
这篇文章,我们将介绍如何编写独立的程序,对获取的数据进行可视化,而这个程序将使用Web应用程序编程接口(API)自动请求网站的特定信息,而不是整个网页,再对这些信息进行可视化。
使用Web API:
Web API是网站的一部分,用于与使用具体URL请求特定信息的程序交互,这种请求称为API调用,请求的数据将以易于处理的格式(如JSON或CSV)返回,依赖于外部数据源的大多数应用程序依赖于API调用,如集成社交媒体网络的应用程序。
Git和GitHub:
GitHub是一个使程序员之间能够协作开发项目的网站,它的名字源于Git,Git是一个分布版本控制系统,协助人们管理为项目所做的工作,避免一个人对项目的内容进行修改之后而影响到其他人对项目的修改,在项目中实现新功能时,Git跟踪你对每个文件所做的修改,确定代码可行后,你提交所做的修改,而Git将记录项目最新的状态。如果不慎操作有误,想撤销所做的修改,你可以返回到以前的任何可行状态,GitHub上的项目都存储在仓库中,仓库包含了与项目相关联的一切,例如:代码,项目参与者的信息,问题以及bug等。
使用API调用请求资源:
GitHub的API能够通过API调用来请求各种信息,调用API的方法:打开该网站!
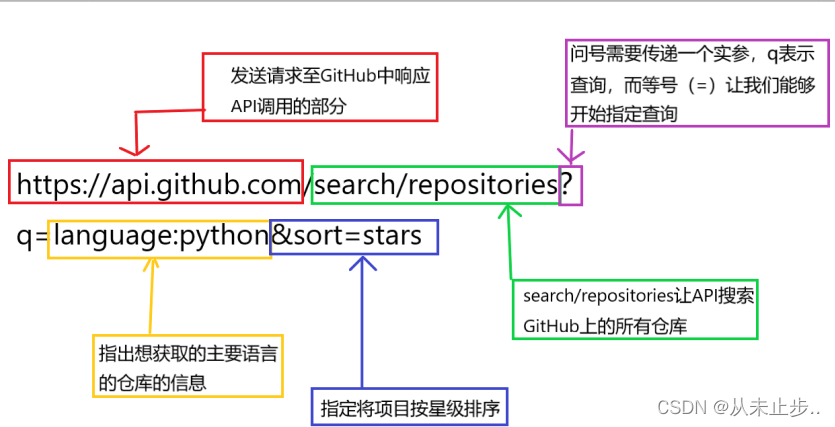
https://api.github.com/search/repositories?q=language:python&sort=stars
下面我们对网址进行分析:
 打开之后在文件的第一行,就呈现给我们截至目前为止,GitHub总共有9165860个Python项目。
打开之后在文件的第一行,就呈现给我们截至目前为止,GitHub总共有9165860个Python项目。
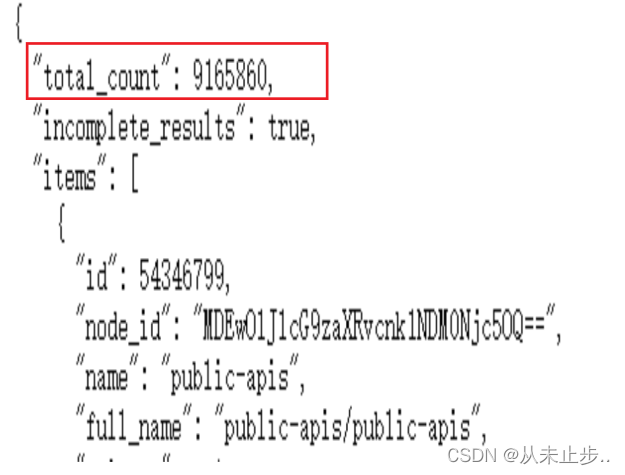
从上面的响应文件,我们会发现,该URL并不适合人工输入,因为它采用了适合程序处理的格式,由第二行的incomplete_results的值为False可知,该请求是成功的。如果GitHub无法处理该API,此处返回的值将为true.而items则包含了GitHub上最受欢迎的Python项目的详细信息。
Requests包:
Requests包能够让Python程序向网站请求信息并检查返回的响应,首先我们先来安装Requests包:
方法,在终端直接输入:
pip install Requests
处理API响应:
以下代码的功能为查找出GitHub上的星级最高的Python项目:
import requests#导入request模块
url="https://api.github.com/search/repositories?q=language:python&sort=stars"#存储API调用的URL
headers={'Accept':'application/vnd.github.v3+json'}#由于GitHub有多个版本,因此在使用的时候需要指定版本
#最新的GitHub最新版本为第三版
r=requests.get(url,headers=headers)
print(f"status code:{r.status_code}")
#将API响应赋给一个变量
response_dict=r.json()
#处理结果
print(response_dict.keys())
status code:200#状态码为200----响应正常
dict_keys(['total_count', 'incomplete_results', 'items'])
requests.get()函数:
该函数的功能为构造一个向服务器请求资源的url对象,这个对象是Requests库内部生成的,它返回的是一个包含服务器资源的Response对象,包含了从服务器返回的所有的相关资源。
url:通过http协议存取资源的一个路径,类似于电脑中的某个文件的路径一样。
这个函数完整的使用方法有三个参数:
requests.get(url,paiams=None,**kwargs)
url:将获取页面的链接
params(可选参数):url中的额外参数,字典或字节流格式
**kwargs:12个控制访问的参数
Requests库中常用的7个主要方法
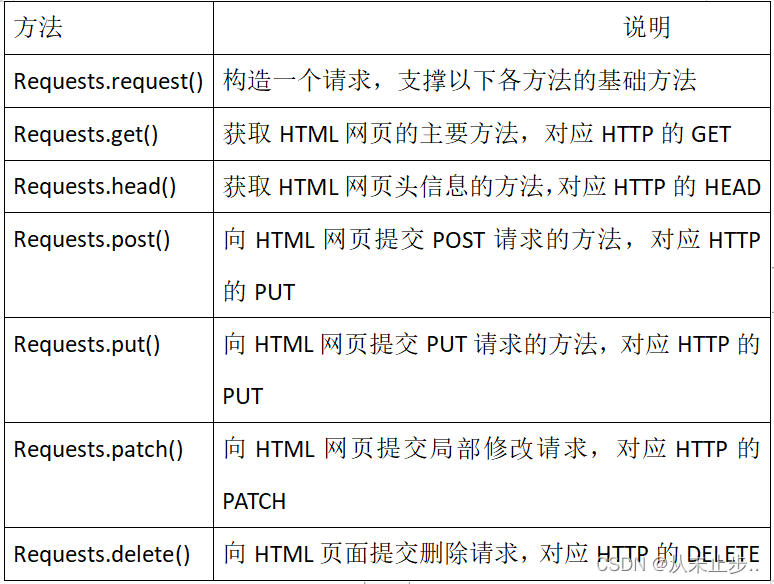 requests方法用于构造一个请求,可以是get/head/post/put等任意一种:
requests方法用于构造一个请求,可以是get/head/post/put等任意一种:
url:请求URL params:请求参数,字典类型,常用于发送GET请求时使用 timeout:超时时间,整数类型
headers:设置请求头
auth:指定登录时的账号和密码,元组类型
verify:请求网站时是否需要验证,布尔类型
proxies:设置代理
cookies:cookies值
allow——redirects:布尔值,默认为True,重定向开关
常见的网页返回状态码的含义:
关于常见的网页返回状态码及其含义在下面这篇文章中有详细介绍:
https://blog.csdn.net/Dontla/article/details/114526790?utm_source=app&
app_version=5.5.0&code=app_1562916241&uLinkId=usr1mkqgl919blen
处理响应字典 :
将API调用返回的信息储存到字典后,就可以处理其中的数据了。
import requests
#执行并存储响应
url="https://api.github.com/search/repositories?q=language:python&sort=stars"
headers={'Accept':'application/vnd.github.v3+json'}
r=requests.get(url,headers=headers)
print(f"status code:{r.status_code}")
#将响应赋给一个变量
response_dict=r.json()
print(f"Total respositories:{response_dict['total_count']}")#打印包含的项目数量
#探索有关仓库的信息
repo_dicts=response_dict['items']
print(f"Repositories returned:{len(repo_dicts)}")#输出包含的键数
repo_dict=repo_dicts[0]#研究第一个仓库
print(f"\nkeys:{len(repo_dict)}")
for key in sorted(repo_dict.keys()):
print(key)
status code:200
Total respositories:9266272
Repositories returned:30
keys:79
allow_forking
archive_url
archived
assignees_url
blobs_url
branches_url
---snip---
id
is_template
issue_comment_url
issue_events_url
issues_url
keys_url
labels_url
language
---snip---
打印仓库中某一个项目的详细信息:
这里我们以第一个仓库进行举例:
import requests
#执行并存储响应
url="https://api.github.com/search/repositories?q=language:python&sort=stars"
#让项目按照星级进行排序
---snip---
repo_dict=repo_dicts[0]
print("\n关于第一个仓库的信息:")
print(f"Name:{repo_dict['name']}")
print(f"Owner:{repo_dict['owner']['login']}")
print(f"Stars:{repo_dict['stargazers_count']}")
print(f"Repository:{repo_dict['html_url']}")
print(f"Created:{repo_dict['created_at']}")
print(f"updated_at:{repo_dict['updated_at']}")
以下为第一个仓库中最受欢迎的项目的一些信息:
status code:200
Total respositories:9038158
Repositories returned:30
关于第一个仓库的选定信息:
Name:public-apis
Owner:public-apis
Stars:204187
Repository:https://github.com/public-apis/public-apis
Created:2016-03-20T23:49:42Z
updated_at:2022-08-06T01:14:05Z
从上述输出可得,截至目前,GitHub上最受欢迎的项目为public-apis,它的主人是public-apis,并且它获得了20w以上人的喜爱,此外它的创建时间、更新时间等其他的信息都可以被我们查询到,因篇幅有限,这里就不过多举例了。
概述最受欢迎的仓库:
import requests
#执行并存储响应
url="https://api.github.com/search/repositories?q=language:python&sort=stars"
---snip---
repo_dicts=response_dict['items']
print(f"Repositories returned:{len(repo_dicts)}")
#涵盖多个仓库的特定信息
for repo_dict in repo_dicts:
print('\n')
print(f"Name:{repo_dict['name']}")
print(f"Owner:{repo_dict['owner']['login']}")
print(f"Stars:{repo_dict['stargazers_count']}")
print(f"Repository:{repo_dict['html_url']}")
print(f"description:{repo_dict['description']}")
status code:200
Total respositories:8721437
Repositories returned:30
Name:public-apis
Owner:public-apis
Stars:204194
Repository:https://github.com/public-apis/public-apis
description:A collective list of free APIs
Name:awesome-python
Owner:vinta
Stars:136472
Repository:https://github.com/vinta/awesome-python
description:A curated list of awesome Python frameworks, libraries, software and resources
---snip---
Name:black
Owner:psf
Stars:28763
Repository:https://github.com/psf/black
description:The uncompromising Python code formatter
通过上述输出,我们能够了解到根据受欢迎程度排列的项目的名称,喜爱的人数等等。
但,这还不够清晰,为了使数据更加清晰,直白,我们可通过之前学习过的可视化对数据进行分析。
使用Plotly可视化仓库:
plotly.graph_objs和plotly.express的区别:
plotly.graph_objs适用于数据为list的时候使用,而plotly.express适用于数据为dataframe的时候使用。
import requests
from plotly.graph_objs import Bar #Bar:绘制柱状图
from plotly import offline
#执行并存储响应
---snip---
print(f"Repositories returned:{len(repo_dicts)}")
#研究仓库
repo_names,stars=[],[]
for repo_dict in repo_dicts:
repo_names.append(repo_dict['name'])
stars.append(repo_dict['stargazers_count'])
data=[{
'type':'bar',
'x':repo_names,
'y':stars,
}]
my_layout={
'title':'GitHub上最受欢迎的Python项目',
'xaxis':{'title':'Repository'},
'yaxis':{'title':'Stars'},
}
fig={'data':data,'layout':my_layout}
#offline.plot()函数需要一个包含数据和布局对象的字典,并且还需要传入一个文件名,此后会将该图表放入该文件中
offline.plot(fig,filename='python_repos.html')
生成的图表如下所示,我们能够清晰的知道那个项目最受欢迎。
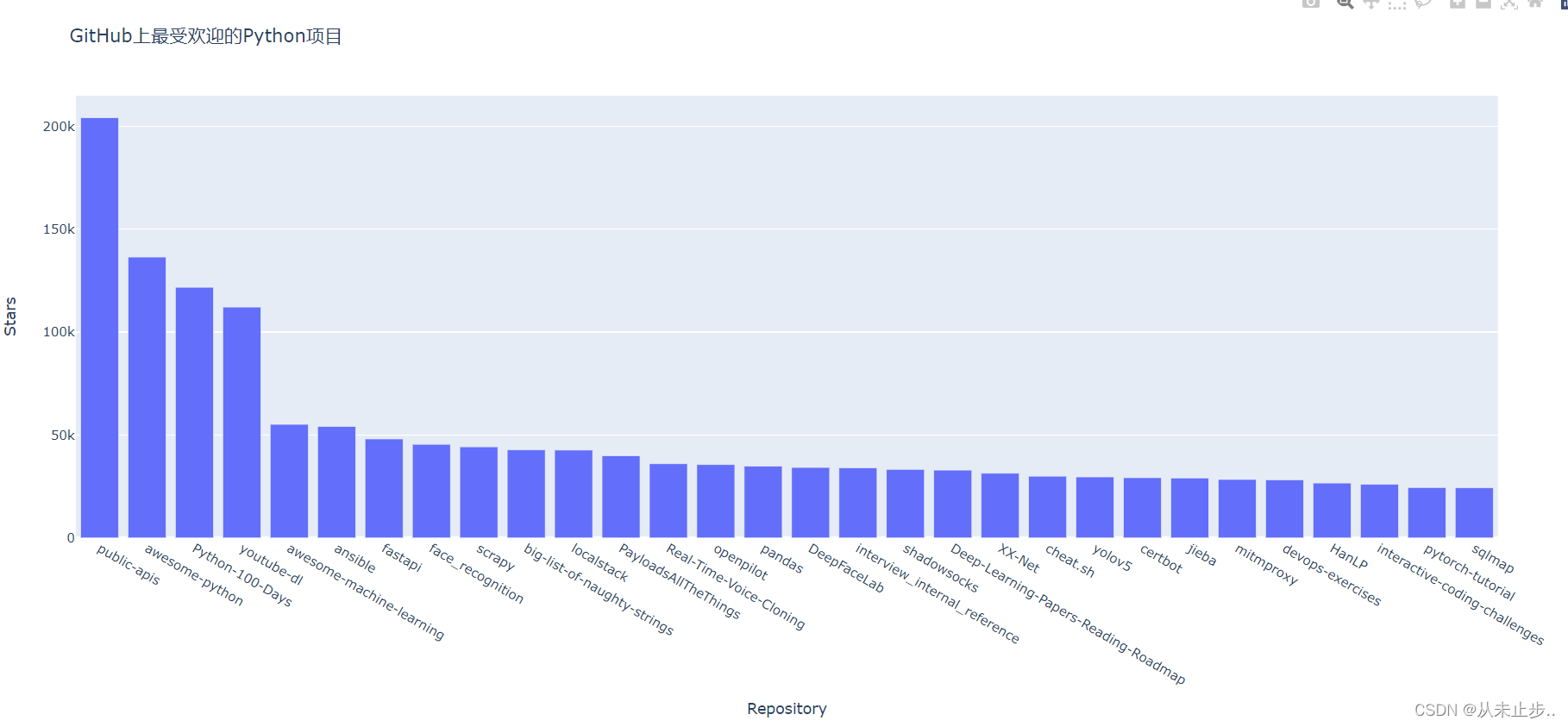
但其实这并不是最完美的,我们在前面的文章有讲到过图表的字号,颜色等等,都可以根据我们喜欢的进行修改,那么,下面我们对图表进行美化。
美化plotly图表:
首先,我们先来美化条形:
data=[{
'type':'bar',
'x':repo_names,
'y':stars,
#使用参数marker对条形进行设计
'marker':{
'color':'rgb(245, 255, 250)',
'line':{'width':1.5,'color':'rgb(25,25,25)'}#条形框边的颜色
},
'opacity':0.6,#不透明度的设置
}]
接下来,我们来美化横纵坐标签:
my_layout={
'title':'GitHub上最受欢迎的Python项目',
'titlefont':{'size':24},#修改标题的字号大小
#修改横纵轴标签的文字大小和颜色
'xaxis':{
'title':'Repository',
"titlefont":{"size":24},
"tickfont":{"size":14},
'color':'rgb(186, 85, 211)',
},
'yaxis':{
'title':'Stars',
"titlefont":{'size':24},
"tickfont":{"size":14},
'color': 'rgb(0, 128, 0)',
},
}
输出结果如下所示:
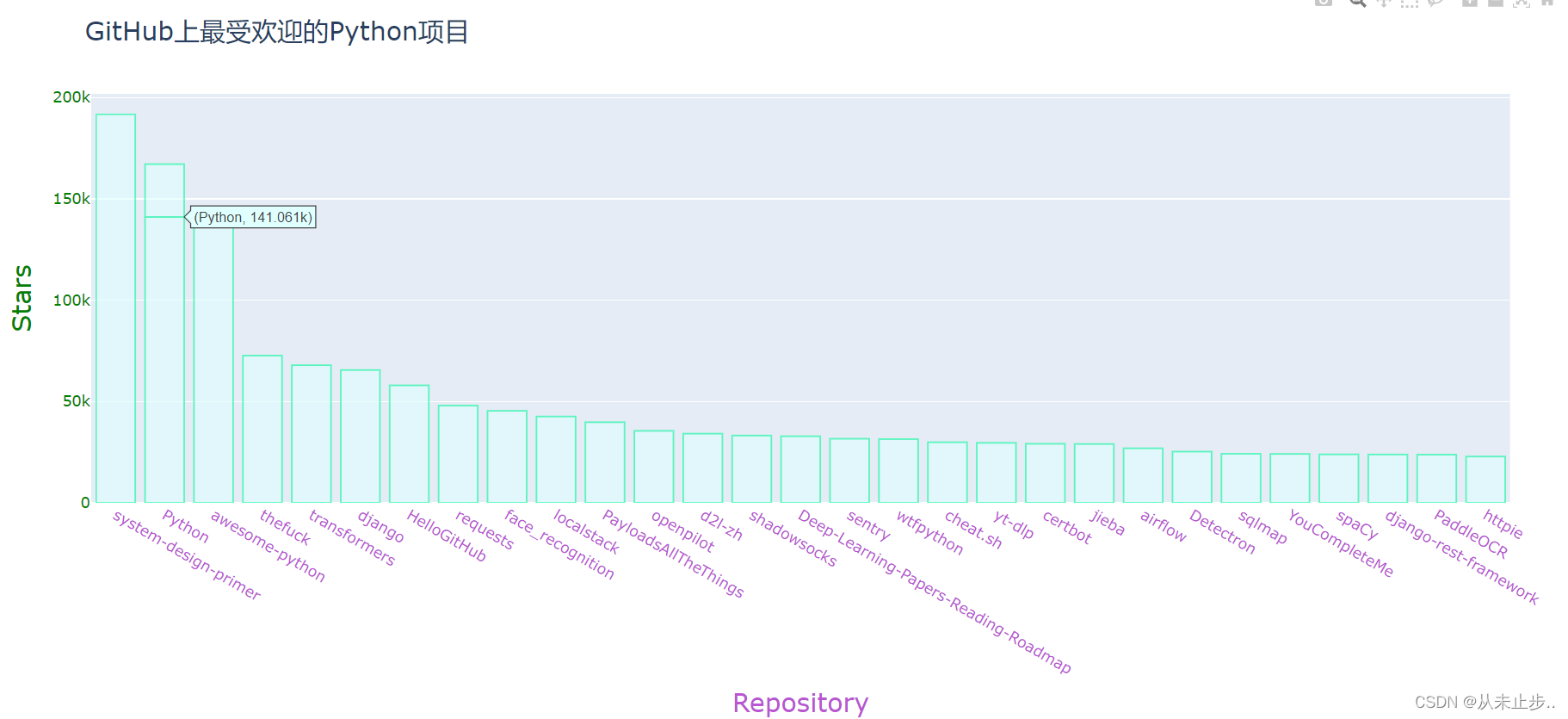
关于颜色RGB颜色表的总结,在下面这篇文章中有详细介绍:
http://t.csdn.cn/gxy8V
监视API的速率限制:
大多数API都存在,在特定的时间内可执行的请求数存在限制,如果我们想知道是否接近这种限制,可通过下面这个网站进行查看:
http://api.github.com/rate_limit
打开之后,你会看到下述内容:
{"resources":{
"core":{"limit":60,
"remaining":60,
"reset":1659771035,
"used":0,
"resource":"core"},
---snip---
},
"search":{
"limit":10,
"remaining":10,
"reset":1659767495,
"used":0,
"resource":"search"}
},
---snip---
但这些信息并不都是我们所关心的,我们所关心的是搜索API的速率限制,以下即是:
"search":{
"limit":10,#极限为每分钟10个请求
"remaining":10,#在当前分钟内,还可执行10个请求
"reset":1659767495,#reset值代表:配额将重置的Unix时间或新纪元时间(1970年1月1日午夜后多少秒)
#用完配额后,你将会收到一条响应,表示API已到达极限,必须等待配额重置
"used":0,
"resource":"search"}
},
注:很多API要求注册获得API密钥后才能执行API调用
添加自定义工具提示:
在Plotly中,将鼠标指向条形将显示其表示的信息,这种操作被称为工具提示。
---snip---
repo_names,stars,labels=[],[],[]#新建一个labels列表,用来存放想在条形图上显示的信息
for repo_dict in repo_dicts:
repo_names.append(repo_dict['name'])
stars.append(repo_dict['stargazers_count'])
owner=repo_dict['owner']['login']
description=repo_dict['description']
#plotly允许在文本元素中使用html代码
label=f"{owner}<br/>{description}"#<br>为html代码中的换行
labels.append(label)
data=[{
'type':'bar',
'x':repo_names,
'y':stars,
'hovertext':labels,#显示labels
'marker':{
'color':'rgb(224, 255, 255)',
'line':{'width':1.5,'color':'rgb(0, 250, 154)'}
},
---snip---
输出如下图所示:
对比于上面的图表,下面的这张图表增加了关于各个项目的描述,这也是我们自定义的工具。
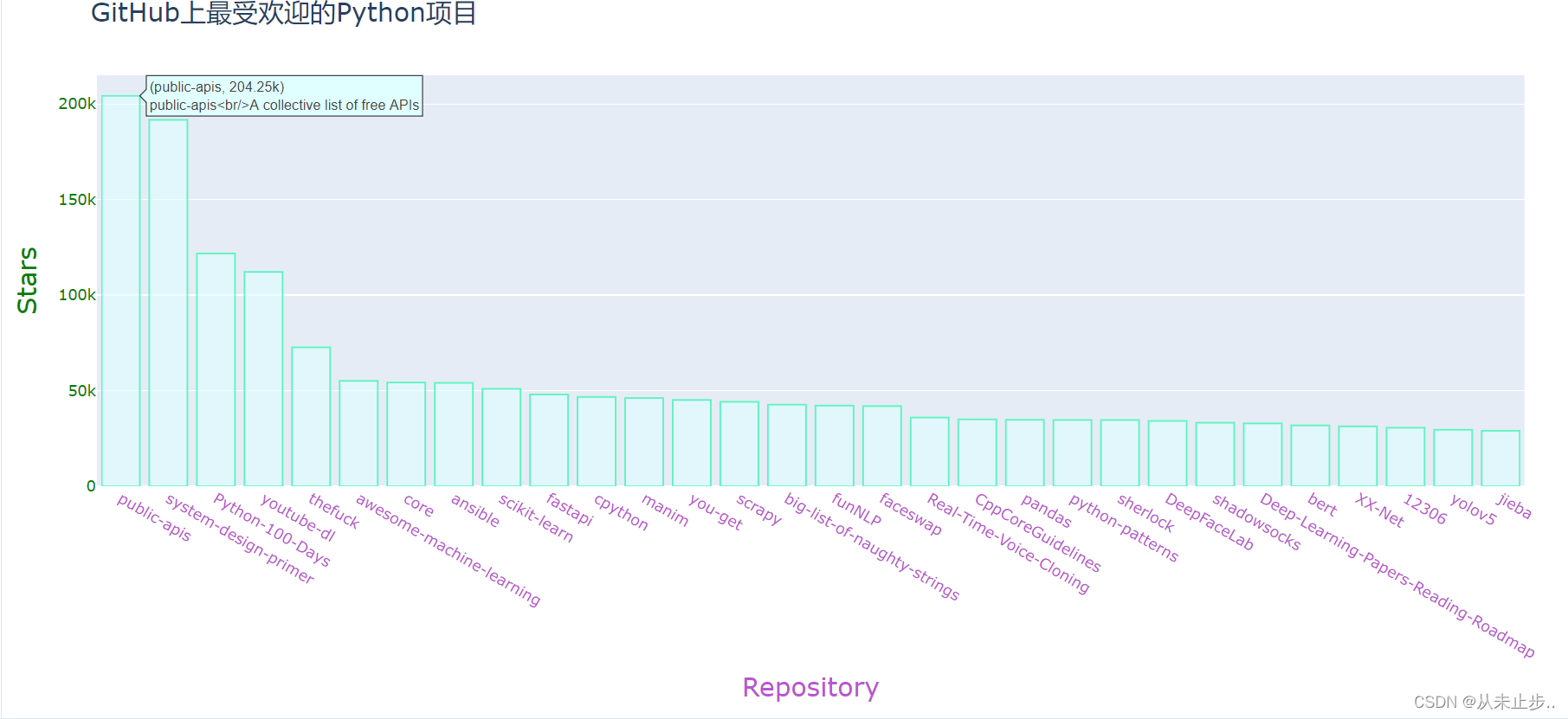
在图表中添加可单击的链接:
---snip---
repo_links,stars,labels=[],[],[]#将repo_name换为repo_links
for repo_dict in repo_dicts:
repo_name=repo_dict['name']
repo_url=repo_dict['html_url']#提取每个项目的URL
repo_link=f"<a href='{repo_url}'>{repo_name}</a>"#html代码中的:<a href=“所要连接的相关地址”>写上你想写的字</a>----加入连接
repo_links.append(repo_link)
stars.append(repo_dict['stargazers_count'])
data=[{
'type':'bar',
'x':repo_links,#横轴的内容也从项目名称变成项目网址
'y':stars,
'hovertext':labels,
'marker':{
'color':'rgb(224, 255, 255)',
'line':{'width':1.5,'color':'rgb(0, 250, 154)'}
},
'opacity':0.6,
}]
---snip---
输出如下图所示:
图表样式几乎没有区别,但此时当我们点击x轴的项目名称时,不仅在左下角显示了该项目的网址,而且页面会直接跳转到该项目。
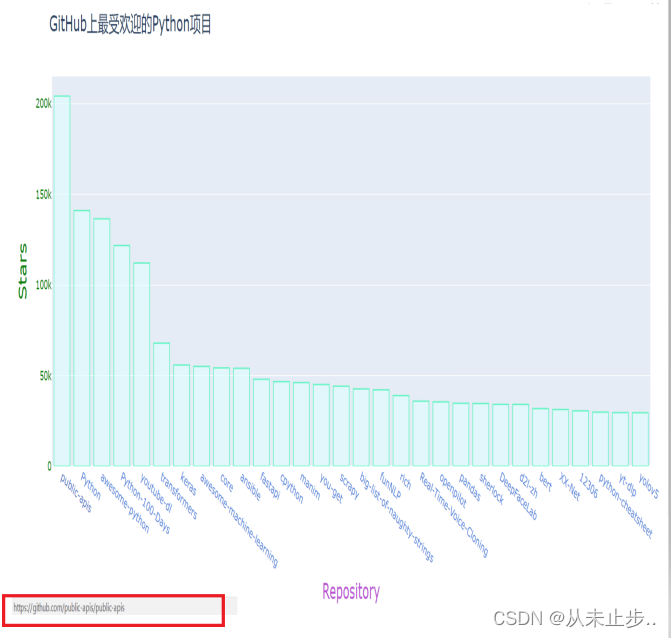
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/81471.html

