
SpringCloud Sleuth Zipkin
文章目录
分布式服务追踪是整个分布式系统中跟踪一个用户请求的过程(包括数据采集,数据传输,数据存储,数据分析,数据可视化),捕获此类跟踪让我们构建用户交互背后的整个调用链的视图,这是调试和监控微服务的关键工具。SpringCloud Sleuth是SpringCloud为分布式服务跟踪提供的解决方案,有了它,我们可以提供链路追踪,可视化各个阶段耗时,进行性能分析,数据分析,优化链路等。
一,Sleuth详解
1.1 基本术语
- Span:基本工作单元,发送一个远程调用任务,就会产生一个span。Span是一个64位ID唯一标识的。
- Trace:一系列span组成的一个树状结构。请求一个微服务系统的API接口,这个API接口需要调用多个微服务,调用每个微服务都会产生一个新的span,所有由这个请求产生的span组成了这个Trace。
- Annotation:用来及时记录一个事件的,一些核心注解用来定义一个请求的开始和结束,这些注解包括:
- cs:Client Sent,客户端发送一个请求,这个注解描述了这个Span的开始
- sr:Server Received,服务端获得请求并准备开始处理它,如果将sr减去cs时间戳便可获得网络传输的时间
- ss:Server Send,服务端发送响应,该注解表明请求处理的完成。如果ss的时间减去sr的时间戳,就可以获得服务器请求的时间
- cr:Client Received,客户端接收响应,此时Span结束。如果cr的时间戳减去cs的时间戳便可以得到整个请求所消耗的时间。
在Springcloud中实现Sleuth日志追踪,需要核心依赖spring-cloud-starter-sleuth
这个依赖项会拉取Spring Cloud Sleuth所需的所有核心库,一旦加入这个依赖项服务就会完成以下功能:
(1) 检查每个传入的http服务,并确定调用中是否存在Spring Cloud Sleuth跟踪信息。如果跟踪数据确实存在,则将捕获传递到微服务的跟踪信息,并将跟踪信息提供给服务以进行日志记录和处理。
(2) 将Spring Cloud Sleuth跟踪信息添加到Spring MDC(映射调试上下文,记录日志),以便微服务创建的每个日志语句都添加到日志中。
(3)将Spring Cloud跟踪信息注入服务发出的每个出站http调用以及Spring消息传递通道的消息中。
1.2 剖析Sleuth日志
关于Sleuth日志,在springboot1.x和2.x还是有些许差异的,先看看以下的1.x日志

日志的格式为:[application name, traceId, spanId, export]
说明:
- application name:[应用程序名称],正在记录的服务名称
- traceId:[跟踪ID],用户请求的唯一标识符,将在该请求中所有服务调用中携带。是表示整个事务的唯一编号。
- spanId:[跨度ID],在整个用户请求中每个组成部分的唯一标识符,对于多服务调用,在用户事务中每个服务调用都会有一个跨度ID。
- export:[发送到zipkin的标志],指示是否将数据发送到zipkin服务器以进行跟踪。在大容量服务中,生成的跟踪数据量有可能是海量的,并且不会增加大量的价值,Sleuth跟踪块末尾的true/false指示器用于指示是否将跟踪信息发送到zipkin。
2.x的日志与1.x的类似,但是少了export这一项
2021-10-23 09:56:18.884 INFO [tools-task,,] 77032 --- [-192.168.57.153] o.s.web.servlet.DispatcherServlet : Completed initialization in 2 ms
2021-10-23 09:56:30.717 INFO [tools-task,72ea16aefbc4068d,4e2376cf0874d06c] 77032 --- [nio-8083-exec-1] com.lmc.task.controller.TestController : 调用了TestController的api接口
2021-10-23 10:01:18.011 INFO [tools-task,,] 77032 --- [trap-executor-0] c.n.d.s.r.aws.ConfigClusterResolver : Resolving eureka endpoints via configuration
二,搭建Zipkin服务端
由于Springboot2.x开始不支持手动创建zipkin-server,因此我们可以去官方直接下载zipkin-server,直接启动(在这里我下载的时2.12.9版本)
java -jar zipkin-server-2.12.9-exec.jar
此时,发布的zipkin-server可以通过本地 http://127.0.0.1:9411/ 访问
三,各服务配置Sleuth
部署zipkin-server之后,就可以对gateway,provider,consumer等其他服务进行添加zipkin支持了,以便zipkin-server可以进行链路跟踪。
3.1 依赖导入
<!-- 链路追踪 -->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
<version>2.2.4.RELEASE</version>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-sleuth-zipkin</artifactId>
<version>3.0.0</version>
</dependency>
注意,本人springboot版本为2.4.5,springcloud版本为2020.0.0
3.2 配置文件
spring:
# 链路追踪
zipkin:
base-url: http://localhost:9411 # 设置zipkin服务的地址
sender:
type: web # 设置使用http的方式传输数据
sleuth:
sampler:
probability: 1 # 采样比例0-1,1.x版本需要设置为sleuth.sampler.percentage=1.0
配置完成之后,发布,然后开始请求发送,即可以通过 http://127.0.0.1:9411/ 查看链式调用情况。
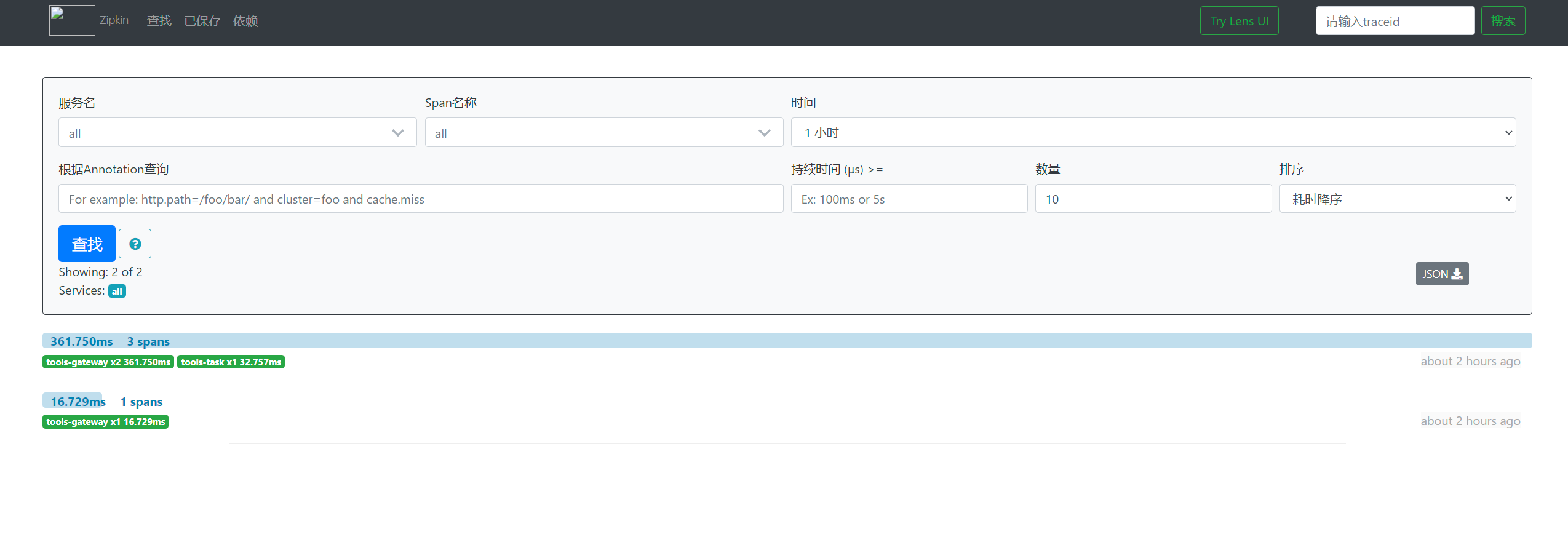
案例在 https://gitee.com/lmchh/lmc-tools 上
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/81615.html

