
创建学生表:
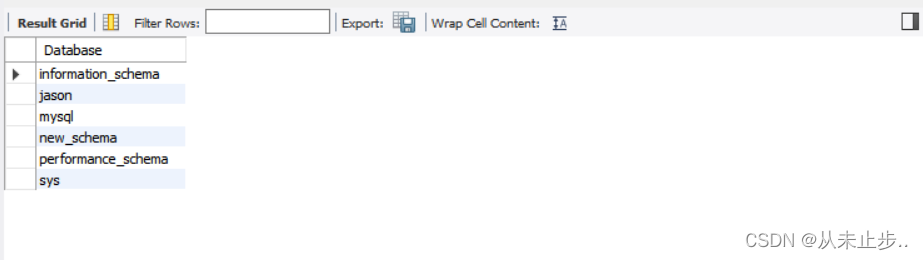
首先,我们先来查看MySQL服务器当前的所有数据库:
命令:
show databases;
查询结果:
删除数据库:
drop database if exists sys;
-- 如果该数据库存在直接删除,否则编译器会进行提示
创建数据库并指定默认字符集:
命令:
create database 库名 character set utf8;
-- 编码为utf8
首先,我们先来创建一个学生选课系统数据库:
命令:
create database stu_course default charset utf8;
使用数据库:
下面我们就可以使用刚刚创建创建好的学生选课数据库了。
use stu_course;
查看当前数据库中所有表:
show tables;
创建学生表:
MySQL支持所有标准的SQL数据类型,主要分3类:
数值类型
字符串类型
时间日期类型
语法格式如下所示:

举例:
create table TbStudent
(
stuid integer not null,
stuname varchar(20) not null,
stusex bit default 1,
stubirth datetime not null,
stutel char(11),
stuaddr varchar(255),
stuphoto longblob, -- longblob:可以存储二进制的大的容器对象
primary key (stuid)
);
修改学生表:
修改数据表结构:
语法格式:

举例:
alter table TbStudent drop column stutel;
-- 删除stutel列:
创建课程表:
create table TbCourse
(
cosid integer not null,
cosname varchar(50) not null,
coscredit tinyint not null,//tinyint:设置无符号: 0 到 255 的整型数据;未设置无符号:-128到127
cosintro varchar(255)
);
给课程表指定主键:
alter table TbCourse add constraint pk_course primary key (cosid);
主键:
主关键字(主键,primary key)是被挑选出来,作为表的某一行的唯一标识的候选关键字。
一个表只有一个主关键字。主关键字又可以称为主键。主键可以由一个字段,也可以由多个字段组成,分别成为单字段主键或多字段主键。
创建学生选课记录表:
create table TbSC
(
scid integer primary key auto_increment,
sid integer not null,
cid integer,
scdate datetime not null,
score float
);
外键:
外键 ( foreign key ) 是用于建立和加强两个表数据之间的链接的一列或多列。通过将保存表中主键值的一列或多列添加到另一个表中,可创建两个表之间的链接。这个列就成为第二个表的外键。
添加外键:
alter table TbSC add foreign key (sid) references TbStudent (stuid) on delete cascade on update cascade;
alter table TbSC add foreign key (cid) references TBCourse (cosid) on delete set null on update cascade;
添加学生记录:
insert into TbStudent values (1001, '张三丰', default, '1978-1-1', '成都市一环路西二段17号', null);
insert into TbStudent (stuid, stuname, stubirth) values (1002, '郭靖', '1980-2-2');
insert into TbStudent (stuid, stuname, stusex, stubirth, stuaddr) values (1003, '黄蓉', 0, '1982-3-3', '成都市二环路南四段123号');
insert into TbStudent values (1004, '张无忌', 1, '1990-4-4', null, null);
insert into TbStudent values
(1005, '丘处机', 1, '1983-5-5', '北京市海淀区宝盛北里西区28号', null),
(1006, '王处一', 1, '1985-6-6', '深圳市宝安区宝安大道5010号', null),
(1007, '刘处玄', 1, '1987-7-7', '郑州市金水区纬五路21号', null),
(1008, '孙不二', 0, '1989-8-8', '武汉市光谷大道61号', null),
(1009, '平一指', 1, '1992-9-9', '西安市雁塔区高新六路52号', null),
(1010, '老不死', 1, '1993-10-10', '广州市天河区元岗路310号', null),
(1011, '王大锤', 0, '1994-11-11', null, null),
(1012, '隔壁老王', 1, '1995-12-12', null, null),
(1013, '郭啸天', 1, '1977-10-25', null, null);
添加课程记录:
insert into TbCourse values
(1111, 'C语言程序设计', 3, '大神级讲师授课需要抢座'),
(2222, 'Java程序设计', 3, null),
(3333, '数据库概论', 2, null),
(4444, '操作系统原理', 4, null);
添加学生选课记录:
insert into TbSC values
(default, 1001, 1111, '2016-9-1', 95),
(default, 1002, 1111, '2016-9-1', 94),
(default, 1001, 2222, now(), null),
(default, 1001, 3333, '2017-3-1', 85),
(default, 1001, 4444, now(), null),
(default, 1002, 4444, now(), null),
(default, 1003, 2222, now(), null),
(default, 1003, 3333, now(), null),
(default, 1005, 2222, now(), null),
(default, 1006, 1111, now(), null),
(default, 1006, 2222, '2017-3-1', 80),
(default, 1006, 3333, now(), null),
(default, 1006, 4444, now(), null),
(default, 1007, 1111, '2016-9-1', null),
(default, 1007, 3333, now(), null),
(default, 1007, 4444, now(), null),
(default, 1008, 2222, now(), null),
(default, 1010, 1111, now(), null);
查看表结构:
命令:
select *from 表名;//从某个表查询该表的所有数据 *代表所有字段
举例:
显示当前已存在的所有表:
show tables;
在已存在的表中选择任意表进行查询:
select *from tbcourse;
输出:
 如果我们想查看表的结构,使用上面这种方法显示表的全部信息好像也挺清楚,但是如果当前表存放了成百上千的数据呢?
如果我们想查看表的结构,使用上面这种方法显示表的全部信息好像也挺清楚,但是如果当前表存放了成百上千的数据呢?
这时如果我们还将表的全部信息显示出来就会有点麻烦,所以我们就要使用另一个命令来查询表的结构。
desc 表名;

输出的两种内容,很明显的区别就是第二种仅仅输出了关于表结构的信息,而没有显示任何的数据,第二章表指出了该表的字段,涉及的信息项等内容。
MySQL—-常用命令:
– 查看当前数据库的版本号
命令:
select version();
输出:

– 查看当前使用的数据库
命令:
select database();

不见分号不执行:
分号表示一条完整命令的结束:
 输出:
输出:
分号代码输入结束,开始执行命令。

简单查询:
查询单个字段:
命令:
select 字段名 from 表名;
注:select和from都是关键字,字段名和表名都是标识符
所有的sql语句都是以”;”结尾的,另外sql语句不区分大小写。
举例:
select cosid from tbcourse; //查询tbcourse表中的cosid字段
查询结果:

查询多个字段:
命令:
select 字段1,字段2..... from tbcourse;-- 字段和字段之间用逗号隔开
举例:
select cosid,cosname from tbcourse;
查询结果:

查询所有字段:
方法一:将所有的字段名都写上
命令:
select 字段1,字段2.....字段n from tbcourse;
方法二:使用(*)
命令:
select * from tbcourse;
举例:
select cosid,cosname,coscredit,cosintro from tbcourse;-- 使用字段名的方法
查询结果:

select * from tbcourse;-- 使用*的方式
 对比两种方式,在书写命令上,显然使用* 的方式大大简化了我们书写命令的量,但是
对比两种方式,在书写命令上,显然使用* 的方式大大简化了我们书写命令的量,但是在实际开发中,并不建议这样的查询方法,原因是它的效率低,并且可读性差,因为在执行命令的过程中,计算机首先会将 *转化成实际的字段名,再执行命令。
给查询的列起别名:
在这里使用as关键字起别名:
命令:
select 将要修改别名的列名 as 想要修改之后的列名 from 表名;
举例:
select cosid as id from tbcourse;-- 将列名cosid修改为id
查询结果:

select cosid,cosname as id from ;-- 将后者的列名进行修改,而前者不变
查询结果:

注意:只是将显示的查询结果列名显示为修改后的列名,但是原表名还是叫修改之前的表名。
注:select语句是永远都不会进行修改操作的(只负责查询)
as关键字也可以省略!
select 要修改的列名 修改后的列名 from 表名;
举例:
select cosid,cosname id from tbcourse;

别名中含有空格:
举例:
select cosid as id name from tbcourse;-- id name为修改之后的别名
编译并未通过:
 解决办法:
解决办法:
将含有空格的列名用单引号或者双引号括起来。
单引号是标准的,任何数据库都可以进行使用,双引号在oracle数据库中无法使用,但在MySQL中可以使用。
举例:
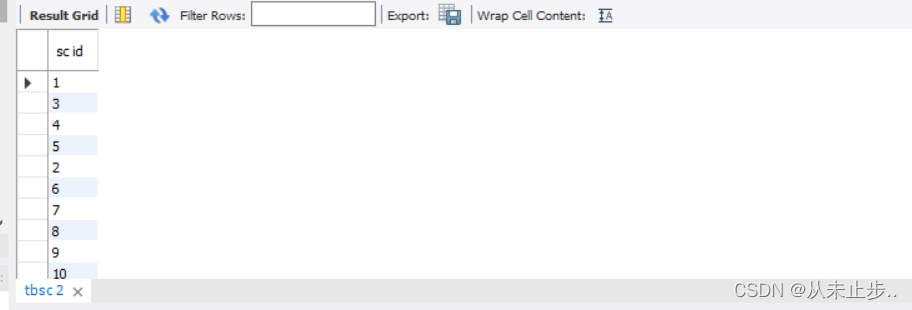
命令:
select scid "sc id" from tbsc;
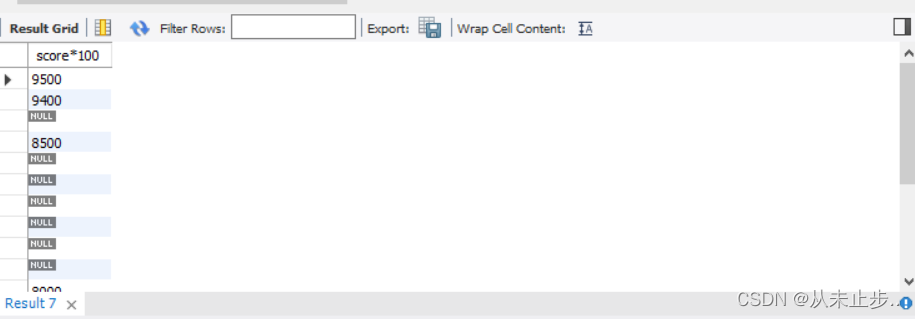
列参与数学运算:
举例:
select score*100 from tbsc; //将tbsc中的score扩大100倍
查询结果:
 原数据:
原数据:
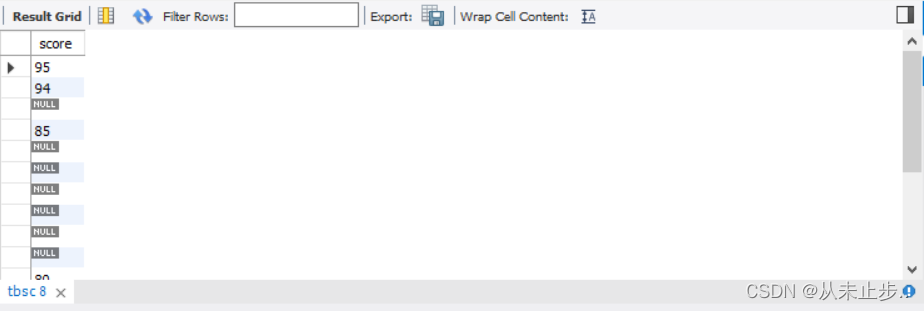 我们不难发现,在参与了数学运算之后,数据的大小不仅发生了改变,而且对应的列名也发生了改变,而变化后的列名看起来有点傻,因此,我们就可以使用上面的方法对其列名进行修改。
我们不难发现,在参与了数学运算之后,数据的大小不仅发生了改变,而且对应的列名也发生了改变,而变化后的列名看起来有点傻,因此,我们就可以使用上面的方法对其列名进行修改。
命令:
select score*100 as '扩大100倍之后的数据' from tbsc;

需要强调的是,如果要修改的列名是中文名称,那么需要用单引号括起来。
条件查询:
将符合条件的数据显示出来,而不是显示所有的数据。
select 列名1,列名2 from tbsc where 限制条件;
按条件表达式筛选:
大于[>],等于[=],小于[<]:
举例:
select cid from tbsc where score>90;-- 查询tbsc表中成绩大于90分的id
查询结果:

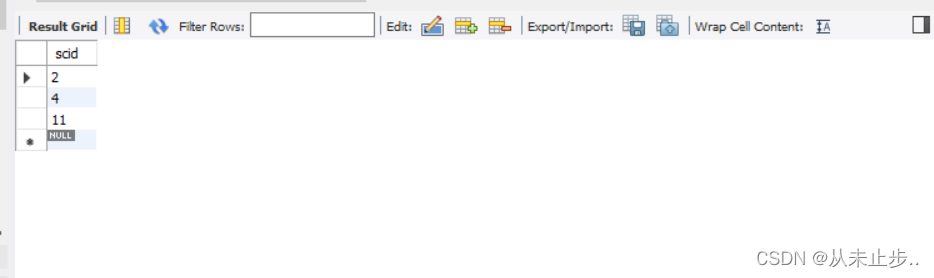
不等于:<>或!=
select scid from tbsc where score<>95;//查询tbsc表中分数不等于95的scid
查询结果:
 除上述所举的两种条件表达式之外,还有<=,>,>=等就不一一举例了。
除上述所举的两种条件表达式之外,还有<=,>,>=等就不一一举例了。
按条件表达式筛选:
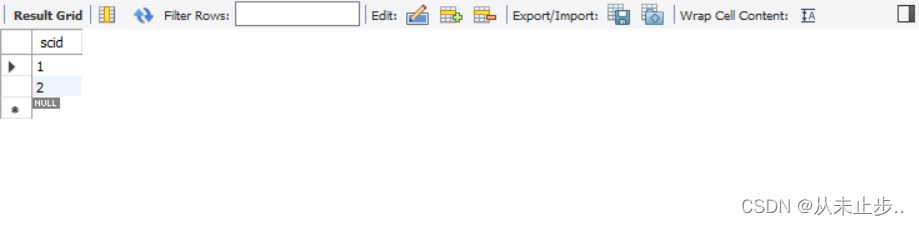
between…and…:
举例:
select scid from tbsc where score between 90 and 100 ;
-- 查询分数在90-100的学生的scid
查询结果:
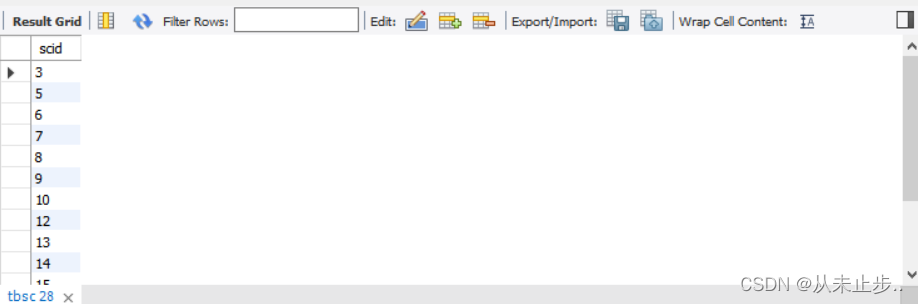
is null为null(is not null不为空):
select scid from tbsc where score is null; -- 注意不要将is写成=
查询结果:
注:在数据库当中,null不能使用等号进行衡量,需要使用 is null,因为数据库中的null代表什么也没有,它不是一个值,所以不能使用等号衡量。
is not null的用法相似,这里就不过多赘述了。
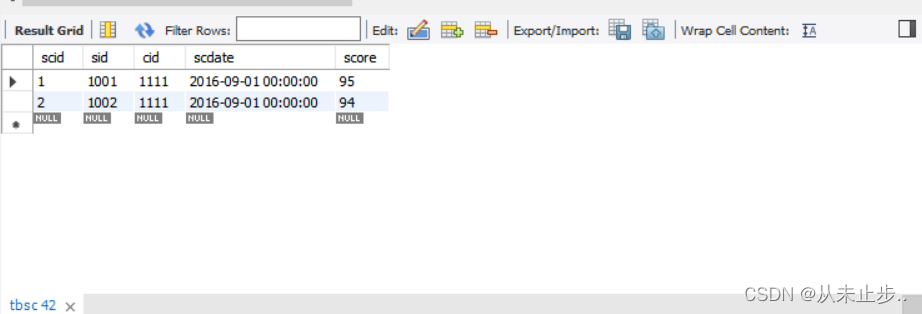
and:并且
举例:
select * from tbsc where cid=1111 and score>=90 ;
-- 查询cid的值为1111,并且分数大于90分的人的信息
查询结果:
or:或者
举例:
select * from tbsc where cid=1111 or score>=90 ;
-- 查询cid的值为1111,或者分数大于90分的人的信息
查询结果:
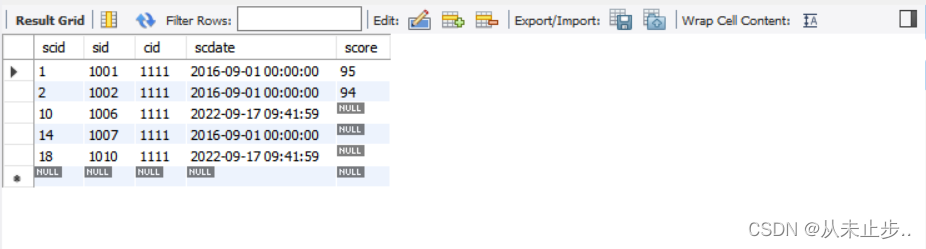
and和or同时出现:
举例:
假设现在我们需要查询该表中scid大于3,并且cid等于1111或者scid大于3,score大于等于90的员工。
请问如下命令,能否得到我们想要的结果?
select * from tbsc where scid>3 and cid=1111 or score>=90 ;
 通过输出结果,我们发现scid小于3的也被显示出来,原因就是我们的限制条件中:包含的
通过输出结果,我们发现scid小于3的也被显示出来,原因就是我们的限制条件中:包含的and和or是存在优先级顺序的,and的优先级高于or,那么编译器会根据优先级将该命令解释为找出满足scid>3 and cid=1111或者满足score>=90的相关信息。
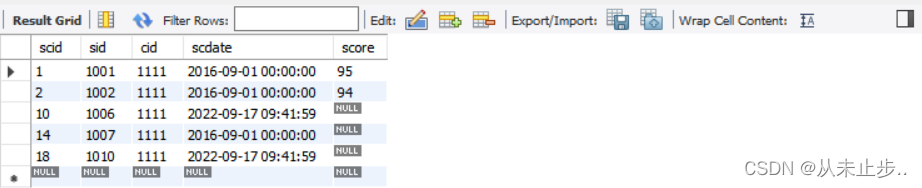
要想正确输出我们想要的信息,解决办法即为给有关or的条件带括号。
修改后的命令:
select * from tbsc where scid>3 and (cid=1111 or score>=90) ;
查询结果:
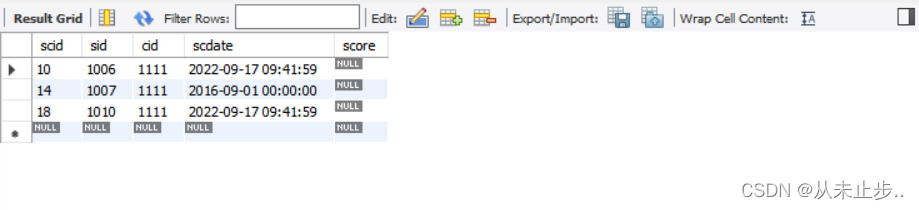
in:包含,相当于多个or【not in不在】这个范围中
举例:
select * from tbsc where cid in (1111,4444) ;
-- 查询cid等于1111或者等于4444的有关信息;
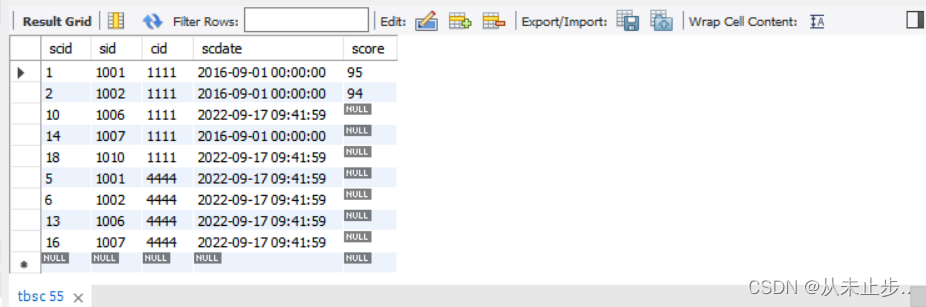
括号的含义:
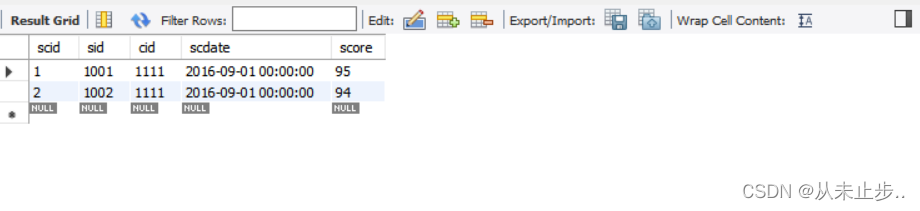
select * from tbsc where score in (94,95) ;
注意:这里的(94,95)并不是94-95,他并不代表一个范围,而是表示score等于94或等于95.
查询结果:
 not in和它的使用方法相同,就是含义为相反的意思,这里就不赘述了。
not in和它的使用方法相同,就是含义为相反的意思,这里就不赘述了。
模糊查询:
like:
称为模糊查询,支持%或下划线匹配,%匹配任意多个字符
下划线:任意一个字符,一个下划线只匹配一个字符(%是一个特殊的符号,_也是一个特殊的符号)
包含:
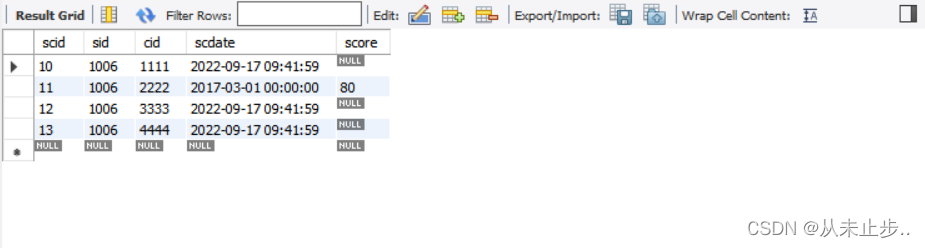
举例:
select * from tbsc where sid like '%6%' ;
-- 查询该表的sid中含有数字6的信息
查询结果:
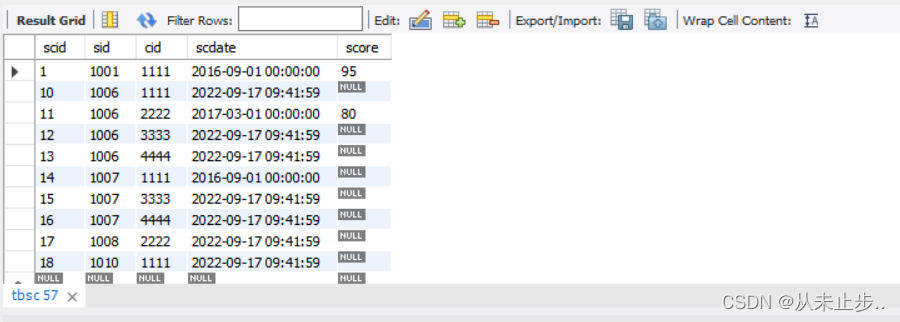
以某个字符开始:
select * from tbsc where scid like '1%' ;
-- 查询该表中scid以1开头的有关信息
以某个字符结束:
select * from tbsc where sid like '%6' ;
-- 查询该表中sid以6结尾的有关信息
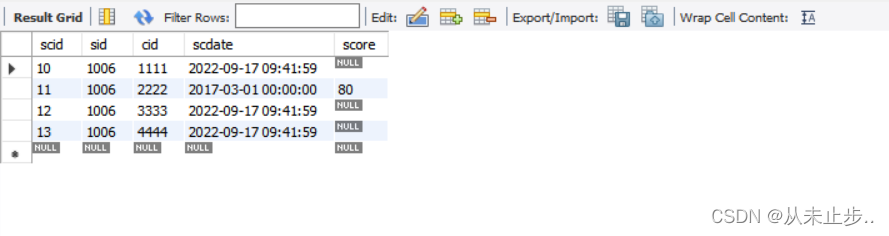
非特殊位置的某个字符的查找:
select * from tbcourse where cosname like '_语%' ;
-- 查询该表中cosname第二个字为语的有关信息
查询结果:
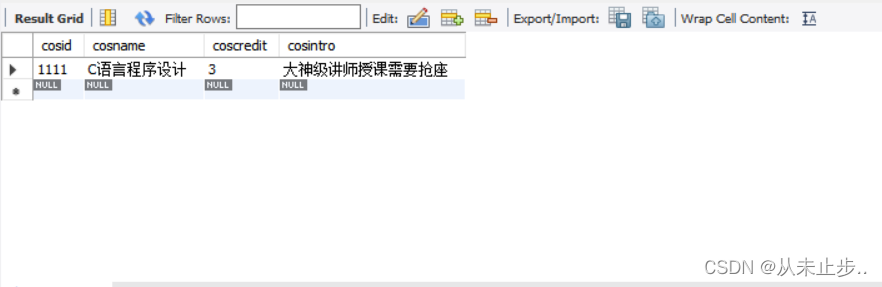
如果想查找第三个,则两个下划线,以此类推。
当要查询的字段中包含下划线:
插入包含下划线的数据:
insert into tbstudent values(1000,'jason_lisa',1, '1978-01-01 00:00:00', '成都市一环路西二段17号',null);
查询该数据:
select *from tbstudent where stuname like '%_%';
查询结果:

此时输出结果将所有数据都显示出来了,并不是我们想要的名字中包含下划线的信息。
解决办法即为:将下划线转义。
命令:
select *from tbstudent where stuname like '%\_%';
-- \表示转义,将其下划线转化为普通的下划线
查询结果:
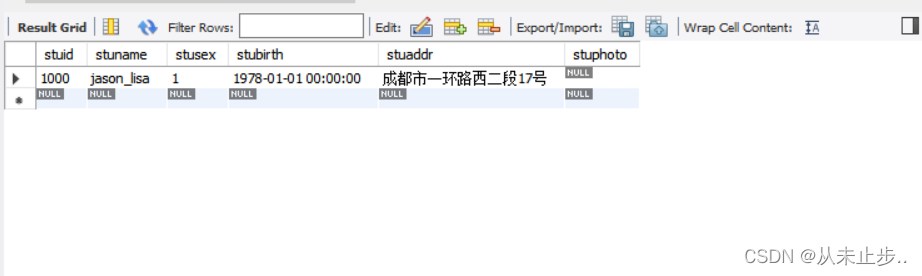
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/81440.html

