
我们要将数据库中的数据放入缓存中对比去除数据的时间:
首先我们定义好主方法,然后加载驱动:
Class.forName("com.mysql.cj.jdbc.Driver");
然后开始一个大的循环,先定义好缓存的HashMap:
HashMap<String, Integer> hashMap = new HashMap<>(10);
接下来就是判断用户的输入:
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(System.in));
System.out.println();
System.out.println("------------年龄查询系统--------");
System.out.println("请输入用户名");
String name = bufferedReader.readLine();
if (name.equals("0")){
System.out.println("程序已退出,谢谢使用");
break;
}
当在缓存中读到之后直接读取数据:
//如果缓存中有相应的 key ,则直接读取
if (hashMap.containsKey(name)){
System.out.println("这是从缓存中取到的数据-》"+name+"的年龄是"+hashMap.get(name)+"岁");
}
没有读到则去数据库中去读数据,并且将数据存入缓存之中:
Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/csdn", "root", "root");
//定义sql语句
String sql = "SELECT * FROM test WHERE name ='"+name+"'";
PreparedStatement pr = connection.prepareStatement(sql);
ResultSet rs = pr.executeQuery();
if (rs.next()){
String cacheName = name;
int catchAge = rs.getInt(2);
hashMap.put(cacheName,catchAge);
System.out.println("这是从数据库中拿到的数据->"+name+"的年龄是"+hashMap.get(name)+"岁");
System.out.println("数据已存入到缓存中!");
}
else {
System.out.println("数据库中没有这个数据");
}
全部代码:
package com.ftz.Demo.test;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.sql.*;
import java.util.HashMap;
/**
* @author ${范涛之}
* @Description
* @create 2021-12-22 10:34
*/
public class Test2 {
public static void main(String[] args) throws ClassNotFoundException, IOException, SQLException {
Class.forName("com.mysql.cj.jdbc.Driver");
HashMap<String, Integer> hashMap = new HashMap<>(10);
while (true){
BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(System.in));
System.out.println();
System.out.println("------------年龄查询系统--------");
System.out.println("请输入用户名");
String name = bufferedReader.readLine();
if (name.equals("0")){
System.out.println("程序已退出,谢谢使用");
break;
}
//如果缓存中有相应的 key ,则直接读取
if (hashMap.containsKey(name)){
System.out.println("这是从缓存中取到的数据-》"+name+"的年龄是"+hashMap.get(name)+"岁");
}
/**
*
* 缓存中没有则从数据库中取出
*/
else {
Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/csdn", "root", "root");
//定义sql语句
String sql = "SELECT * FROM test WHERE name ='"+name+"'";
PreparedStatement pr = connection.prepareStatement(sql);
ResultSet rs = pr.executeQuery();
if (rs.next()){
String cacheName = name;
int catchAge = rs.getInt(2);
hashMap.put(cacheName,catchAge);
System.out.println("这是从数据库中拿到的数据->"+name+"的年龄是"+hashMap.get(name)+"岁");
System.out.println("数据已存入到缓存中!");
}
else {
System.out.println("数据库中没有这个数据");
}
}
}
}
}
尝试 Caffeine 的另外两种过期策略 expireAfterWrite()和 expireAfter(),以及另外两种刷新策略 refreshAfterWrite()和 reload()。另外,Caffeine 也能够主动「移除」不再需要的缓存数据,请尝试 Caffeine 的 invalidate()和 invalidateAll()方法,然后通过recordStats()方法来监控缓存状态。
首先说一下怎样加载Caffeine:
<dependency>
<groupId>com.github.ben-manes.caffeine</groupId>
<artifactId>caffeine</artifactId>
</dependency>
首先看一个示例代码:
import com.github.benmanes.caffeine.cache.Caffeine;
import com.github.benmanes.caffeine.cache.LoadingCache;
import java.util.concurrent.TimeUnit;
/**
* @author ${范涛之}
* @Description
* @create 2021-12-22 11:14
*/
public class Test {
public static void main(String[] args) throws InterruptedException {
LoadingCache<String, Object> caffeine = Caffeine.newBuilder()
.maximumSize(1)
// 最后一次读取并经过指定时间后失效,如果一直访问就不会失效
// 经过指定时间不访问后也会失效
.expireAfterAccess(5, TimeUnit.SECONDS)
.build(key -> {
// 当无对应值或数据已失效时返回
return null;
});
System.out.println("开始 ----> ");
caffeine.put("test", 1);
Thread.sleep(3000);
System.out.println("3 秒后 ----> " + caffeine.get("test"));
Thread.sleep(3000);
System.out.println("3 秒后 ----> " + caffeine.get("test"));
Thread.sleep(1000);
System.out.println("1 秒后 ----> " + caffeine.get("test"));
Thread.sleep(5000);
System.out.println("5 秒后 ----> " + caffeine.get("test"));
}
}
我们来读一下这段代码: .maximumSize(1)代表缓存的数量最大是1, .expireAfterAccess(2, TimeUnit.SECONDS)这个第一个参数代表秒,第二个就是说前面这个是秒
看一下第二段代码:
import com.github.benmanes.caffeine.cache.Caffeine;
import com.github.benmanes.caffeine.cache.LoadingCache;
import java.util.concurrent.TimeUnit;
/**
* @author ${范涛之}
* @Description
* @create 2021-12-22 11:33
*/
public class Test2 {
private static String value = "xiangwang";
public static String getValue() {
return value;
}
public static void setValue(String value) {
Test2.value = value;
}
public static void main(String[] args) throws InterruptedException {
LoadingCache<String, Object> caffeine = Caffeine.newBuilder()
.maximumSize(1)
.expireAfterWrite(5, TimeUnit.MINUTES)
.build(key -> {
return getValue();
});
caffeine.put("username", "xiangwang1");
System.out.println("更新前:" + caffeine.get("username"));
setValue("xiangwang2");
System.out.println("已更新但未刷新:" + caffeine.get("username"));
caffeine.refresh("username");// 主动刷新
System.out.println("已刷新:" + caffeine.get("username"));
}
}
通过这个案例我们可以看出来更新了数据不刷新的话显示还是原来的
下面我们说一下三个刷新的区别:
expireAfterAccess: 当缓存项在指定的时间段内没有被读或写就会被回收。
expireAfterWrite:当缓存项在指定的时间段内没有更新就会被回收。
refreshAfterWrite:当缓存项上一次更新操作之后的多久会被刷新。
代码举例:
import com.github.benmanes.caffeine.cache.Caffeine;
import com.github.benmanes.caffeine.cache.LoadingCache;
import java.util.concurrent.TimeUnit;
/**
* @author ${范涛之}
* @Description
* @create 2021-12-22 11:14
*/
public class Test {
public static void main(String[] args) throws InterruptedException {
LoadingCache<String, Object> caffeine = Caffeine.newBuilder()
.maximumSize(1)
// 最后一次读取并经过指定时间后失效,如果一直访问就不会失效
// 经过指定时间不访问后也会失效
.expireAfterWrite(5, TimeUnit.SECONDS)
.build(key -> {
// 当无对应值或数据已失效时返回
return null;
});
System.out.println("开始 ----> ");
caffeine.put("test", 1);
Thread.sleep(1000);
System.out.println("使用expireAfterAccess只经行读写操作:1 秒后 ----> (这里读了一下数据缓存时间更新为五秒)" + caffeine.get("test"));
Thread.sleep(4000);
System.out.println("使用expireAfterAccess只经行读写操作:4 秒后 ----> " + caffeine.get("test"));
}
}
首先上图:
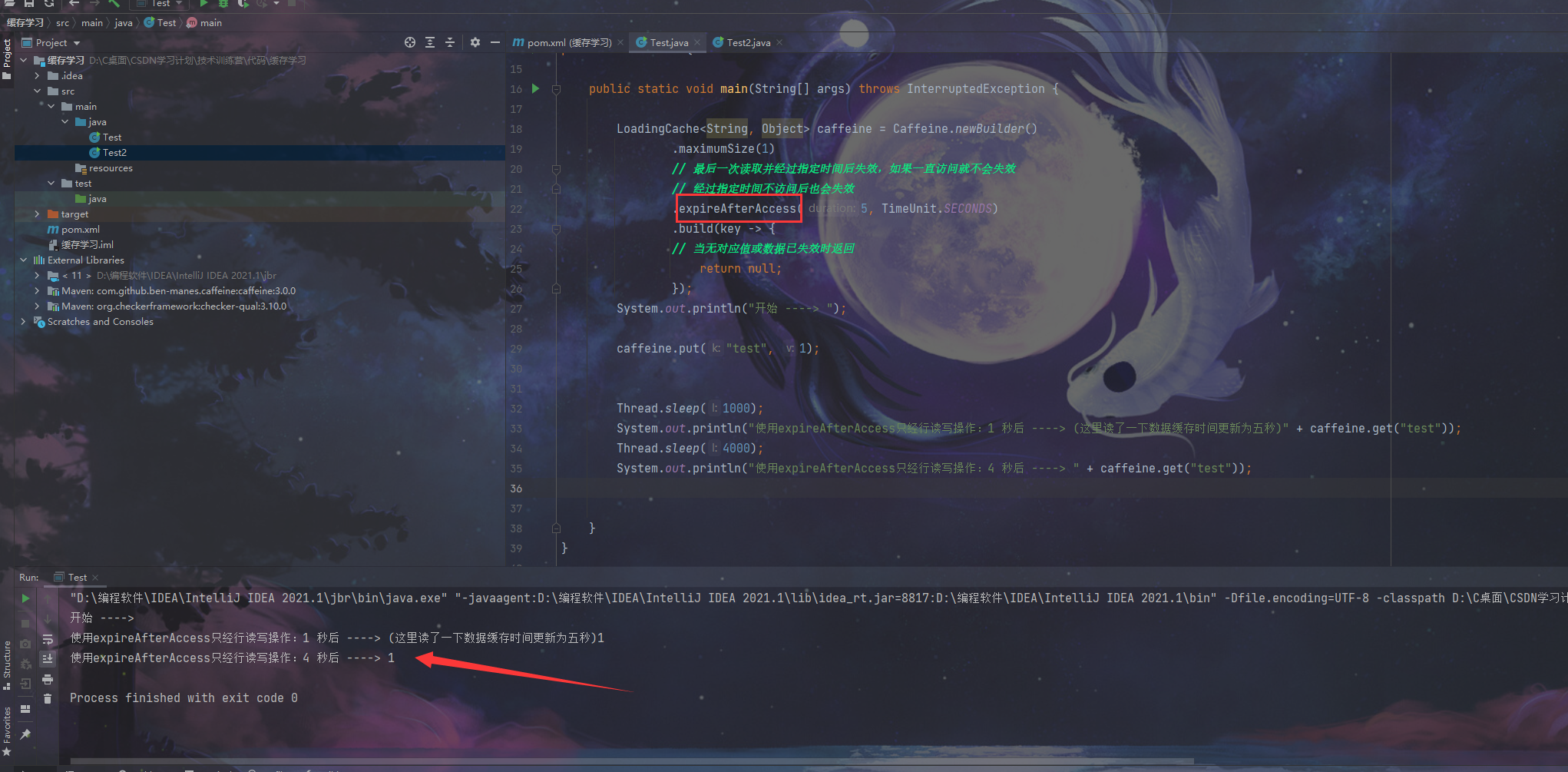
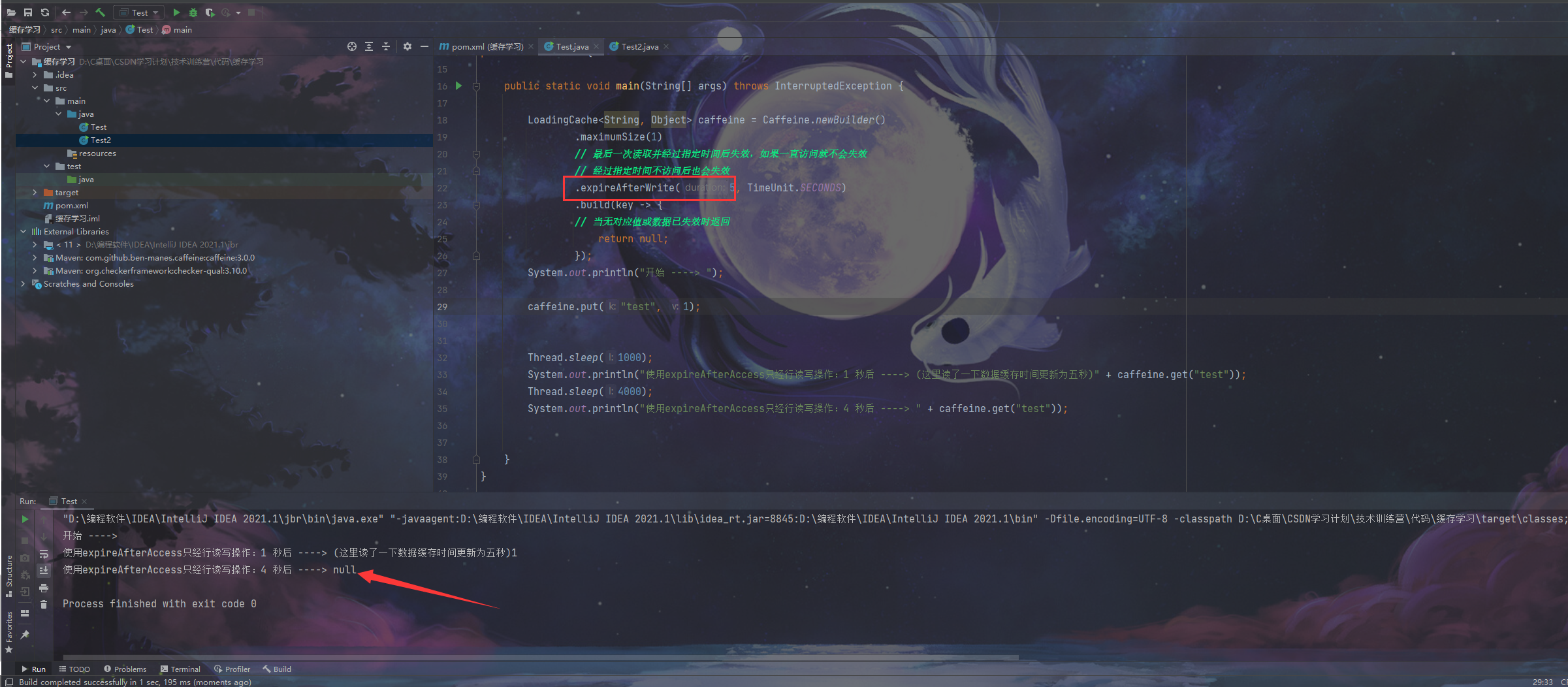
我们可以明显的发现,两次运行的代码只有一个地方不一样那就是将expireAfterAccess改为expireAfterWrite,但是运行结果却出现了改变这是因为,expireAfterWrite意思就是必须经行一次更新数据才可以去刷新缓存的数据存在时间!!要是仅仅是去读数据是没有用的,到了一开始定好滴那个5秒后数据就会丢失!但是expireAfterAccess就是在你读了一次数据以后,一开始倒计时的那个5秒在读取的一瞬间就会恢复5秒!数据保存的时间就变长了!
任务三:
在 https://try.redis.io 这个站点尝试 Redis 中所有的常用数据类型相关命令,包括
String、Hash、List、Set 和 ZSet,并完成下表:
Redis的五大数据类型
1.String(字符串)
-
string是redis最基本的类型,你可以理解成与Memcached一模一样的类型,一个key对应一个value。
-
string类型是二进制安全的。意思是redis的string可以包含任何数据。比如jpg图片或者序列化的对象 。
-
string类型是Redis最基本的数据类型,一个redis中字符串value最多可以是512M
2.Hash(哈希,类似java里的Map)
-
Redis hash 是一个键值对集合。
-
Redis hash是一个string类型的field和value的映射表,hash特别适合用于存储对象。
-
类似Java里面的Map<String,Object>
3.List(列表)
它的底层实际是个链表
4.Set(集合)
5.Zset(sorted set:有序集合)
-
zset(sorted set:有序集合)
-
Redis zset 和 set 一样也是string类型元素的集合,且不允许重复的成员。
-
不同的是每个元素都会关联一个double类型的分数【注意是double类型分数】。
-
redis正是通过分数来为集合中的成员进行从小到大的排序。zset的成员是唯一的,但分数(score)却可以重复。

日后回来看Redis!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/81016.html

