
传送门:
MySQL进阶【二】—— MySQL的索引结构 https://blog.csdn.net/shehuinidaye/article/details/108691042
MySQL进阶【三】—— Explain详解与实战https://blog.csdn.net/shehuinidaye/article/details/108692631
MySQL进阶【四】—— MySQL索引优化实战https://blog.csdn.net/shehuinidaye/article/details/108782534
MySQL 架构分层

server 层
server层主要包括连接器、词法分析器、查询优化器、执行器
连接器
- 主要用途,客户端连接到mysql的服务器
mysql -u -h -p //连接mysql的命令
词法分析器
- 将一条SQL语句拆分,结构化,形成语法树。语法不正确、字段或表名不正确,会在这个阶段被发现,并进行错误提示
1、词法分析
2、语法分析
3、语义分析
4、构造语法树
5、生成执行计划
6、计划的执行
- 语法树是如何生成的
创建一张表
CREATE TABLE `test` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB AUTO_INCREMENT=9 DEFAULT CHARSET=utf8;语法树生成可以使用idea的插件antlr4
- 词法分析器的执行过程
- 语法树的结构:将关键字、表名、字段名、都分别放在不同的位置,以便在SQL执行时,执行器快速取到相应的

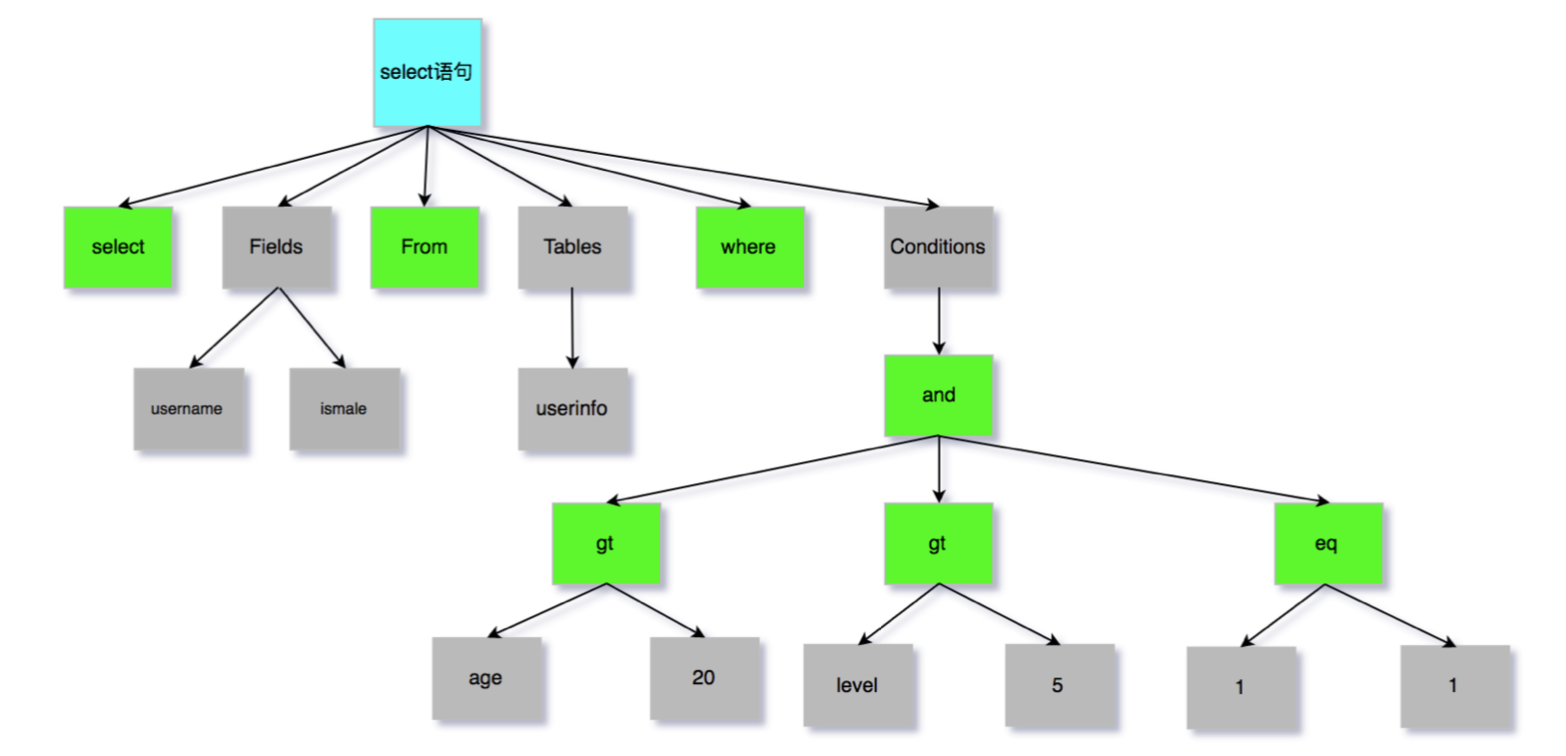
优化器
- 在经过词法分析器后,mysql知道一条语句准备做什么。但是在做之前,会先做一次优化,包括是否走索引、如何选择索引、表连接(inner join)时驱动表的选择等等。
- 在此期间优化器会通过一系列的计算,最终形成一个带有cost成本的
- 数据结构如下
“steps”: [
{
“join_preparation”: {
“select#”: 1,
“steps”: [
{
“expanded_query”: “/* select#1 / selecttest.idASid,test.nameASnamefromtestwhere (test.id= 1)”
}
] / steps /
} / join_preparation /
},
{
“join_optimization”: {
“select#”: 1,
“steps”: [
{
“condition_processing”: {
“condition”: “WHERE”,
“original_condition”: “(test.id= 1)”,
“steps”: [
{
“transformation”: “equality_propagation”,
“resulting_condition”: “multiple equal(1,test.id)”
},
{
“transformation”: “constant_propagation”,
“resulting_condition”: “multiple equal(1,test.id)”
},
{
“transformation”: “trivial_condition_removal”,
“resulting_condition”: “multiple equal(1,test.id)”
}
] / steps /
} / condition_processing /
},
{
“substitute_generated_columns”: {
} / substitute_generated_columns /
},
{
“table_dependencies”: [
{
“table”: “test”,
“row_may_be_null”: false,
“map_bit”: 0,
“depends_on_map_bits”: [
] / depends_on_map_bits /
}
] / table_dependencies /
},
{
“ref_optimizer_key_uses”: [
{
“table”: “test”,
“field”: “id”,
“equals”: “1”,
“null_rejecting”: false
}
] / ref_optimizer_key_uses /
},
{
“rows_estimation”: [
{
“table”: “test”,
“rows”: 1,
“cost”: 1,
“table_type”: “const”,
“empty”: true
}
] / rows_estimation /
}
] / steps /,
“empty_result”: {
“cause”: “no matching row in const table”
} / empty_result /
} / join_optimization /
},
{
“join_execution”: {
“select#”: 1,
“steps”: [
] / steps /
} / join_execution /
}
] / steps */- 这里不重点介绍,后面索引选择的地方会稍微详细一点说明这个过程
执行器
- 执行器调用引擎层,执行SQL语句,并获取引擎层返回的结构化数据
select * from test where id=1;
- 调用 InnoDB 引擎接口取这个表的第一行,判断 ID 值是不是 10,如果不是则跳过,如果是则将这行存在结果集中;
- 调用引擎接口取“下一行”,重复相同的判断逻辑,直到取到这个表的最后一行。
- 执行器将上述遍历过程中所有满足条件的行组成的记录集作为结果集返回给客户端。
查询缓存
- 这是一个非常鸡肋的功能,在mysql8.0里面已经取消了查询缓存
- 大概实现和我们平时是用redis类似,一条SQL作为key,如果下次查询key命中,则直接返回数据,无需经过引擎层,当数据修改时,缓存会被失效掉,且缓存命中率不高,这导致这个功能逐渐被弃用
引擎层
存储引擎层负责数据的存储和提取。其架构模式是插件式的,支持 InnoDB、MyISAM、Memory 等多个存储引擎。现在最常用的存储引擎是 InnoDB,它从 MySQL 5.5.5 版本开始成为了默认存储引擎。也就是说如果我们在create table时不指定 表的存储引擎类型,默认会给你设置存储引擎为InnoDB。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/83669.html

