
该文记录一些本人关心的前沿技术,做一些调研摘录,欢迎各位评论指正。文章将持续更新。
一、半导体技术
二、互联网技术
2.1 Web3.0
什么是web3.0
2014年,以太坊联合创始人加文·伍德第一次公开提出Web3.0的概念,让用户参与的一切互联网交易、数据传输等行为,尝试消除“中间人”的概念。如图是web技术发展的进程,由此看出web技术是伴随着人们使用网络的需求的改变而改变的,随着用户在网络上的数字行为作为数据被各个互联网平台未经用户的允许记录下来并作为平台私有资产,web3.0由加密货币巨头首次提出来也无可厚非。

参考链接:什么是web3.0
三、数据中心技术
3.1 计算设备互连协议
本节将主要讨论片外总线互联技术,同时也会分析这类互联技术的底层协议栈。如图所示为当今主流的不同层次的片内片外互联技术。

3.1.1 片间互连技术
通用互联协议
-
PICe
AMD多路CPU互联解决方案
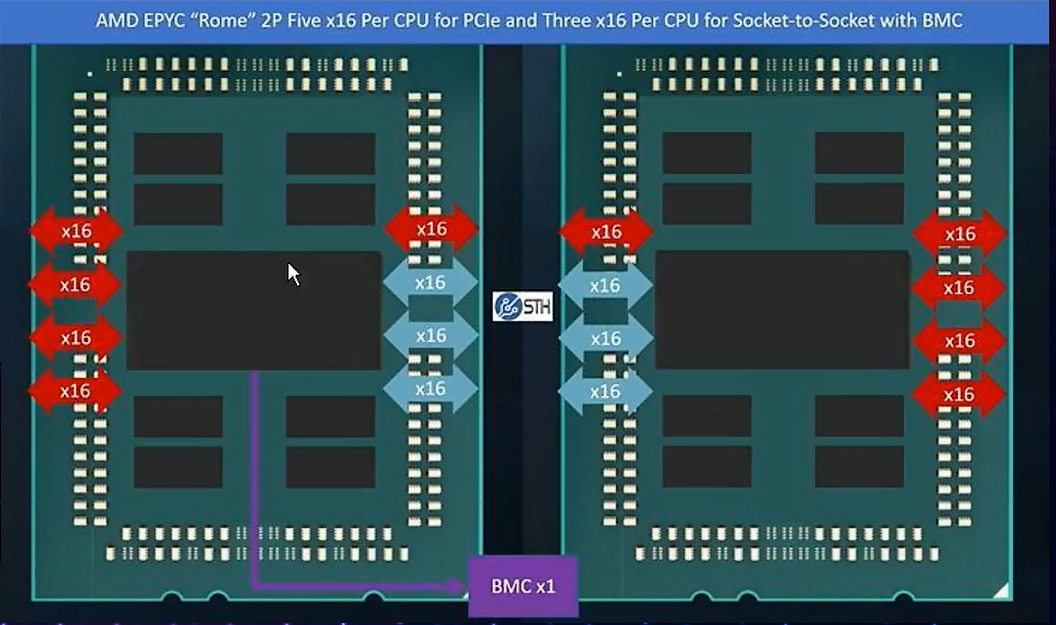


-
CXL技术
CXL,全称Compute Express Link,该技术由Intel牵头开发用于高性能计算、数据中心,主要解决处理器、加速器和内存之间的cache一致性问题,可消除CPU、专用加速器的计算密集型工作负载的传输瓶颈,显著提升系统性能。

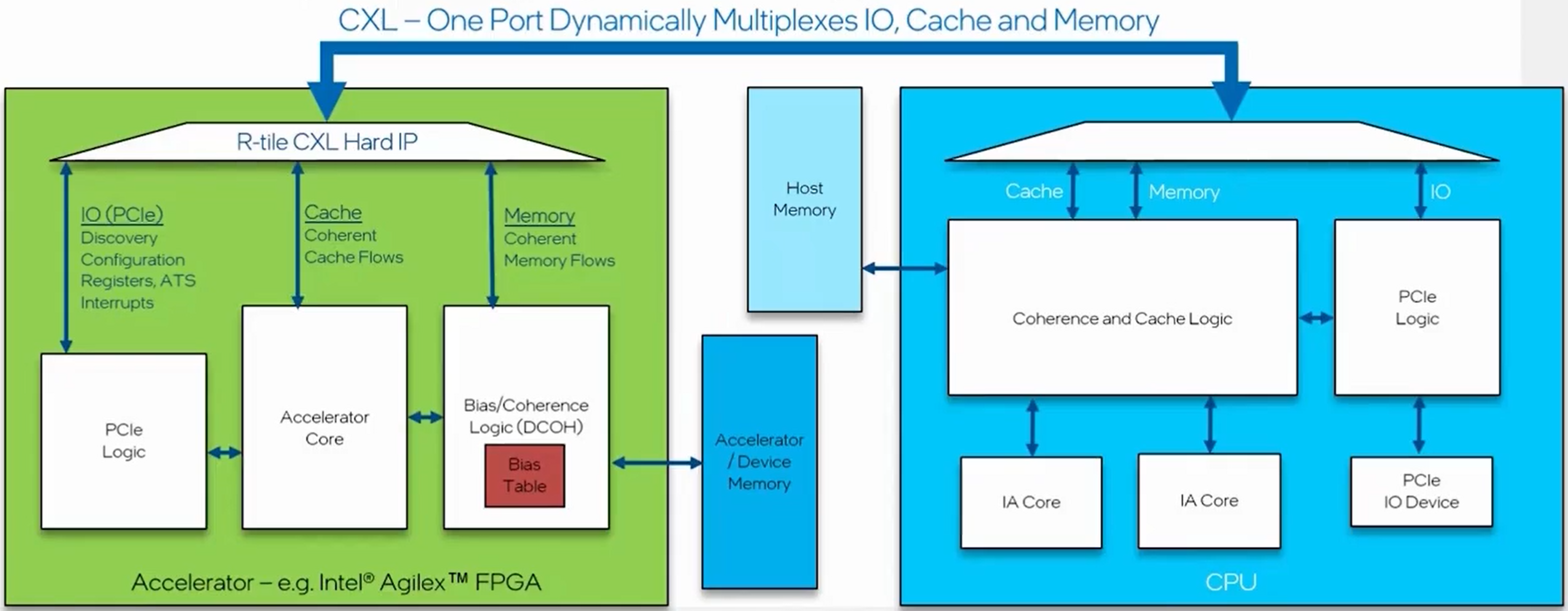
该协议基于PICe技术,完全兼容PCIe5.0,新协议的物理层直接采用于PCIe5.0,在事务层和数据链路层有所增加。增加了FlexBus用作CXL的互联。如下图所示,CXL.io使用PCIe的事务层和链路层,CXL.cache和CXL.mem使用自己的事务层和链路层,CXL_ARB/MUX模块将两组数据流交织,实现三组子协议的复用。

-
CXL定义了三个子协议,三个子协议在工作时可以动态切换:
cxl.io: PCIe5.0的增强版本,用于初始化、寄存器访问、中断处理、MMIO事务等,用于CPU访问外设的配置空间
cxl.cache:通过主机与设备的交互,引起cxl设备使用请求和响应的方式缓存主机侧的内存,用于外设访问CPU的内存
cxl.mem:主机处理器使用加载和存储命令的方式访问CXL连接设备的内存,同时CXL协议可以用作内存扩展,用于CPU访问外设的内存 -
CXL 1.0/1.1设备
Type1设备:数据分析应用
Type2设备:重型加速器,即高带宽的内存应用场景,用于数据库加速分析功能
Type3设备:内存缓冲区,扩展主机的内存空间(内存资源池化?)


参考链接:CXL 2.0白皮书
-
CCIX技术
该技术用于跨封装芯片间互联,打造异构封装系统,并支持完整的缓存一致性。 -
RDMA技术
CPU间的互联
CPU间的互联分为片内多核的互联和片外多路CPU的互联
-
QPI
2008年Intel提出的 多路CPU互联解决方案
一条8GT/s的QPI的单向带宽:8GT/s16bit/8=16GB/s
一条9.6GT/s的QPI的单向带宽:9.6GT/s16bit/8=19.2GB/s -
UPI
Intel Icelake多路CPU互联解决方案,用于取代QPI技术,拥有更高的通信速率、效率和更低的功耗。
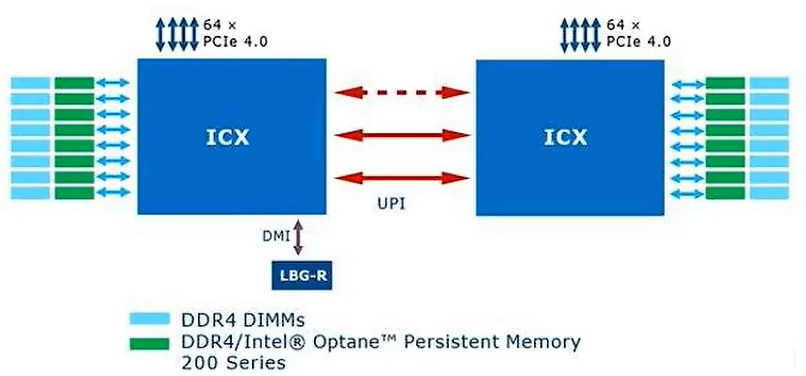 一条10.4GT/s的UPI总线带宽为:10.4 GT/s * 16bit / 8bit = 20.8 GB/s
一条10.4GT/s的UPI总线带宽为:10.4 GT/s * 16bit / 8bit = 20.8 GB/s
GPU间的互联
- NVLink和NVSwitch
NVLink是NVIDIA推出的一种高速的、直接的GPU到GPU的互联技术,NVSwitch是将多条NVLink整合,在单个节点内以NVLink的速度实现多对多的GPU通信的芯片,类似PCIe技术和PCIe switch的关系,但与传统的 PCIe 系统解决方案相比,NVLink能为多 GPU 系统提供更快速的替代方案。
如图所示是NVIDIA发布的三代NVLink信息,每代的link都有8个lane,因此带宽极高。
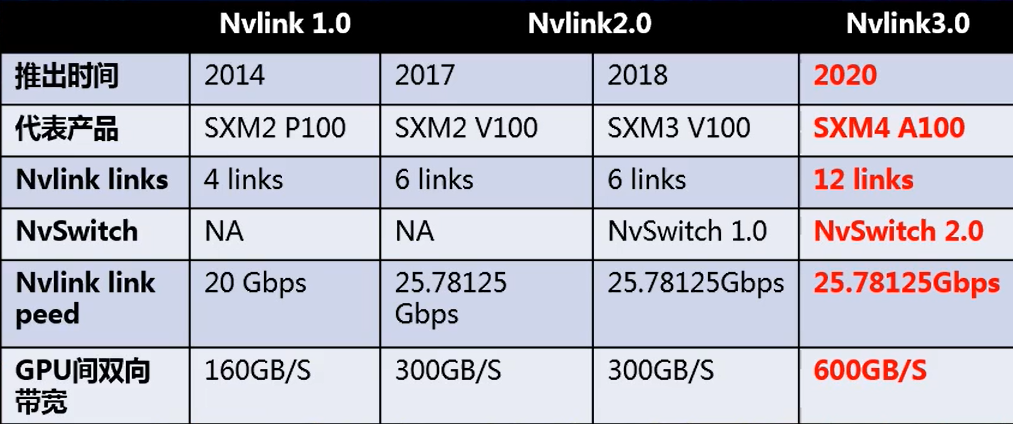
参考链接:NVIDIA NVlink和NVswitch
- 缺点:软件生态支持较少(NVIDIA的NVLink的驱动闭源导致操作系统中没有对NVLink驱动支持?)
3.1.2 片内die间互连技术
- UCIe
Universal Chiplet Interconnect express
3.1.3 die内互联技术
主要采用IP互联技术(如总线、Crossbar、NoC等)
3.2 互联设备
现代数据中心的计算设备包含了CPU、GPU、ASIC等设备,通过运用上述互连技术设计的设备可以作为计算机集群中的辅助设备,用于解决多节点服务器互联效率等问题,实现运算负载均衡。
以下设备将按厂商首发的大致时间顺序介绍。
-
SmartNIC
SmartNIC卡的应用在互联网络中较为局限,该卡将IO访问从CPU中offload(卸载)出来,如下图所示:
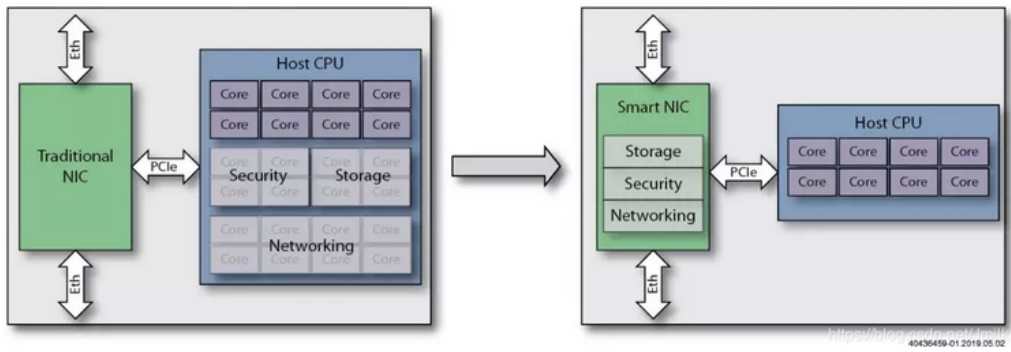 参考链接:一文读懂SmartNIC
参考链接:一文读懂SmartNIC -
DPU
最先由NVIDIA首发,此后Intel等厂商也推出了自家的DPU芯片,该芯片功能与SmartNIC卡类似,能够从CPU上卸载关键的网络、存储和安全任务,降低CPU的开销。
最高带宽可达200Gb/s。
参考链接:
从DPU看大芯片的发展趋势
从DPU的崛起谈谈计算体系变革(一)
从DPU的崛起谈谈计算体系变革(二)
从DPU的崛起谈谈计算体系变革(三)
从DPU的崛起谈谈计算体系变革(四) -
IPU
该芯片在2020年由Intel推出的一款数据中心基础架构处理器,能够通过网络虚拟化、存储虚拟化、网络存储管理以及安全等功能,加速网络基础设施,释放CPU核来提高应用程序性能。
最高带宽可达200Gb/s。 -
XPU
国内技术厂商边缘智芯推出了XPU数据交换芯片,CPU处理速度已经落后设备流量(网卡)和处理能力(GPU),高速设备管理芯片(PCIe Controller)又将从CPU中分离出来,成为独立芯片XPU
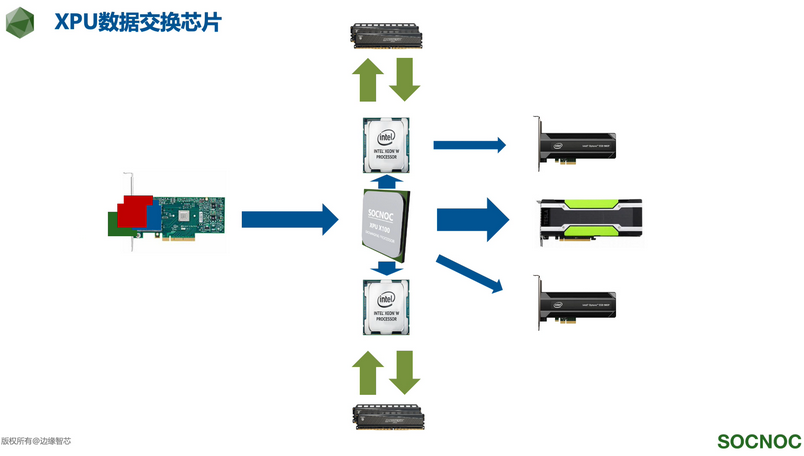
参考链接:从系统架构角度谈谈PCIe和XPU芯片
- CIPU
阿里云推出的云基础设施处理器,作为数据中心的管控芯片,其本质与IPU并没有区别,但特别强调了网络吞吐的能力,且主要搭配阿里云的飞天操作系统使用。 - NVswitch
四、人工智能技术
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/82455.html

