;
return 0;
}
运行结果
(2)从迭代器的位置删除字符
iterator erase (iterator p);
代码示例
int main()
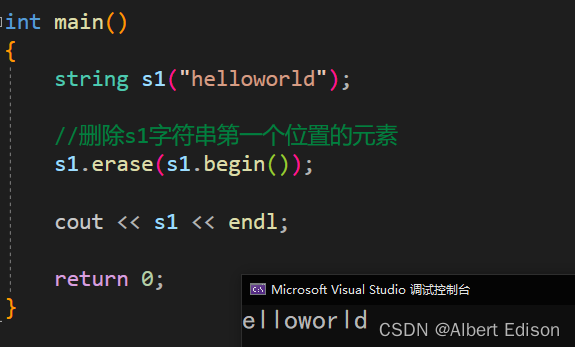
{
string s1("helloworld");
//删除s1字符串第一个位置的元素
s1.erase(s1.begin());
cout << s1 << endl;
return 0;
}
运行结果
(3)从迭代器开始的位置,一直删除到迭代器结束的位置
iterator erase (iterator first, iterator last);
代码示例
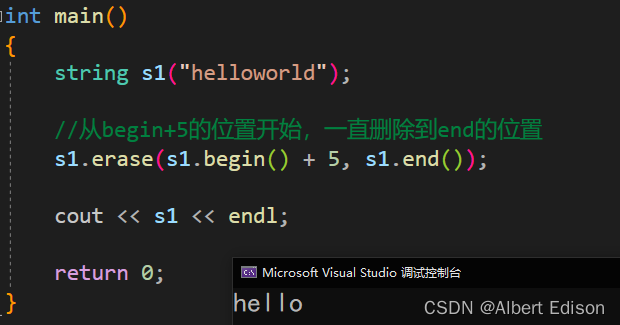
int main()
{
string s1("helloworld");
//从begin+5的位置开始,一直删除到end的位置
s1.erase(s1.begin() + 5, s1.end());
cout << s1 << endl;
return 0;
}
运行结果
🍑 replace
替换字符串的一部分。
将字符串中从字符 pos 开始并跨越 len 字符的部分替换为新内容。
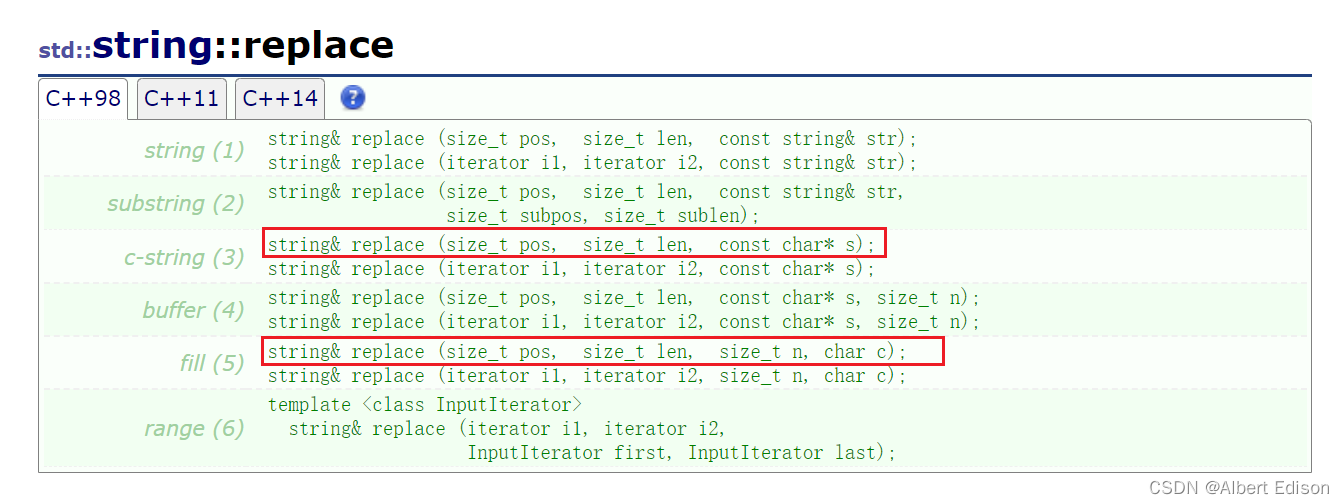
(1)从 pos 位置开始的第 len 个字符替换为一个字符串
string& replace (size_t pos, size_t len, const char* s);
代码示例
int main()
{
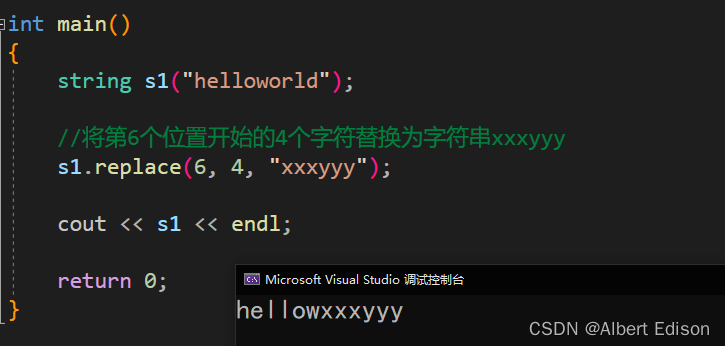
string s1("helloworld");
//将第6个位置开始的4个字符替换为字符串xxxyyy
s1.replace(6, 4, "xxxyyy");
cout << s1 << endl;
return 0;
}
运行结果
(2)从 pos 位置开始的第 len 个字符替换为 n 个字符 c
string& replace (size_t pos, size_t len, size_t n, char c);
代码示例
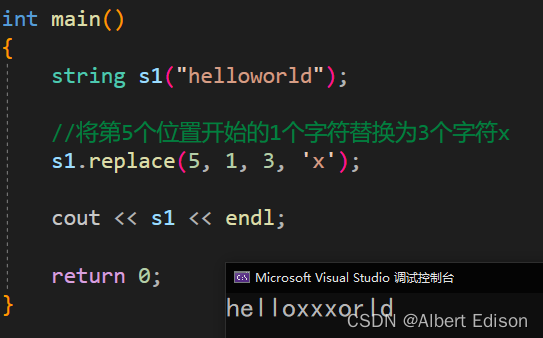
int main()
{
string s1("helloworld");
//将第5个位置开始的1个字符替换为3个字符x
s1.replace(5, 1, 3, 'x');
cout << s1 << endl;
return 0;
}
运行结果
🍑 swap
交换 string 类对象的字符串值
void swap (string& str);
代码示例
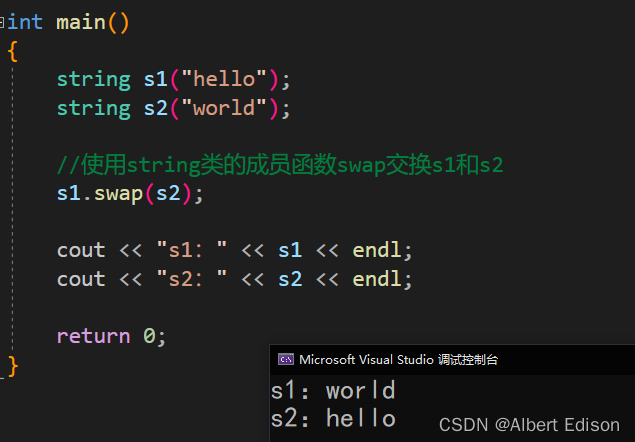
int main()
{
string s1("hello");
string s2("world");
//使用string类的成员函数swap交换s1和s2
s1.swap(s2);
cout << "s1:" << s1 << endl;
cout << "s2:" << s2 << endl;
return 0;
}
运行结果
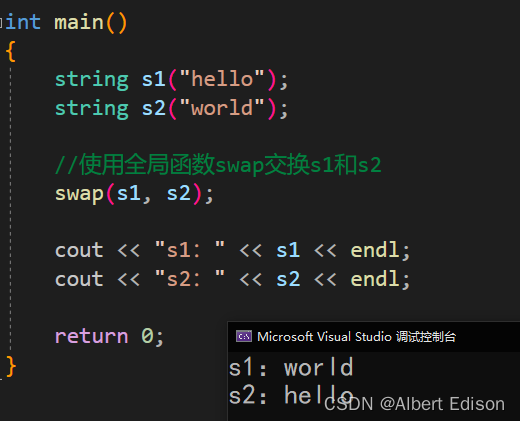
在我们的全局范围内也有个 swap 函数
int main()
{
string s1("hello");
string s2("world");
//使用全局函数swap交换s1和s2
swap(s1, s2);
cout << "s1:" << s1 << endl;
cout << "s2:" << s2 << endl;
return 0;
}
运行结果
可以看到它们都实现了交换,那么这两个的区别是什么呢?
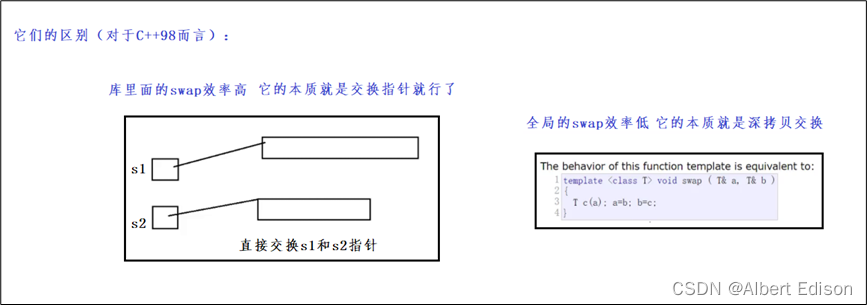
🍑 compare
使用 compare 函数完成比较。
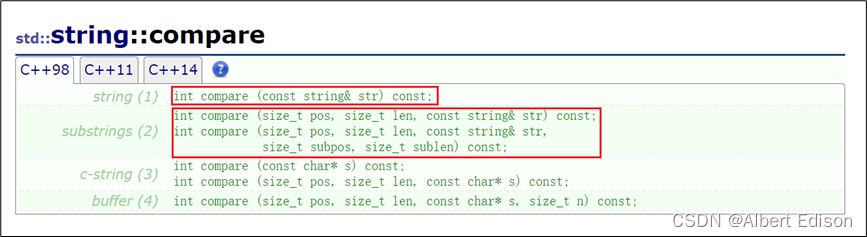
compare 的比较规则
-
比较字符串中第一个不匹配的字符值较小,或者所有比较字符都匹配,但比较字符串较短,则返回小于 0 的值。
-
比较字符串中第一个不匹配的字符值较大,或者所有比较字符都匹配,但比较字符串较长,则返回大于 0 的值。
-
比较的两个字符串相等,则返回 0。
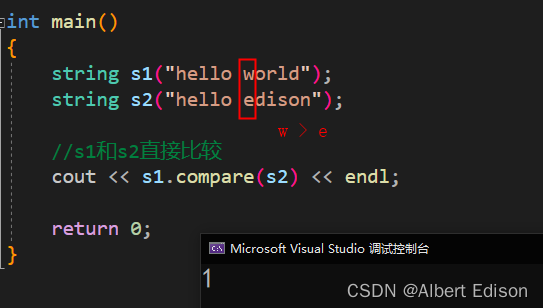
(1)两个对象直接比较
int main()
{
string s1("hello world");
string s2("hello edison");
//s1和s2直接比较
cout << s1.compare(s2) << endl;
return 0;
}
运行结果
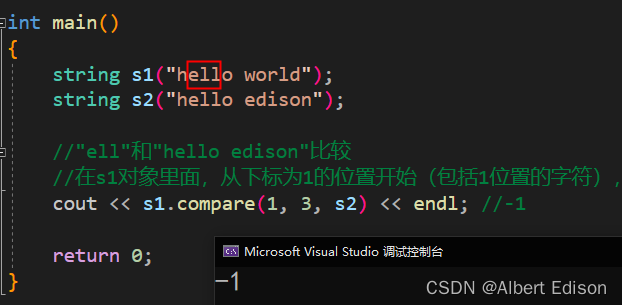
(2)在 s1 对象里面,从下标为 1 的位置开始(包括 1 位置的字符),往后数 3 个字符,然后与 s2 对象进行比较
代码示例
int main()
{
string s1("hello world");
string s2("hello edison");
//"ell"和"hello edison"比较
cout << s1.compare(1, 3, s2) << endl; //-1
return 0;
}
运行结果
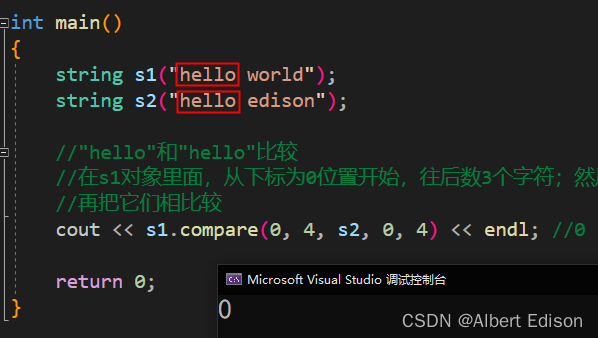
(3)在 s1 对象里面,从下标为 0 位置开始,往后数 3 个字符;然后在 s2 对象里面,从下标为 0 的位置,往后数 3 个字符;然后再开始比较
代码示例
int main()
{
string s1("hello world");
string s2("hello edison");
//"hello"和"hello"比较
//在s1对象里面,从下标为0位置开始,往后数3个字符;然后在s2对象里面,从下标为0的位置,往后数3个字符;
//再把它们相比较
cout << s1.compare(0, 4, s2, 0, 4) << endl; //0
return 0;
}
运行结果
除了支持 string 类之间进行比较,compare 函数还支持 string 类和字符串进行比较。
🍑 find
使用 find 函数正向搜索第一个匹配项(演示几个常用的)
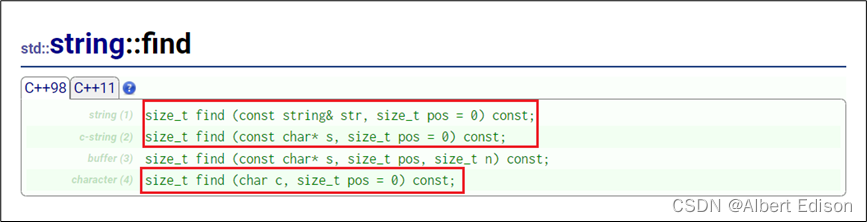
(1)在 s1 字符串里面,正向搜索与 s2 对象所匹配的字符串,并返回第一次出现的位置
代码示例
int main()
{
string s1("https://www.cplusplus.com/reference/string/string/find/");
string s2("www");
size_t pos1 = s1.find(s2);
cout << pos1 << endl; //8
return 0;
}
运行结果
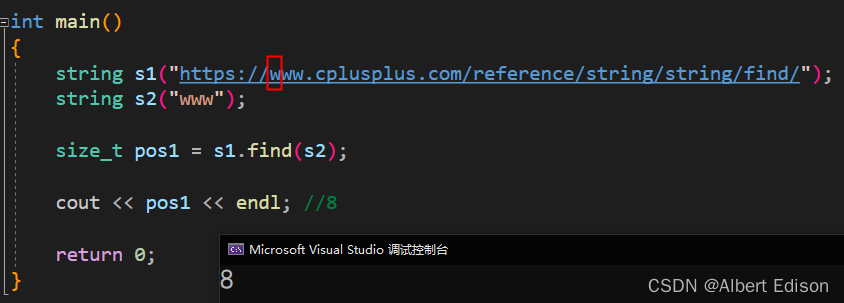
(2)在 s1 字符串里面,正向搜索与字符串 str 所匹配的第一个位置
代码示例
int main()
{
string s1("https://www.cplusplus.com/reference/string/string/find/");
char str[] = "cplusplus.com";
size_t pos2 = s1.find(str);
cout << pos2 << endl; //12
return 0;
}
运行结果
(3)在 s1 字符串里面,正向搜索与字符 char 所匹配的第一个位置
代码示例
int main()
{
string s1("https://www.cplusplus.com/reference/string/string/find/");
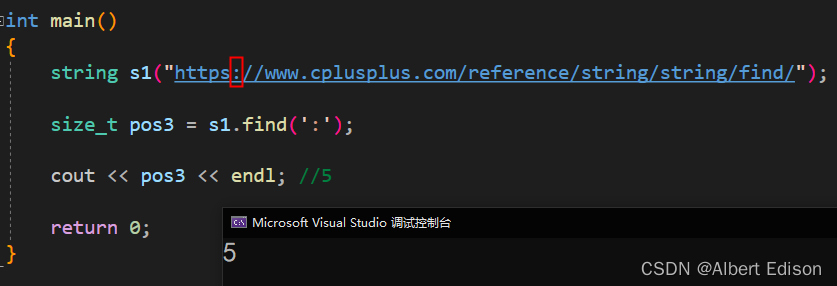
size_t pos3 = s1.find(':');
cout << pos3 << endl; //5
return 0;
}
运行结果
🍑 rfind
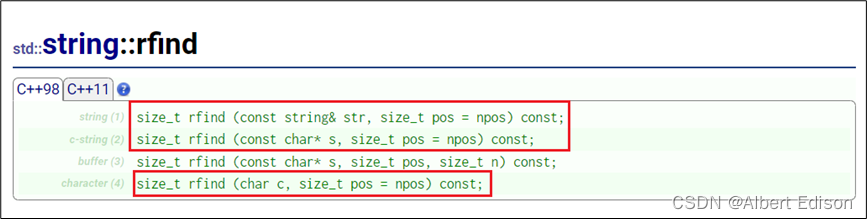
使用 rfind 函数反向搜索第一个匹配项。
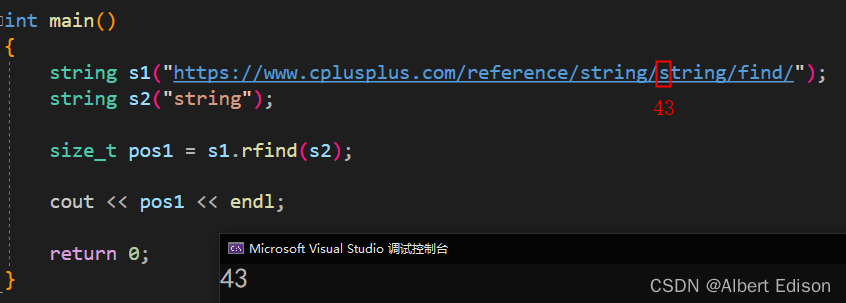
(1)在 s1 字符串里面,反向搜索与 s2 对象所匹配的字符串,并返回第一次出现的位置
代码示例
int main()
{
string s1("https://www.cplusplus.com/reference/string/string/find/");
string s2("string");
size_t pos1 = s1.rfind(s2);
cout << pos1 << endl;
return 0;
}
运行结果
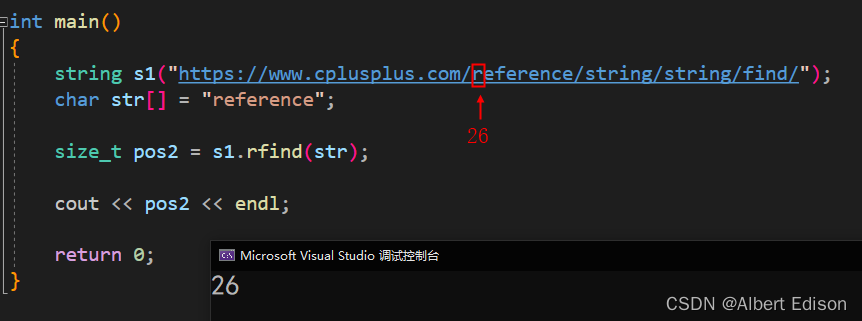
(2)在 s1 字符串里面,反向搜索与字符串 str 所匹配的第一个位置
代码示例
int main()
{
string s1("https://www.cplusplus.com/reference/string/string/find/");
char str[] = "reference";
size_t pos2 = s1.rfind(str);
cout << pos2 << endl;
return 0;
}
运行结果
(3)在 s1 字符串里面,反向搜索与字符 char 所匹配的第一个位置
代码示例
int main()
{
string s1("https://www.cplusplus.com/reference/string/string/find/");
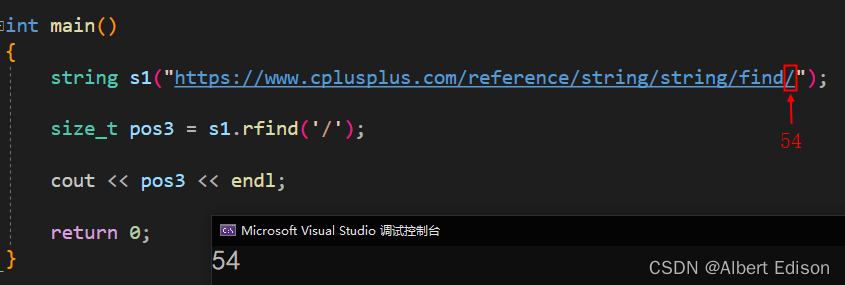
size_t pos3 = s1.rfind('/');
cout << pos3 << endl;
return 0;
}
运行结果
6. string类运算符函数
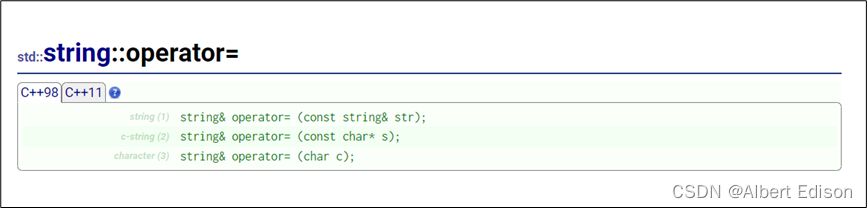
🍑 operator=
string 类中对 = 运算符进行了重载,重载后的 = 运算符支持 string 类的赋值、字符串的赋值以及字符的赋值。
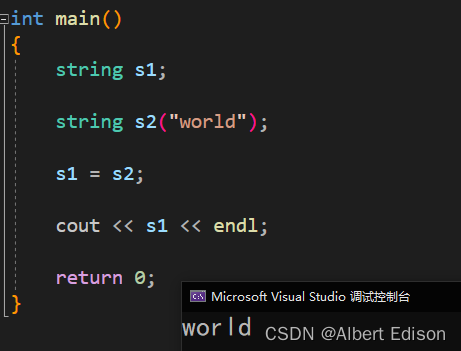
(1)支持 string 类对象的赋值
代码示例
int main()
{
string s1;
string s2("world");
s1 = s2;
cout << s1 << endl;
return 0;
}
运行结果
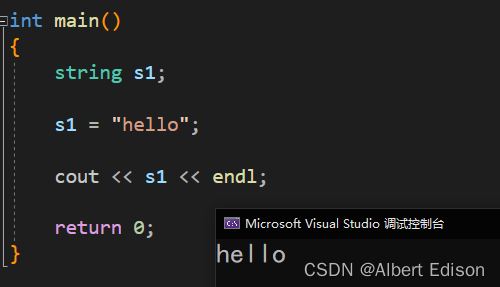
(2)支持字符串的赋值
代码示例
int main()
{
string s1;
s1 = "hello";
cout << s1 << endl;
return 0;
}
运行结果
(2)支持字符的赋值
代码示例
int main()
{
string s1;
s1 = 'x';
cout << s1 << endl;
return 0;
}
运行结果

🍑 operator+=
上面 string 类对象的插入已经讲过了,这里不过多阐述。
🍑 operator+
string 类中对 + 运算符进行了重载
重载后的 + 运算符支持以下几种类型的操作,它们相加后均返回一个 string 类对象。
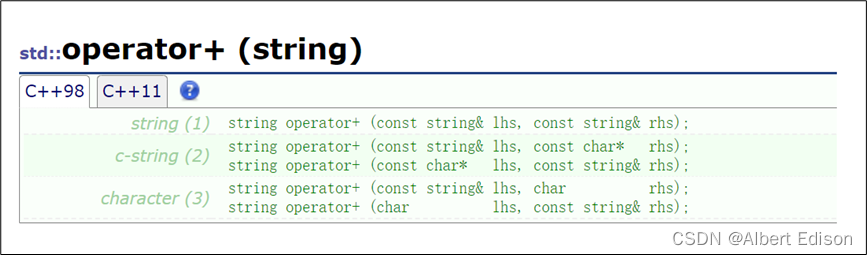
(1)string 类 + string 类
代码示例
int main()
{
string s1;
string s2("Captain");
string s3("Chinese");
s1 = s2 + s3;
cout << s1 << endl;
return 0;
}
运行结果
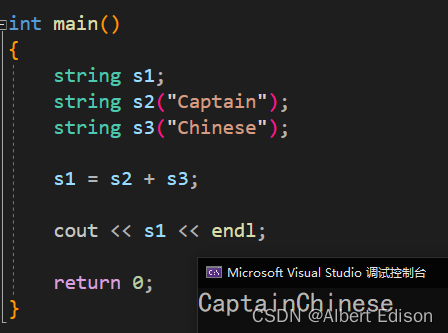
(2)string 类 + 字符串
代码示例
int main()
{
string s1;
string s2("Captain");
char str[] = "America";
s1 = s2 + str;
cout << s1 << endl;
return 0;
}
运行结果
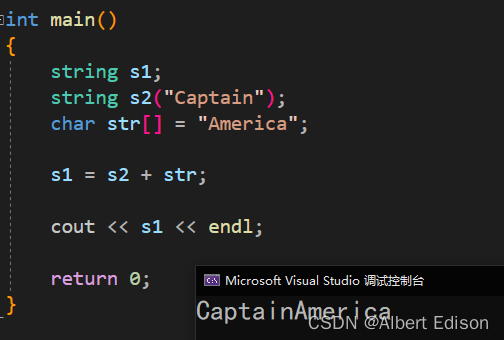
(3)字符串 + string 类
代码示例
int main()
{
string s1;
string s2("Captain");
char str[] = "America";
s1 = str + s2;
cout << s1 << endl;
return 0;
}
运行结果
(4)string 类 + 字符
代码示例
int main()
{
string s1;
string s2("Captain");
char ch = '!';
s1 = s2 + ch;
cout << s1 << endl;
return 0;
}
运行结果

(5)字符 + string 类
代码示例
int main()
{
string s1;
string s2("Captain");
char ch = '!';
s1 = ch + s2;
cout << s1 << endl;
return 0;
}
运行结果
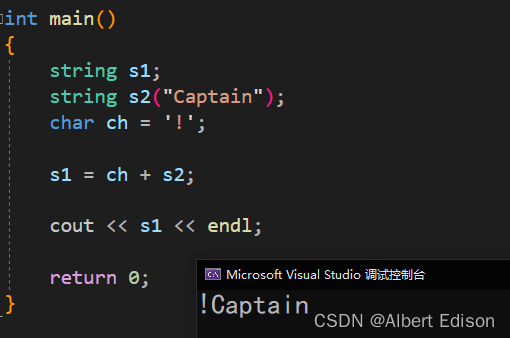
注意:这里的 operator+ 尽量少用,因为传值返回,导致深拷贝效率低。
🍑 operator >> 和 operator <<
string 类中也对 >> 和 << 运算符进行了重载,所以我们可以直接使用 cin 和 cout 对 string 类进行输入和输出。

代码示例
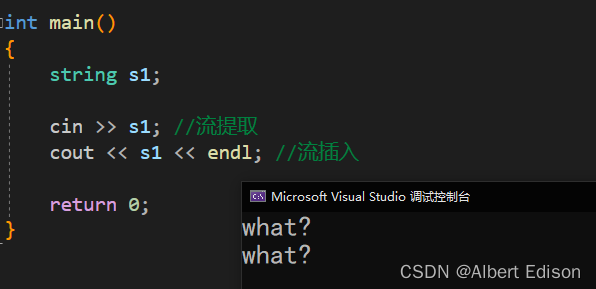
int main()
{
string s1;
cin >> s1; //流提取
cout << s1 << endl; //流插入
return 0;
}
运行结果
🍑 relational operators
string 类中还对一系列关系运算符进行了重载,它们分别是 ==、!=、<、<=、>、>=。
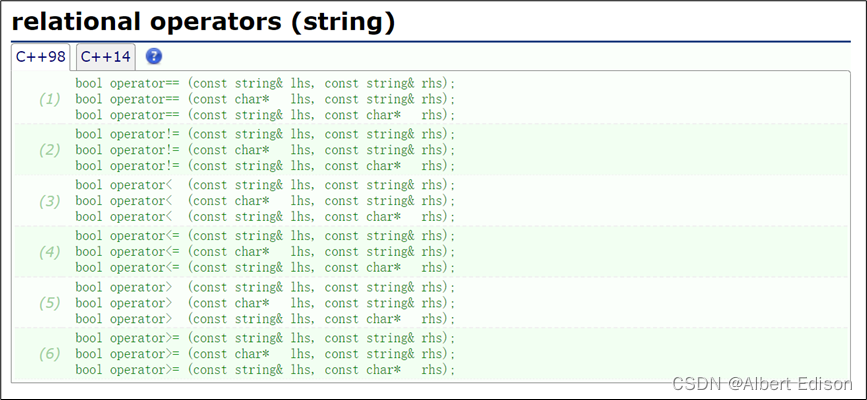
重载后的关系运算符支持:string 类和 string 类之间的关系比较、string 类和字符串之间的关系比较、字符串和 string 类之间的关系比较。
代码示例
int main()
{
string s1("abcd");
string s2("abde");
cout << (s1 > s2) << endl;
cout << (s1 < s2) << endl;
cout << (s1 == s2) << endl;
return 0;
}
运行结果

注意:这些重载的关系比较运算符所比较的都是对应字符的 ASCII 码值。
7. string类中的迭代器
迭代器严格来说分为 4 种,分别是:
-
正向迭代器
-
反向迭代器
-
const 正向迭代器
-
const 反向迭代器
🍑 正向迭代器
(1)begin 函数
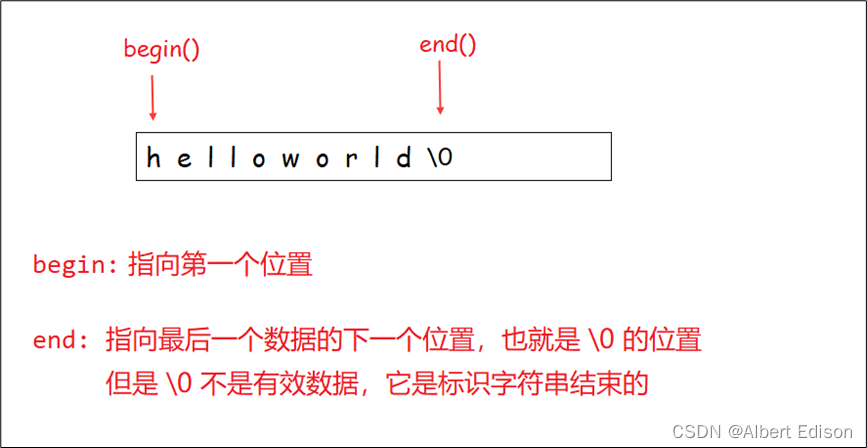
返回一个指向字符串第一个字符的迭代器。

(2)end 函数
返回一个指向字符串结束字符的迭代器,即 \0。
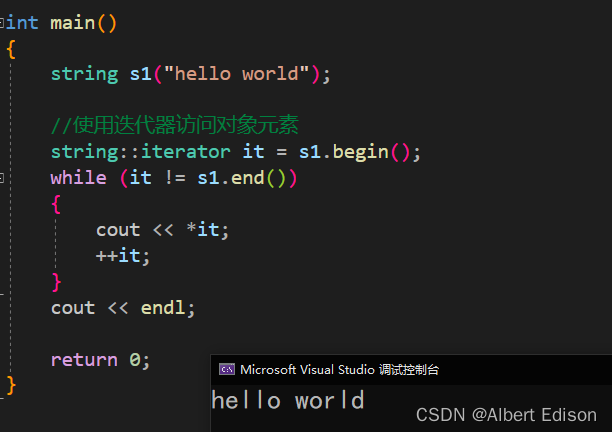
代码示例
int main()
{
string s1("hello world");
//使用迭代器访问对象元素
string::iterator it = s1.begin();
while (it != s1.end())
{
cout << *it;
++it;
}
cout << endl;
return 0;
}
运行结果
那么正向迭代器是如何实现的呢?
🍑 反向迭代器
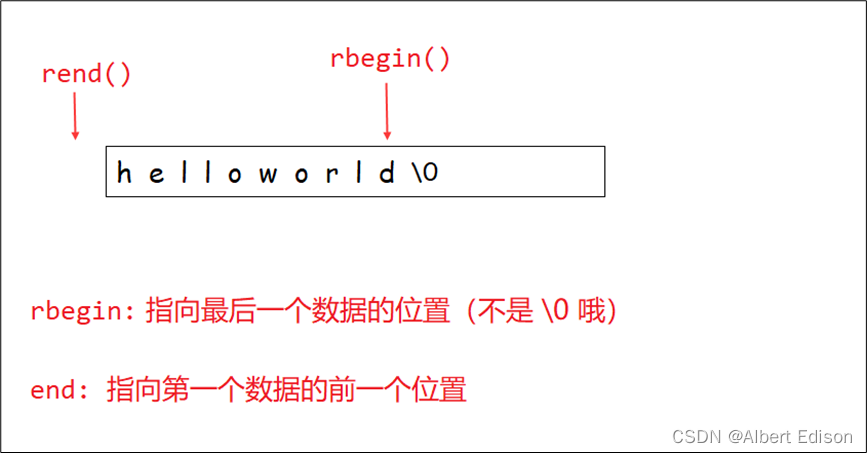
(1)rbegin 函数
返回指向字符串最后一个字符的反向迭代器。

(2)rend 函数
返回指向字符串第一个字符前面的理论元素的反向迭代器。

代码示例
int main()
{
string s1("hello world");
//使用反向迭代器访问对象元素
string::reverse_iterator rit = s1.rbegin();
while (rit != s1.rend())
{
cout << *rit;
++rit;
}
cout << endl;
return 0;
}
运行结果:
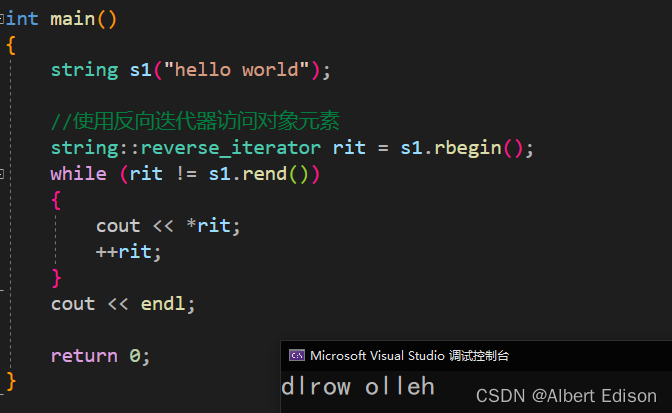
那么反向迭代器是如何实现的呢?
🍑 const 迭代器
我们知道,普通的 正向 和 反向 迭代器是 可读可写 的!但是也不排除特殊情况!
假设我是一个 const 类型的对象呢?还能用上面的方法访问吗?
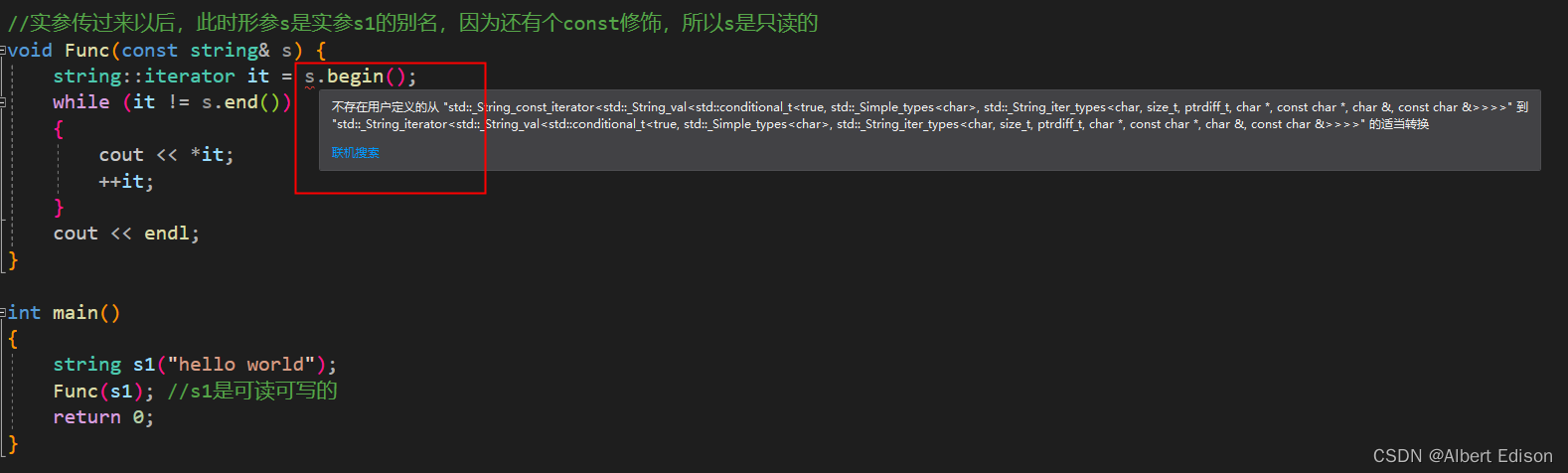
答案是肯定不能的,那么此时就要引出我们的 const 迭代器!

此时我们可以重新对代码进行修改,发现就可以进行读了(注意,此时是不能对元素进行修改的)
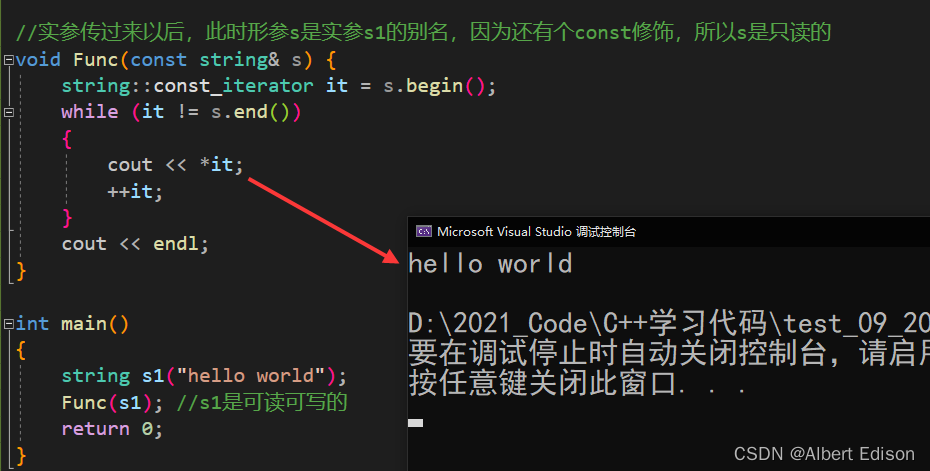
const 反向迭代器同理,我们也可以看下:
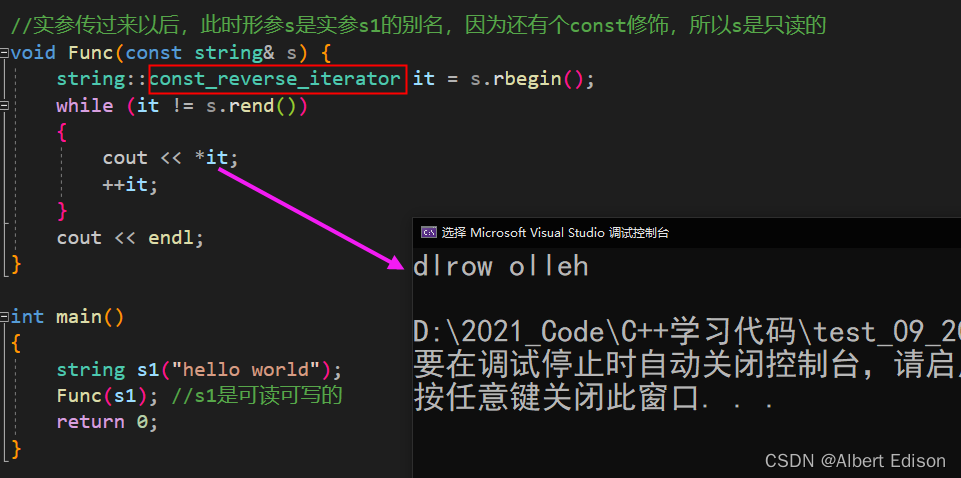
🍑 总结
迭代器分为 4 种,可以归为两类:
- 正向迭代器 && const 正向迭代器
- 反向迭代器 && const 反向迭代器
普通的正向和反向迭代器是 可读可写 的。
const 修饰的正向和反向迭代器是 只读 的。
8. string类非成员函数
🍑 将字符串转换为 string
将字符串转换为 string 很简单,在前面讲 string 的定义方式时就有说到。
代码示例
int main()
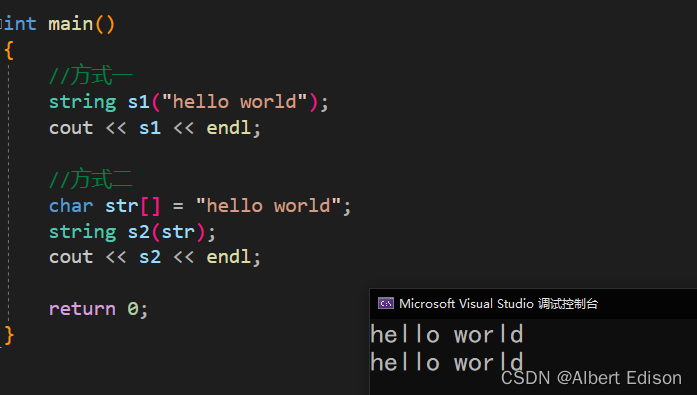
{
//方式一
string s1("hello world");
cout << s1 << endl;
//方式二
char str[] = "hello world";
string s2(str);
cout << s2 << endl;
return 0;
}
运行结果
🍑 将 string 转换为字符串
可以使用 c_str 或 data 将 string 转换为字符串

c_str 和 data 的区别:
-
在 C++98 中,
c_str()返回const char*类型,返回的字符串 会 以空字符结尾。 -
在 C++98 中,
data()返回const char*类型,返回的字符串 不会 以空字符结尾。
注意:但是在 C++11 版本中,c_str() 与 data() 用法相同。
代码示例
int main()
{
string s("hello world");
const char* str1 = s.data();
cout << str1 << endl;
const char* str2 = s.c_str();
cout << str2 << endl;
return 0;
}
运行结果

🍑 string中子字符串的提取
(1)使用 substr 函数提取 string 中的子字符串
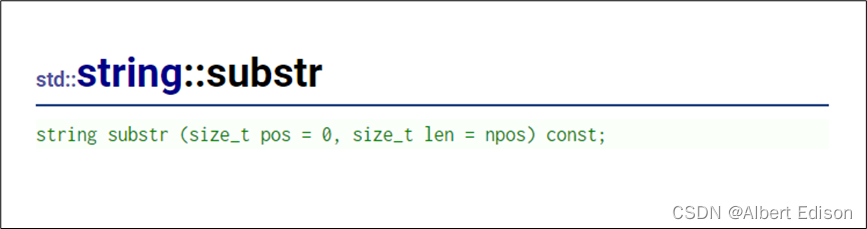
代码示例
int main()
{
string s1("My tea's gone cold, I'm wondering why I got out of bed at all");
string s2;
// substr(pos, n)
// 提取pos位置开始的n个字符序列作为返回值
s2 = s1.substr(3, 5);
cout << s2 << endl;
return 0;
}
运行结果
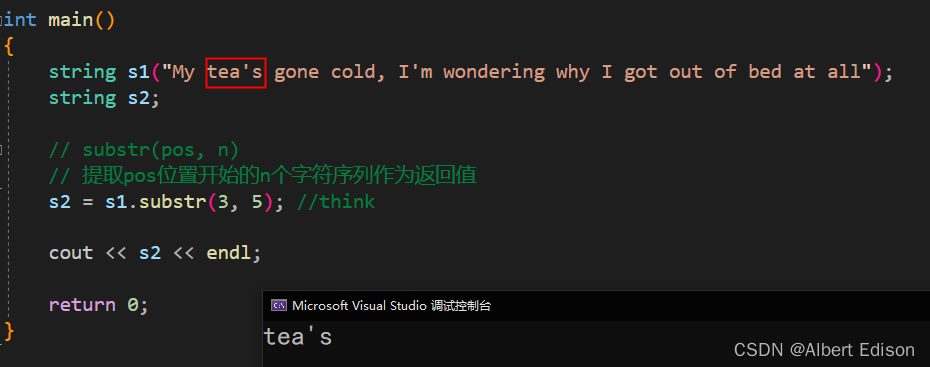
一般来说,substr 可以和 find 配合使用。
比如,我要取出 string.cpp 这个文件的后缀 .cpp
int main()
{
string file("string.cpp");
size_t pos = file.find('.');
if (pos != string::npos) {
string suffix = file.substr(pos, file.size() - pos);
cout << suffix << endl;
}
else {
cout << "没有后缀" << endl;
}
return 0;
}
运行结果
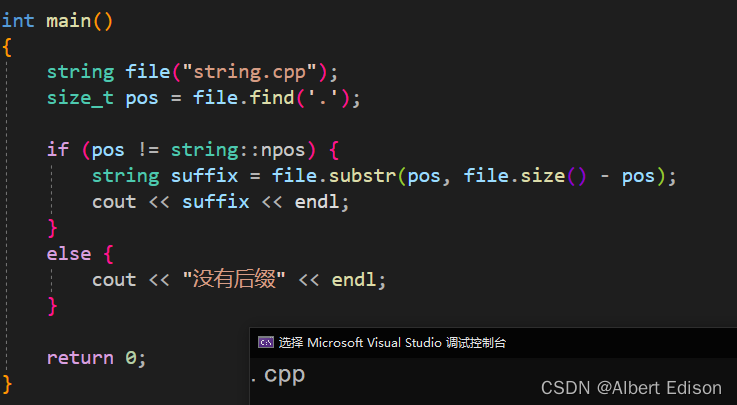
但是上面这种写法会存在一个问题,假设我的文件是:string.c.tar.zip,那么用上面方法的话,就全部取出来了呀,哪还有什么办法吗?
很简单,我们可以使用 rfind 倒着从后面找
int main()
{
string file("string.c.tar.zip");
size_t pos = file.rfind('.');
if (pos != string::npos) {
string suffix = file.substr(pos);
cout << suffix << endl;
}
else {
cout << "没有后缀" << endl;
}
return 0;
}
运行结果
(2)使用 copy 函数将 string 的子字符串复制到字符数组中
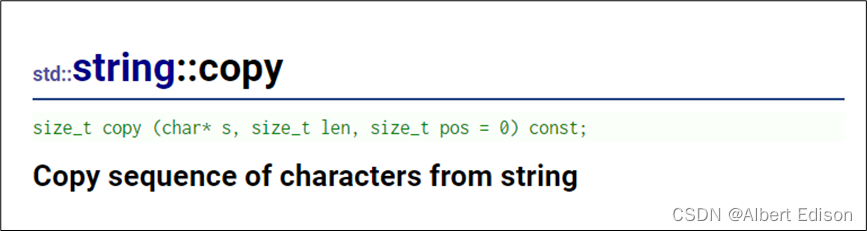
代码示例
int main()
{
string s1("Test string...");
char str[20];
// copy(str, n, pos)
// 复制pos位置开始的n个字符到str字符串
// 复制下标为5位置开始的6个字符到str种
size_t length = s1.copy(str, 6, 5);
//copy函数不会在复制内容的末尾附加'\0',需要手动加
str[length] = '\0';
//打印
cout << str << endl;
return 0;
}
运行结果
🍅 实战演练
现在给出了一个域名 url1,要求是:取出 url 的协议名、域名、资源。
string url1("https://cplusplus.com/reference/string/string/find/");
(1)取出协议名
代码示例
int main()
{
string url1("https://cplusplus.com/reference/string/string/find/");
string& url = url1;
// 1.取出协议名
string protocol;
size_t pos1 = url.find("://");
if (pos1 != string::npos) {
protocol = url.substr(0, pos1);
cout << "protocol: " << protocol << endl;
}
else {
cout << "非法url" << endl;
}
return 0;
}
运行结果

(2)取出域名
代码示例
int main()
{
string url1("https://cplusplus.com/reference/string/string/findr/");
string& url = url1;
string protocol;
size_t pos1 = url.find("://");
if (pos1 != string::npos) {
protocol = url.substr(0, pos1);
cout << "protocol: " << protocol << endl;
}
else {
cout << "非法url" << endl;
}
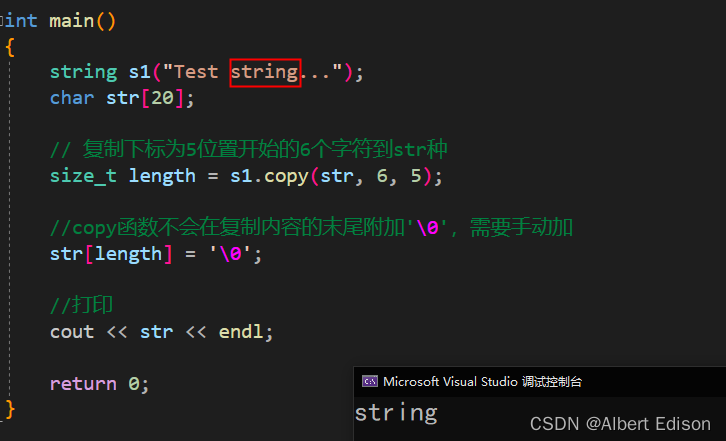
// 2.取出域名
string domain;
size_t pos2 = url.find('/', pos1 + 3);
if (pos2 != string::npos) {
domain = url.substr(pos1 + 3, pos2 - (pos1 + 3));
cout << "domain: " << domain << endl;
}
else {
cout << "非法url" << endl;
}
return 0;
}
运行结果
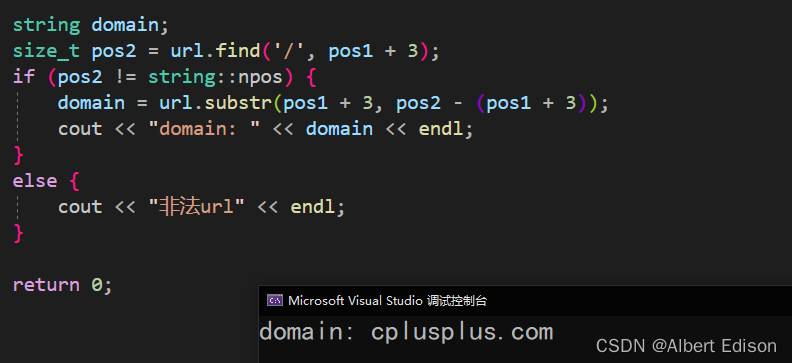
这段代码 url.substr(pos1 + 3, pos2 - (pos1 + 3)) 的图示如下
(3)取出资源
这个简单,直接把 pos2 后面的内容全部取出
代码示例
int main()
{
string url1("https://cplusplus.com/reference/string/string/substr/");
string& url = url1;
// 1.取出协议名
string protocol;
size_t pos1 = url.find("://");
if (pos1 != string::npos) {
protocol = url.substr(0, pos1);
cout << "protocol: " << protocol << endl;
}
else {
cout << "非法url" << endl;
}
// 2.取出域名
string domain;
size_t pos2 = url.find('/', pos1 + 3);
if (pos2 != string::npos) {
domain = url.substr(pos1 + 3, pos2 - (pos1 + 3));
//cout << "domain: " << domain << endl;
}
else {
cout << "非法url" << endl;
}
// 3.取出资源
string uri = url.substr(pos2 + 1);
cout << "uri: " << uri << endl;
return 0;
}
运行结果
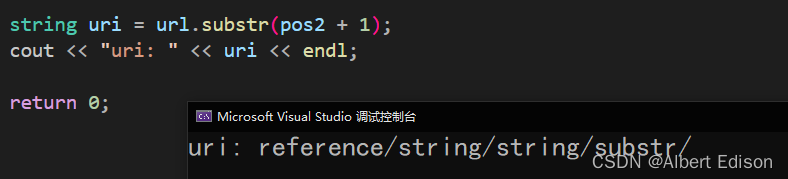
为什么是 pos2 + 1 呢?图示如下

🍑 string 中的getline函数
首先,我们使用 cin 输入一个字符串,然后再使用 cout 打印,看下会出现什么结果
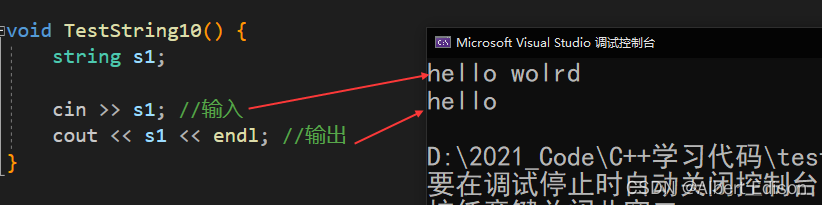
可以看到,我明明输入的是 hello world,但为什么打印出来的是 hello 呢?
那是因为当我们使用 >> 进行输入操作时,当 >> 读取到空格便会停止读取,基于此,我们将不能用 >> 将一串含有空格的字符串读入到 string 对象中。
这时,我们就需要使用 getline 函数完成一串含有空格的字符串的读取操作了。
getline 函数在这里有两种方式,先看第一种
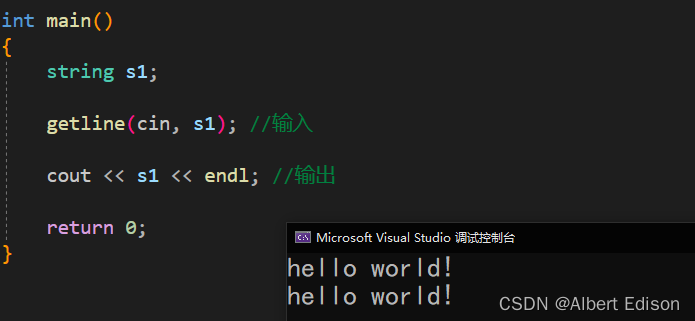
(1)getline 函数将从 is 中提取到的字符存储到 str 中,直到读取到换行符 \n 为止
代码示例
int main()
{
string s1;
getline(cin, s1); //输入
cout << s1 << endl; //输出
return 0;
}
运行结果
(2)getline 函数将从 is 中提取到的字符存储到 str 中,直到读取到分隔符 delim 或换行符 \n 为止
代码示例
int main()
{
string s1;
getline(cin, s1, 'd'); //输入
cout << s1 << endl; //输出
return 0;
}
运行结果
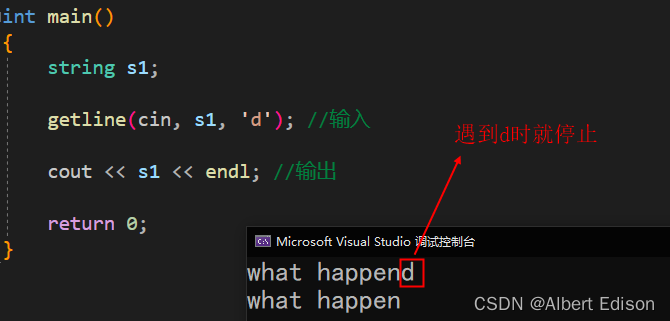
也就是说,如果输入的字符串中,出现了 delim 字符,那么程序读取到 delim 字符就会停止,并打印输出;
如果输入的字符串中,没有出现 delim 字符,那么程序读取到 \0 就会停止,并打印输出;
总结
string 其实算不上是 STL 中的一个,因为它比 STL 出来的还要更早,上面已经对 string 类进行了简单的介绍,大家只要能够正常使用即可。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/80827.html

