
🌟 前言
大家好,我是Edison😎
本篇文章将继续介绍常见八大排序中的 选择排序;
前面已经写过了 插入排序 和 交换排序(点击即可跳转到文章页面)
不废话,直接干!😎
Let’s get it!
🛫送给所有正在努力的大家一句话:你不一定逆风翻盘,但一定要向阳而生🌅

文章目录
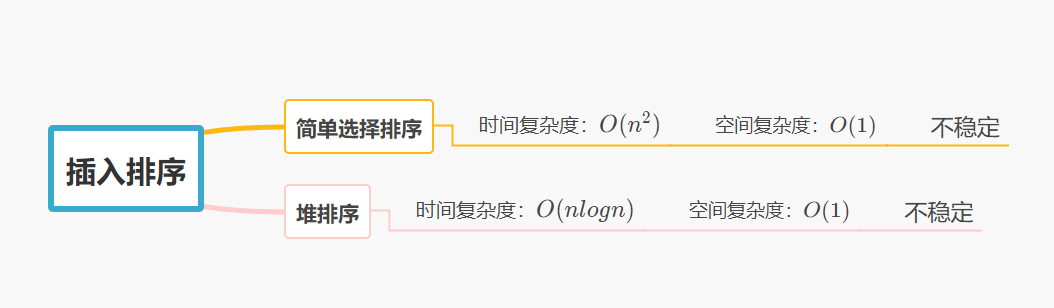
1. 选择排序分类
选择排序可以分为: 简单选择排序 和 堆排序
2. 简单选择排序
🍑 基本思想
选择排序(Selection sort)是一种简单直观的排序算法;
它的工作原理是:每一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置;直到全部待排序的数据元素排完 。
😎暴力图解展示
这里直接拿一组数来举例:
第二次交换:
第三次交换:
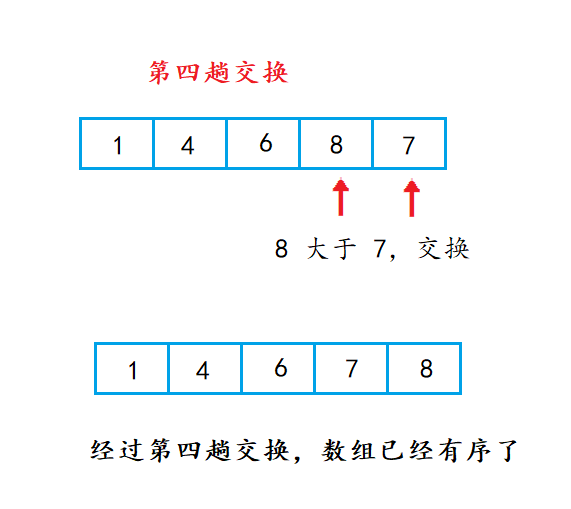
第四次交换:
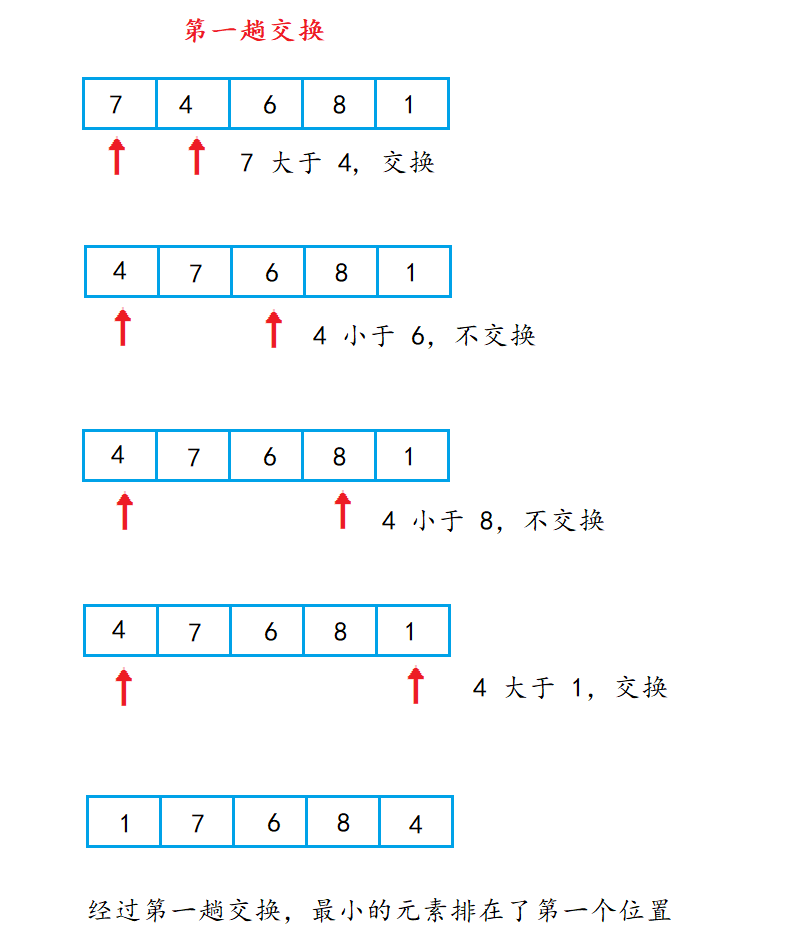
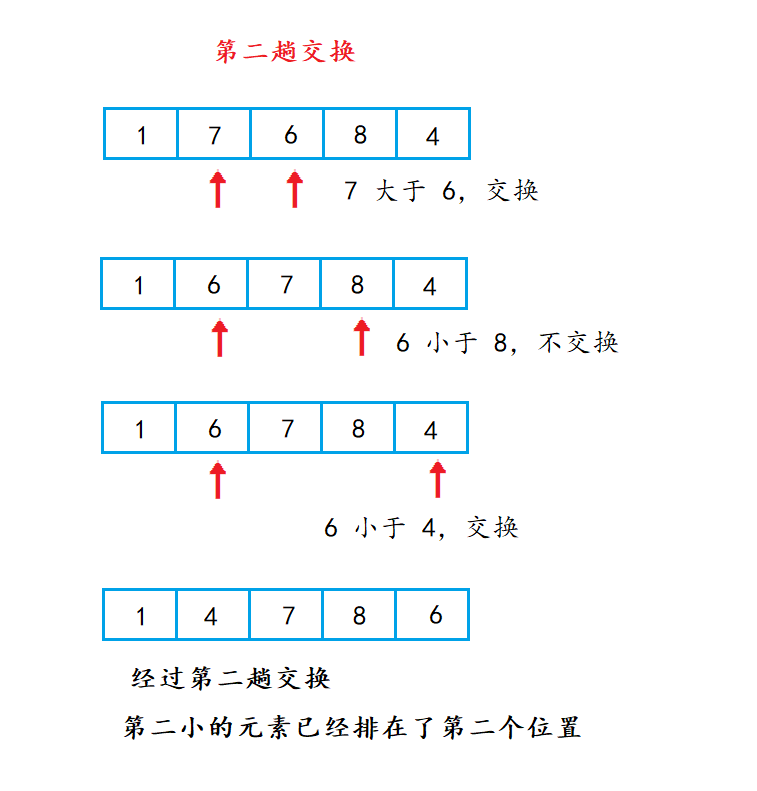
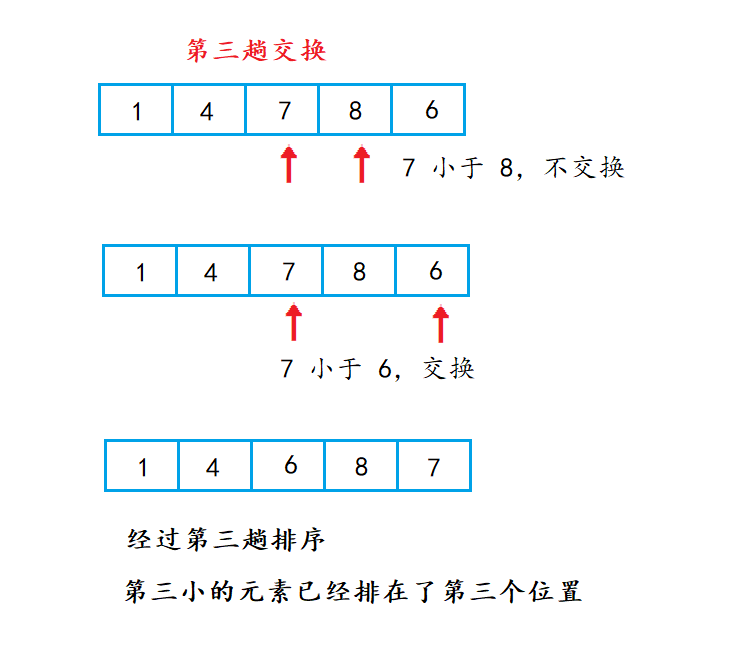
🍑 动图演示
在元素集合
array[i]到array[n-1]中选择关键码最大(小)的数据元素;
若它不是这组元素中的最后一个(第一个)元素,则将它与这组元素中的最后一个(第一个)元素交换;
在剩余的
array[i]到array[n-2](array[i+1]--array[n-1])集合中,重复上述步骤,直到集合剩余1个元素
📃 代码实现
//写一个交换函数
void Swap(int* px, int* py)
{
int tmp = *px;
*px = *py;
*py = tmp;
}
//选择排序(一次选一个数)
void SelectSort(int* a, int n)
{
int i = 0;
for (i = 0; i < n; i++)//i代表参与该趟选择排序的第一个元素的下标
{
int start = i;
int min = start;//记录最小元素的下标
while (start < n)
{
if (a[start] < a[min])
min = start;//最小值的下标更新
start++;
}
Swap(&a[i], &a[min]);//最小值与参与该趟选择排序的第一个元素交换位置
}
}
其实这段代码还可以进行升级😏
实际上,我们可以一趟选出两个值:
一个最大值一个最小值,然后将其放在序列开头和末尾,这样可以使选择排序的效率快一倍。
void Swap(int* px, int* py)
{
int tmp = *px;
*px = *py;
*py = tmp;
}
//选择排序(一次选两个数)
void SelectSort(int* a, int n)
{
int left = 0;//记录参与该趟选择排序的第一个元素的下标
int right = n - 1;//记录参与该趟选择排序的最后一个元素的下标
while (left < right)
{
int minIndex = left;//记录最小元素的下标
int maxIndex = left;//记录最大元素的下标
int i = 0;
//找出最大值及最小值的下标
for (i = left; i <= right; i++)
{
if (a[i] < a[minIndex])
minIndex = i;
if (a[i]>a[maxIndex])
maxIndex = i;
}
//将最大值和最小值放在序列开头和末尾
Swap(&a[minIndex], &a[left]);
if (left == maxIndex)
{
maxIndex = minIndex;//防止最大值位于序列开头,被最小值交换
}
Swap(&a[maxIndex], &a[right]);
left++;
right--;
}
}
🍑 概括总结
1、直接选择排序思考非常好理解,但是效率不是很好。实际中很少使用 ;
2、时间复杂度:$O(N^2) $
3、空间复杂度:$O(1) $
4、稳定性:不稳定
3. 堆排序
🍑 基本思想
堆排序(Heapsort)是指:利用堆积树(堆)这种数据结构所设计的一种排序算法,它是选择排序的一种。
它是通过 堆 来进行选择数据。需要注意的是 排升序要建大堆,排降序建小堆。
要学习堆排序,首先要学习堆的向下调整算法,因为要用堆排序,你首先得建堆,而建堆需要执行多次堆的向下调整算法。
(关于堆的详细解释,我这里只是简单说一下,后面我会单独出一期博客来讲解,因为设计到的知识点太多了)
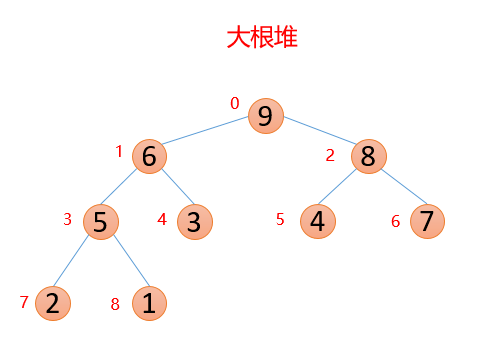
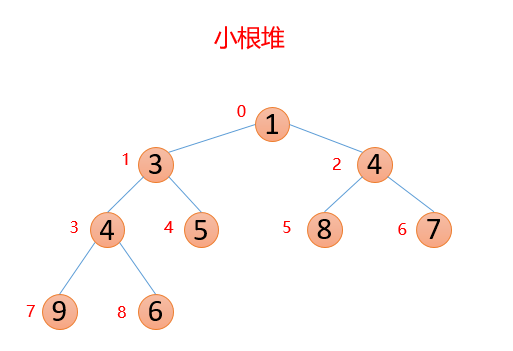
🍑 大根堆和小根堆
堆的结构可以分为 大根堆 和 小根堆,是一个 完全二叉树 ,而堆排序是根据堆的这种数据结构设计的一种排序,下面先来看看什么是大根堆和小根堆
每个结点的值都大于其 左孩子和右孩子结点的值,称之为大根堆;👇
每个结点的值都小于其 左孩子 和 右孩子 结点的值,称之为小根堆;👇
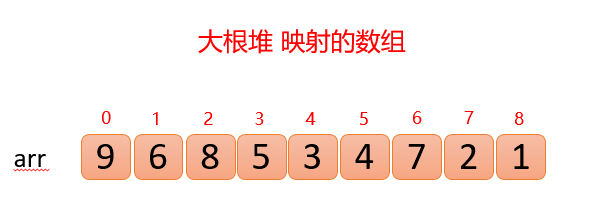
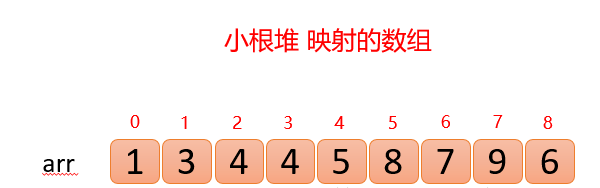
我们对上面的图中每个数都进行了标记,上面的结构映射成数组就变成了下面这个样子;👇
🍑 堆的性质
假设我们查找数组中某个数的父结点和左右孩子结点,比如已知索引为i的数,那么👇
1、父结点索引:
(
i
−
1
)
/
2
(i-1)/2
(i−1)/2(这里计算机中的除以2,省略掉小数)
2、左孩子索引:
2
∗
i
+
1
2*i+1
2∗i+1
3、右孩子索引:
2
∗
i
+
2
2*i+2
2∗i+2
所以上面两个数组可以脑补成堆结构,因为他们满足堆的定义性质👇
大根堆:
a
r
r
(
i
)
>
a
r
r
(
2
∗
i
+
1
)
arr(i)>arr(2*i+1)
arr(i)>arr(2∗i+1)
&&a
r
r
(
i
)
>
a
r
r
(
2
∗
i
+
2
)
arr(i)>arr(2*i+2)
arr(i)>arr(2∗i+2)
小根堆:
a
r
r
(
i
)
<
a
r
r
(
2
∗
i
+
1
)
arr(i)<arr(2*i+1)
arr(i)<arr(2∗i+1)
&&a
r
r
(
i
)
<
a
r
r
(
2
∗
i
+
2
)
arr(i)<arr(2*i+2)
arr(i)<arr(2∗i+2)
🍑 构造堆
排序步骤👇
首先将待排序的数组构造成一个大根堆,此时,整个数组的最大值就是堆结构的顶端;
将顶端的数与末尾的数交换,此时,末尾的数为最大值,剩余待排序数组个数为n-1;
将剩余的n-1个数再构造成大根堆,再将顶端数与n-1位置的数交换,如此反复执行,便能得到有序数组
构造👇
将无序数组构造成一个大根堆(升序用大根堆,降序就用小根堆)
假设存在以下数组
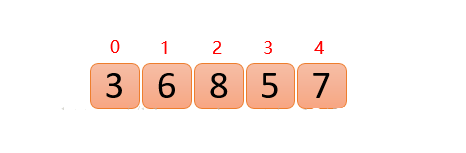
🤔主要思路:
第一次保证
0~0位置大根堆结构;
第二次保证
0~1位置大根堆结构;
第三次保证
0~2位置大根堆结构;
直到保证
0~n-1位置大根堆结构;
(每次新插入的数据都与其父结点进行比较,如果插入的数比父结点大,则与父结点交换;否则一直向上交换,直到小于等于父结点,或者来到了顶端)
开始交换👇
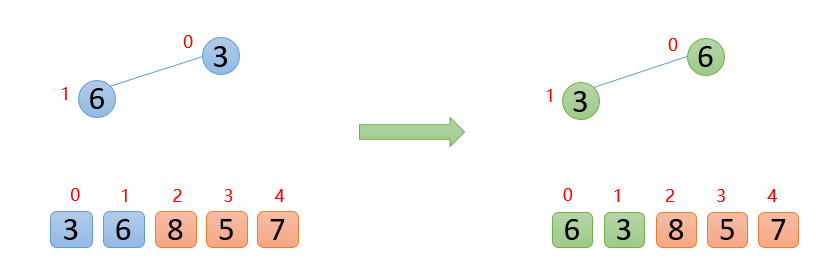
插入6的时候,6大于他的父结点3,即
arr(1)>arr(0),则交换;
此时,保证了
0~1位置是大根堆结构,如下图:
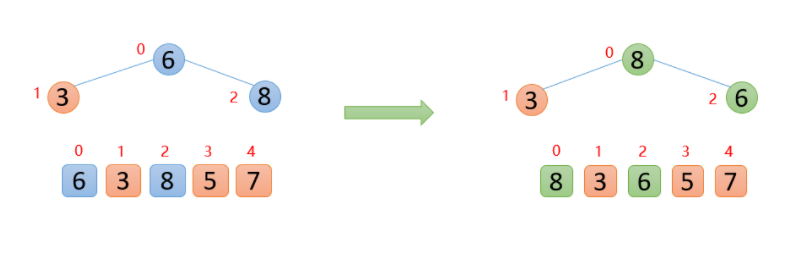
插入8的时候,8大于其父结点6,即
arr(2)>arr(0),则交换;
此时,保证了
0~2位置是大根堆结构,如下图:
插入5的时候,5大于其父结点3,则交换;交换之后,5又发现比8小,所以不交换;
此时,保证了
0~3位置大根堆结构,如下图:
插入7的时候,7大于其父结点5,则交换;交换之后,7又发现比8小,所以不交换;
此时 整个数组已经是大根堆结构
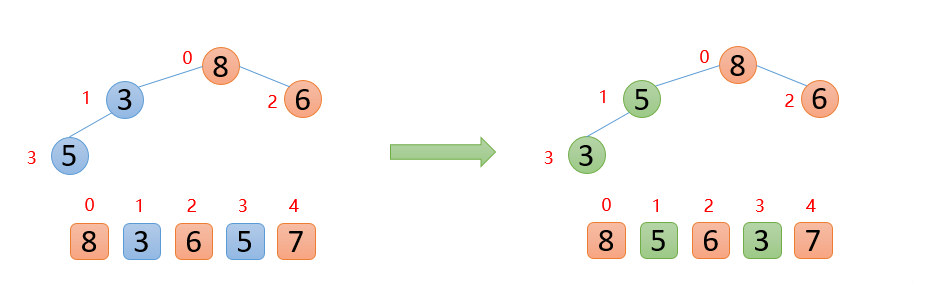
🍑 固定最大值再构造堆
此时,我们已经得到一个大根堆,下面将顶端的数与最后一位数交换,然后将剩余的数再构造成一个大根堆👇
此时最大数8已经来到末尾,则固定不动,后面只需要对顶端的数据进行操作即可;
拿顶端的数与其左右孩子较大的数进行比较,如果顶端的数大于其左右孩子较大的数,则停止;
如果顶端的数小于其左右孩子较大的数,则交换,然后继续与下面的孩子进行比较;
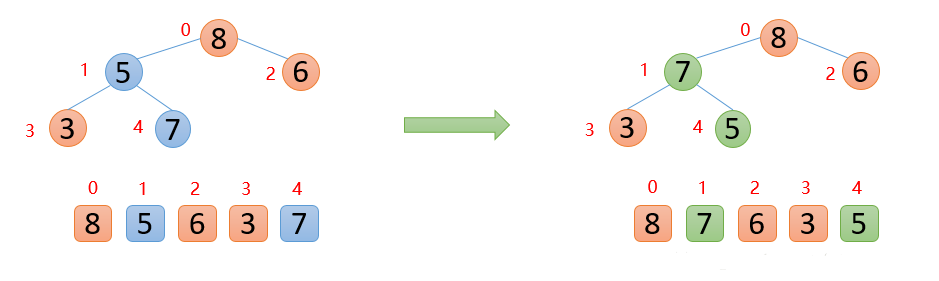
下图中,5的左右孩子中,左孩子7比右孩子6大,则5与7进行比较,发现
5<7,则交换;交换后,发现5已经大于他的左孩子,说明剩余的数已经构成大根堆,后面就是重复固定最大值,然后构造大根堆👇
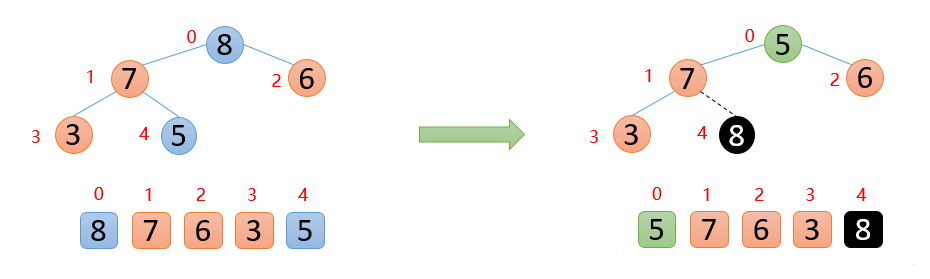
顶端数7与末尾数3进行交换,固定好7, 如下图👇
剩余的数开始构造大根堆 ,然后顶端数与末尾数交换,固定最大值再构造大根堆,重复执行上面的操作,最终会得到有序数组👇
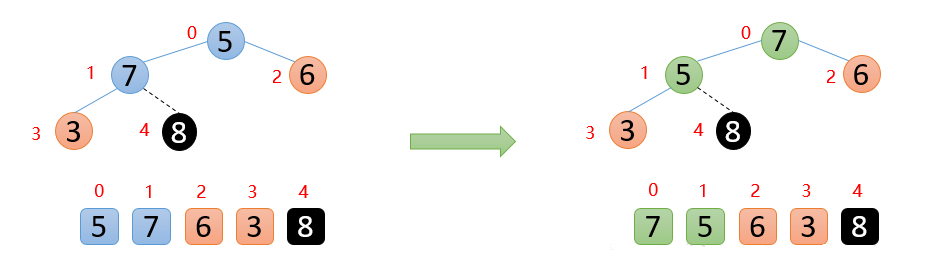
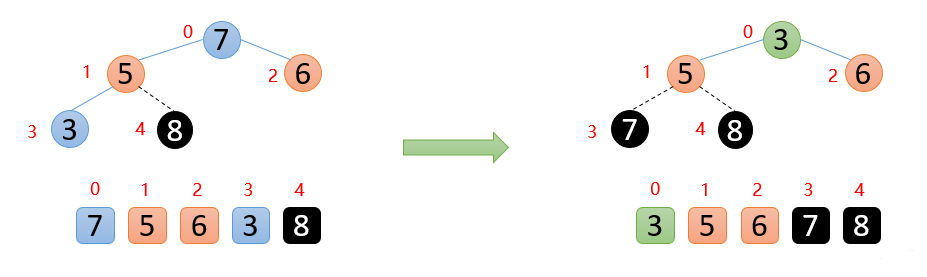
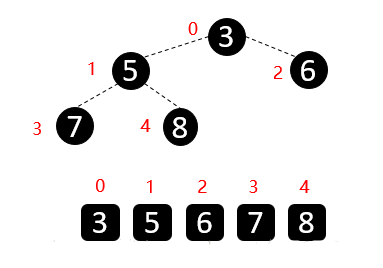
到这里,大家应该对堆排序都有了自己的见解,我们对上面的流程总结下:
1、首先将无需数组构造成一个大根堆(新插入的数据与其父结点比较)
2、固定一个最大值,将剩余的数重新构造成一个大根堆,重复这样的过程
🍑 动图演示
看过了上面的推排序流程以后,我们再来看一张经典的 堆排序 动图👇

是不是思路一下子就通顺了?
📃 代码实现
void Swap(int* px, int* py)
{
int tmp = *px;
*px = *py;
*py = tmp;
}
//堆排序
void AdjustDown(int* a, int n, int parent){
int child = parent*2 + 1;
while(child < n){
if(child+1<n && a[child+1] > a[child]){
++child;
}
if(a[child]>a[parent]){
Swap(&a[child], &a[parent]);
parent = child;
child = parent*2+1;
}else{
break;
}
}
}
void HeapSort(int* a, int n){
//排升序建大堆 O(N)
for(int i=(n-1-1)/2; i>=0; i--){
AdjustDown(a, n, i);
}
//O(N*logN)
int end = n - 1;
while(end > 0){
Swap(&a[0], &a[end]);
AdjustDown(a, end, 0); //是不是妙不可言hhh!
end--;
}
}
🍑 概括总结
1、堆排序使用堆来选数,效率就高了很多。
2、时间复杂度:
O
(
N
∗
l
o
g
N
)
O(N*logN)
O(N∗logN)
3、空间复杂度:
O
(
1
)
O(1)
O(1)
4、稳定性:不稳定
4. 总结
其实在选择排序里面 直接选择排序 是很简单的😏
但是 堆排序 可能你看了这篇文章,并不一定能学会,或者说,还是不明白什么是 堆排序?
别急,这是正常现象,那么可以去网上找找视频,然后再看一些书籍,来加深自己的理解💪
🤗作者水平有限,如有总结不对的地方,欢迎留言或者私信!
💕如果你觉得这篇文章还不错的话,那么点赞👍、评论💬、收藏🤞就是对我最大的支持!
🌟你知道的越多,你不知道越多,我们下期见!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/80914.html

