
前期准备:
pom.xml
<!--
需要注意spring-boot-starter-parent版本问题可能调用会出现错误
如: Received handshake message from unsupported version: [5.0.0] minimal compatible version is: [6.8.0]
-->
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.2.13.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
可以比对官方文档中的spring-boot-starter-parent和自己安装的ES版本是否一致
最开始我使用的spring-boot-starter-parent版本是2.0.6的就提示
Received handshake message from unsupported version: [5.0.0] minimal compatible version is: [6.8.0]大致意思就是从不支持的版本收到握手消息:[5.0.0]最小兼容版本是:[6.8.0]以上都可以所以后面改成了2.2.13.RELEASE版本就可以正常插入数据了

application.yml
spring:
data:
elasticsearch:
cluster-name: elasticsearch #名称可以自己取
cluster-nodes: 192.168.0.104:9300 #自己ES的ip
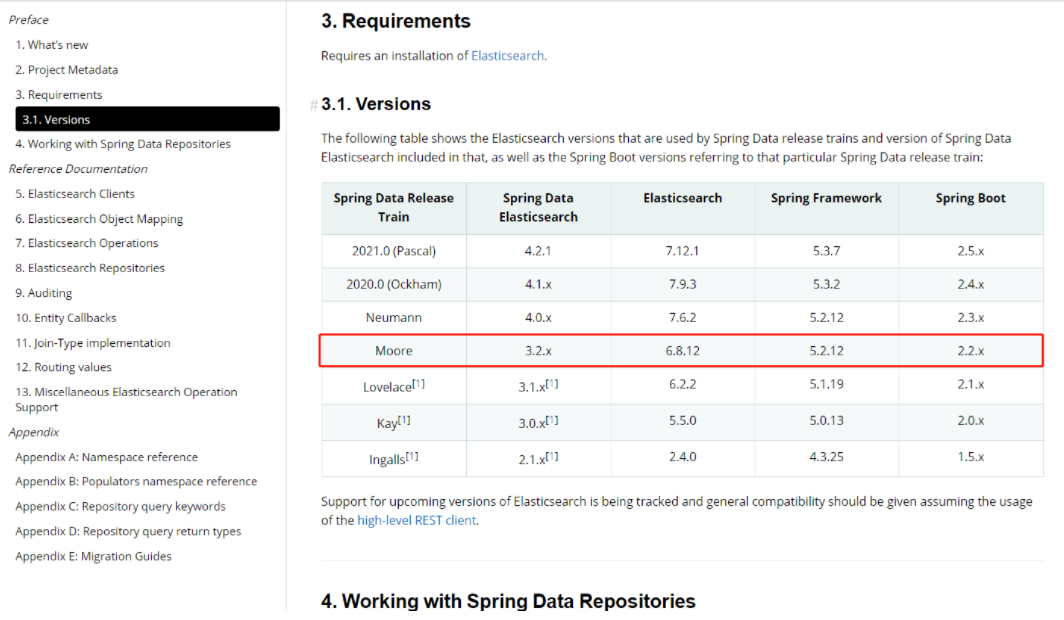
实体类
// 索引库 表名称 分片 副本
@Document(indexName = "item",type = "docs",shards = 1,replicas =0)
public class Item {
@Id
Long id;
// 字段类型Text为了可以分词 使用分词的方式
@Field(type = FieldType.Text,analyzer = "ik_max_word")
String title;//标题
// 字段类型 不可分词,可以参与聚合
@Field(type = FieldType.Keyword)
String category;//分类
@Field(type = FieldType.Keyword)
String brand;//品牌
// 字段类型 基本数据类型long、interger、short、byte、double、float、half_float
@Field(type = FieldType.Double)
Double price;//价格
@Field(type = FieldType.Keyword)
String images;//图片地址
//get/set/toString 无参构造和全参构造省略
}
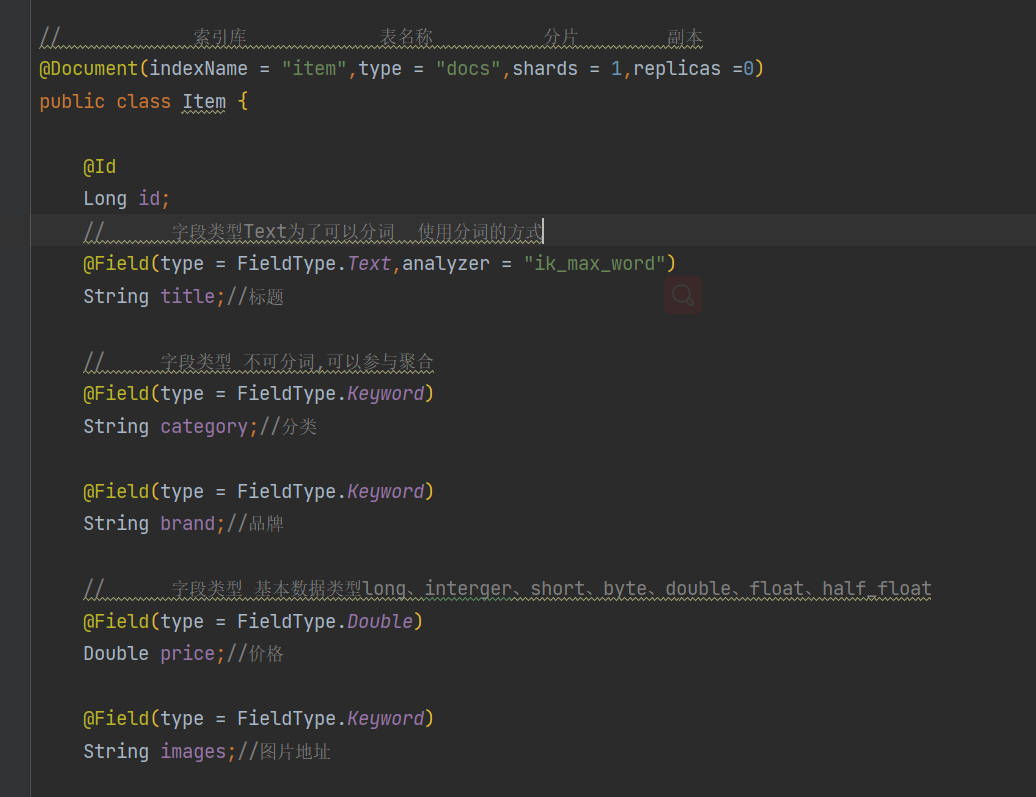
Repository文档操作
实体类接口
通过接口继承ElasticsearchRepository来实现一些增删改功能
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
/**
* 需要继承ElasticsearchRepository来实现一些对ES的增删改功能
*/
public interface ItemRepository extends ElasticsearchRepository<Item,Long> {
}
查看ElasticsearchRepository接口内部需要指定泛型
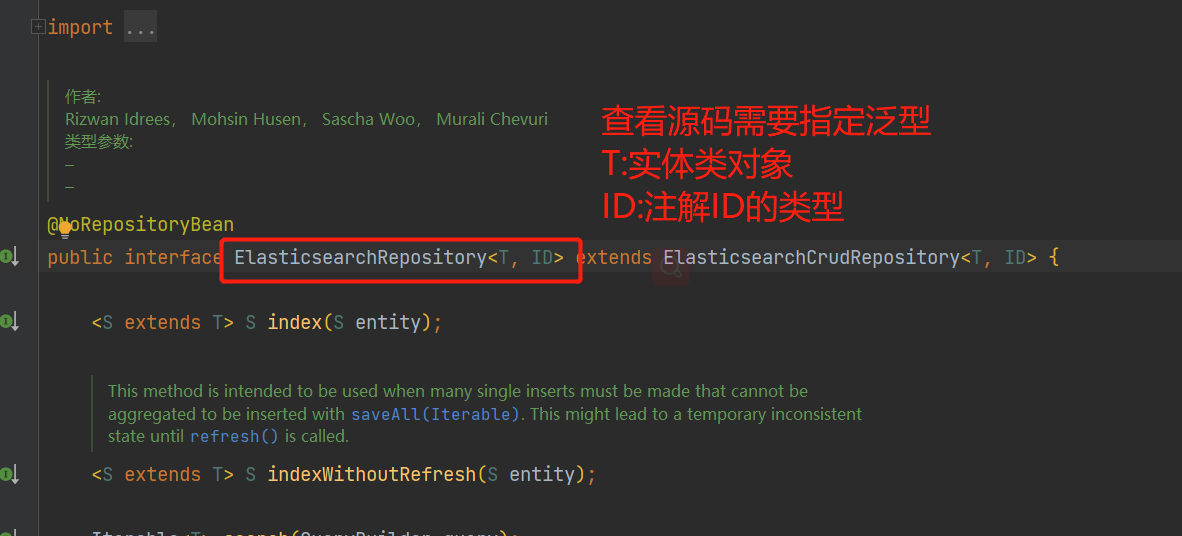
测试代码
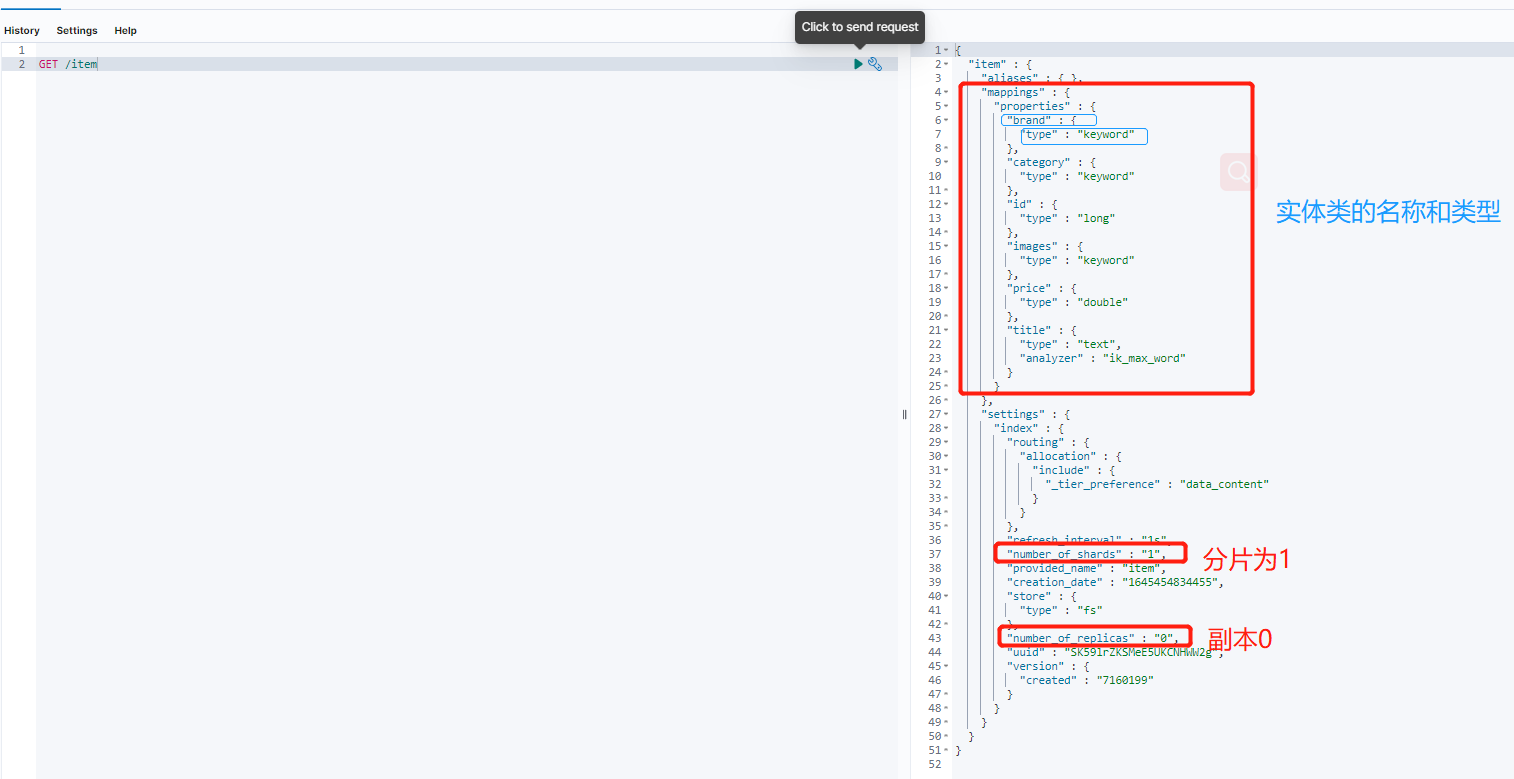
查询ES都是使用Kibana工具查询并且展示
创建es的索引库 和表名称
@RunWith(SpringRunner.class)
@SpringBootTest(classes= ElasticsearchApplication.class)
public class ElasticsearchTest {
@Autowired
private ElasticsearchTemplate elasticsearchTemplate;
@Autowired
private ItemRepository itemRepository;
/**
* 创建es的索引库 和表名称
*/
@Test
public void testIndex(){
this.elasticsearchTemplate.createIndex(Item.class);
this.elasticsearchTemplate.putMapping(Item.class);
}
}
保存一条数据到ES中:
/**
* 保存一条数据到es
*/
@Test
public void testCreate(){
Item item = new Item(1L, "小米平板", "平板", "小米", 1999.0, "http://image.xiaomi.com");
this.itemRepository.save(item);
}
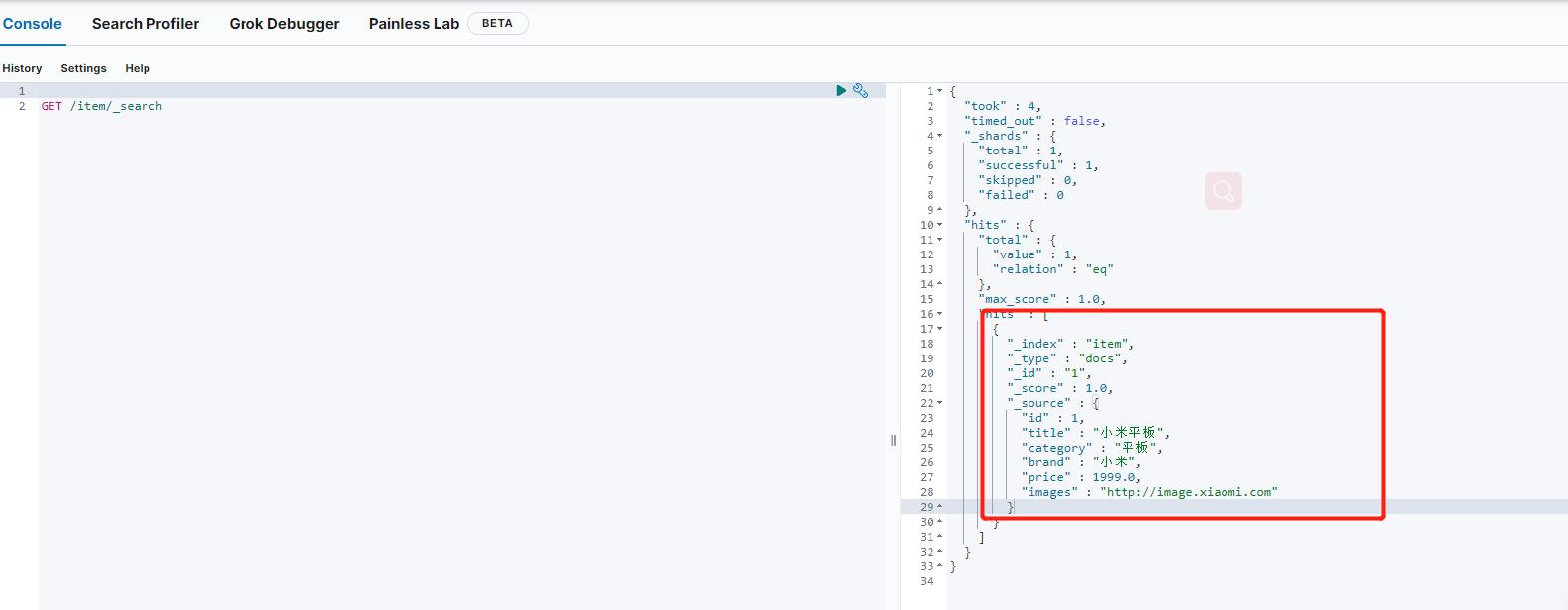
批量保存数据到ES中:
/**
* 批量保存数据到es
*/
@Test
public void testCreateList(){
List<Item> items=new ArrayList<>();
items.add(new Item(2L, "小米平板", "平板", "小米", 1999.0, "http://image.xiaomi.com"));
items.add(new Item(3L, "小新平板", "平板", "联想", 999.0, "http://image.lianxiang.com"));
items.add(new Item(4L, "华为平板", "平板", "华为", 3999.0, "http://image.huawei.com"));
this.itemRepository.saveAll(items);
}
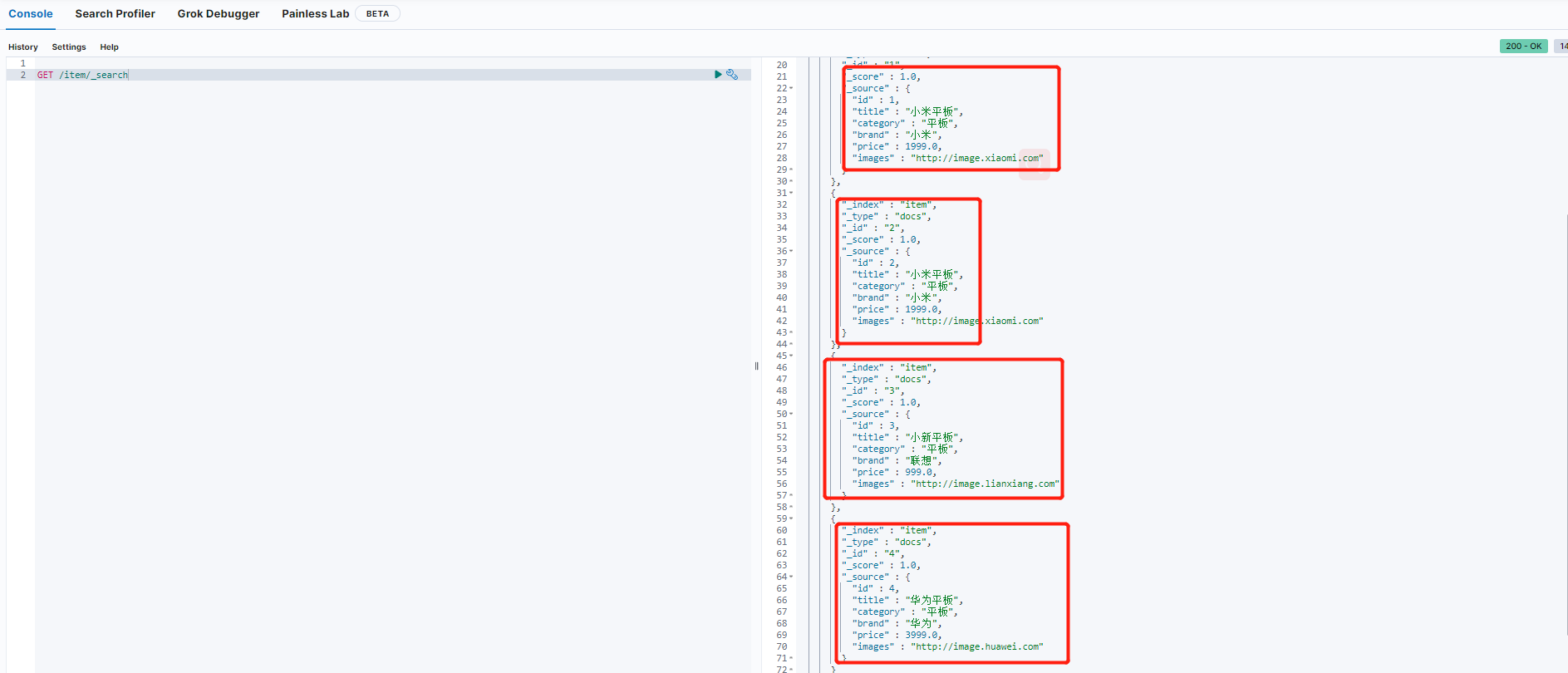
修改数据:
/**
* 修改一条数据
*/
@Test
public void testUpdate(){
//更改华为平板为华为平板pro
Item item=new Item(4L,"华为平板pro", "平板", "华为", 2999.0, "http://image.huawei.com");
this.itemRepository.save(item);
}
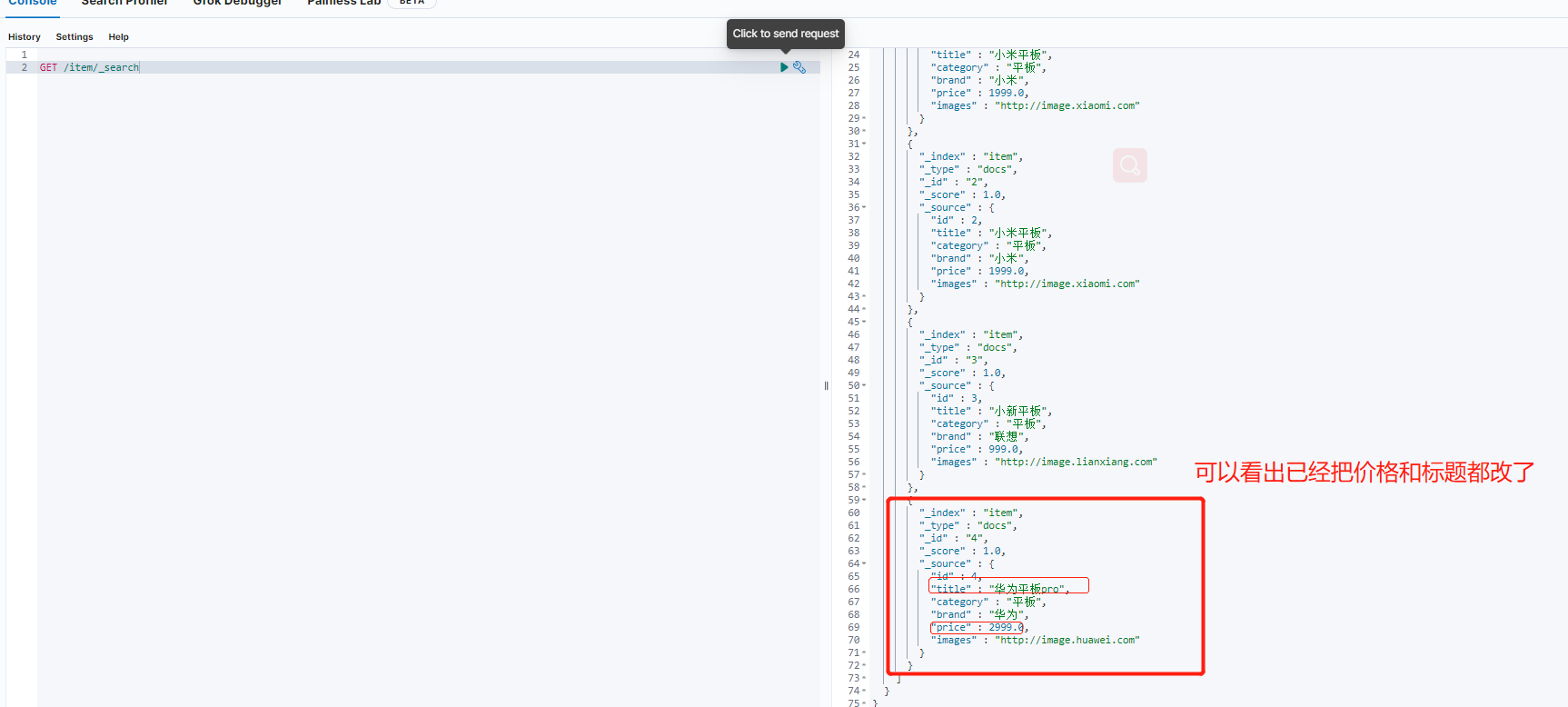
删除数据
可以看出删除的方法有4种,按需使用
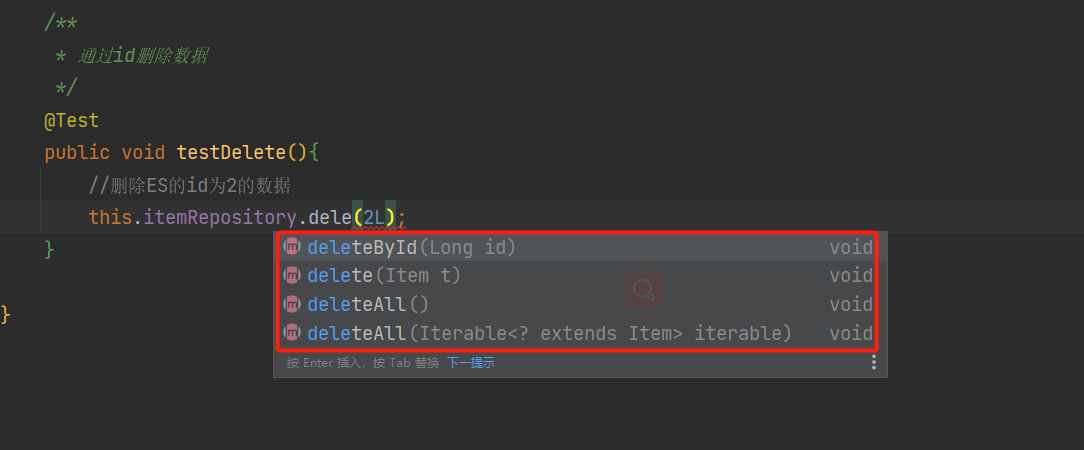
通过id删除
/**
* 通过id删除数据
*/
@Test
public void testDelete(){
//删除ES的id为2的数据
this.itemRepository.deleteById(2L);
}
原始数据
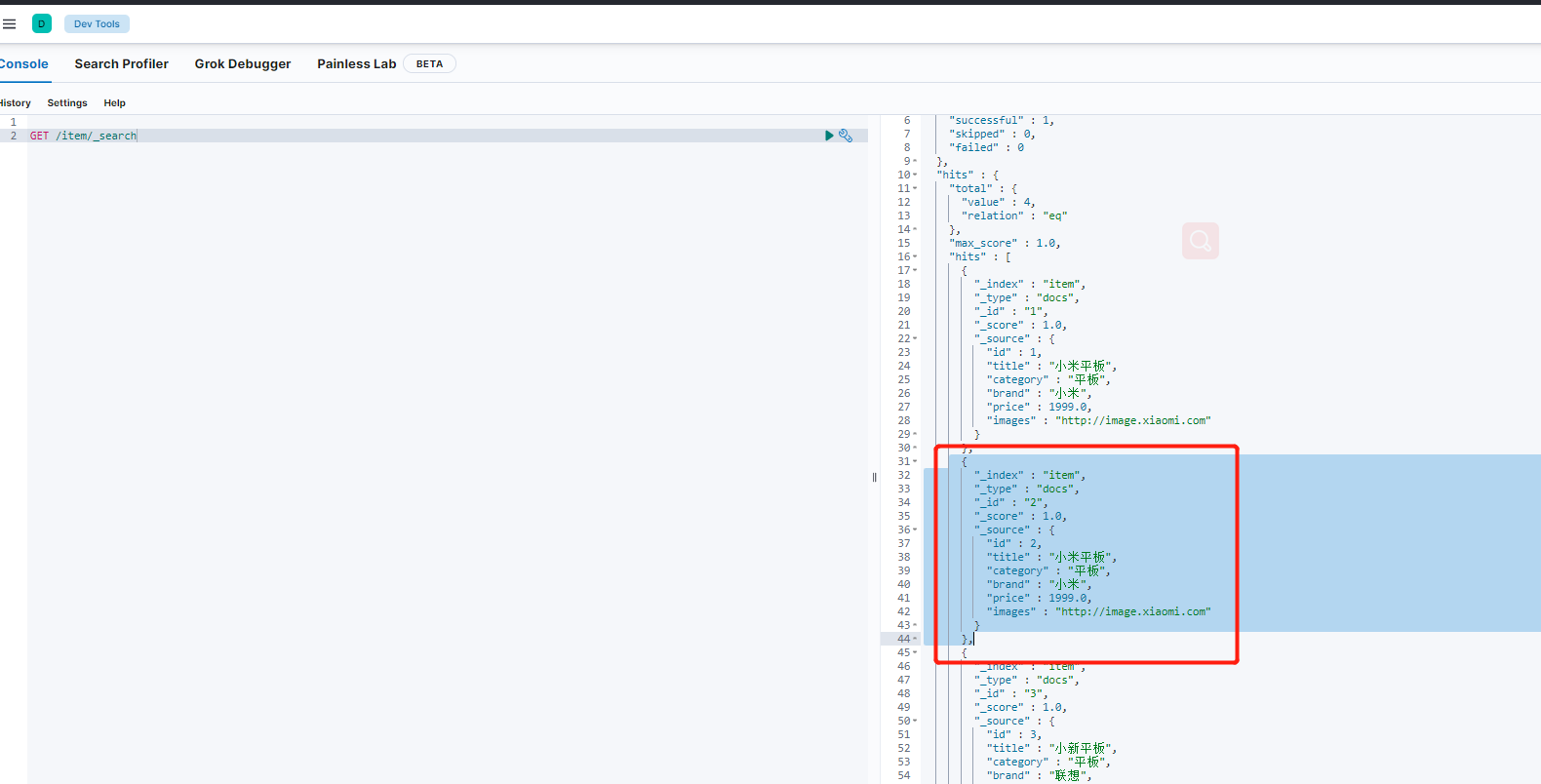
删除后的数据,可以看出数据已经被删除了
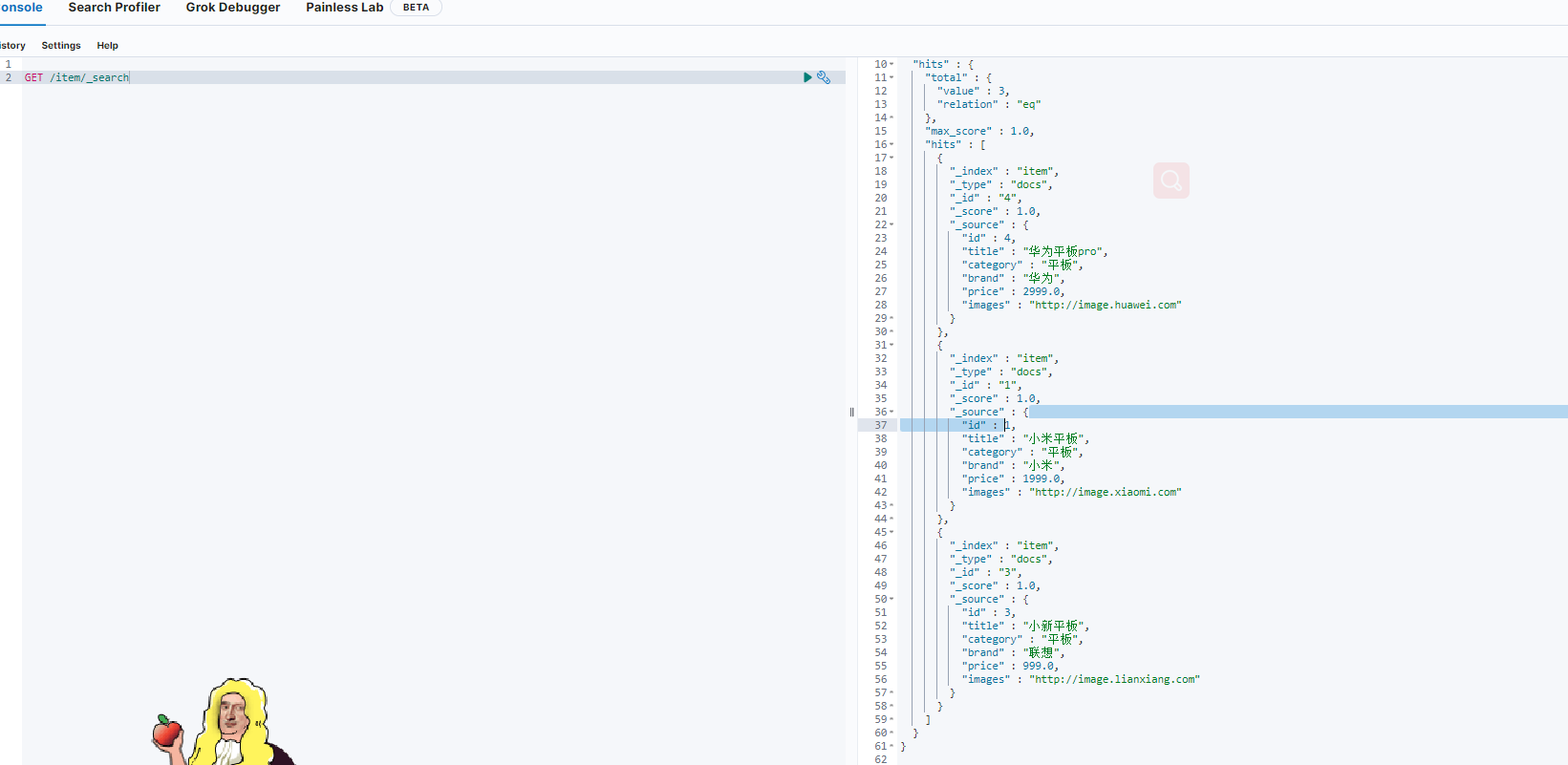
查询数据
/**
* 查询数据
*/
@Test
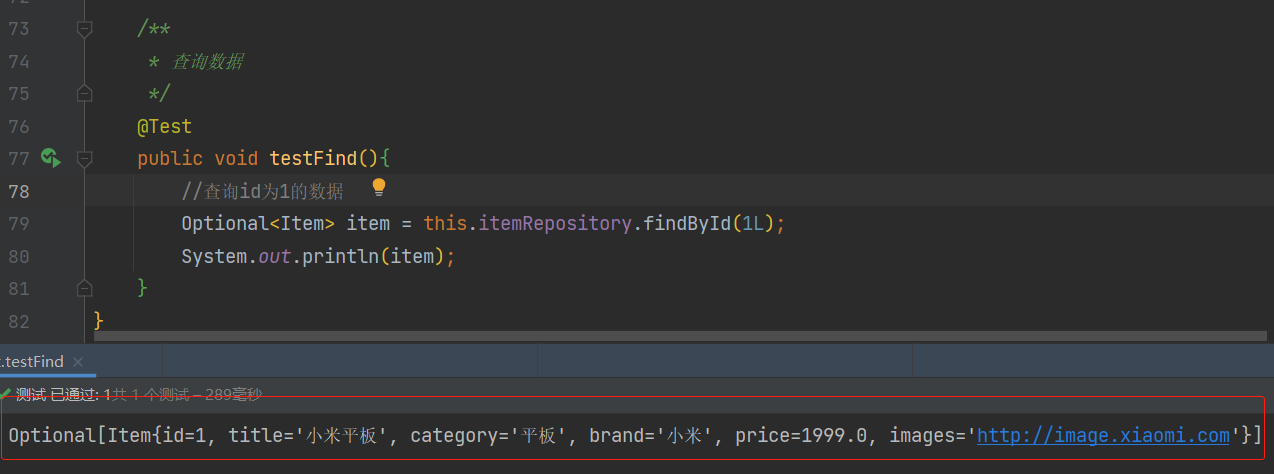
public void testFind(){
//查询id为1的数据
Optional<Item> item = this.itemRepository.findById(1L);
System.out.println(item);
}
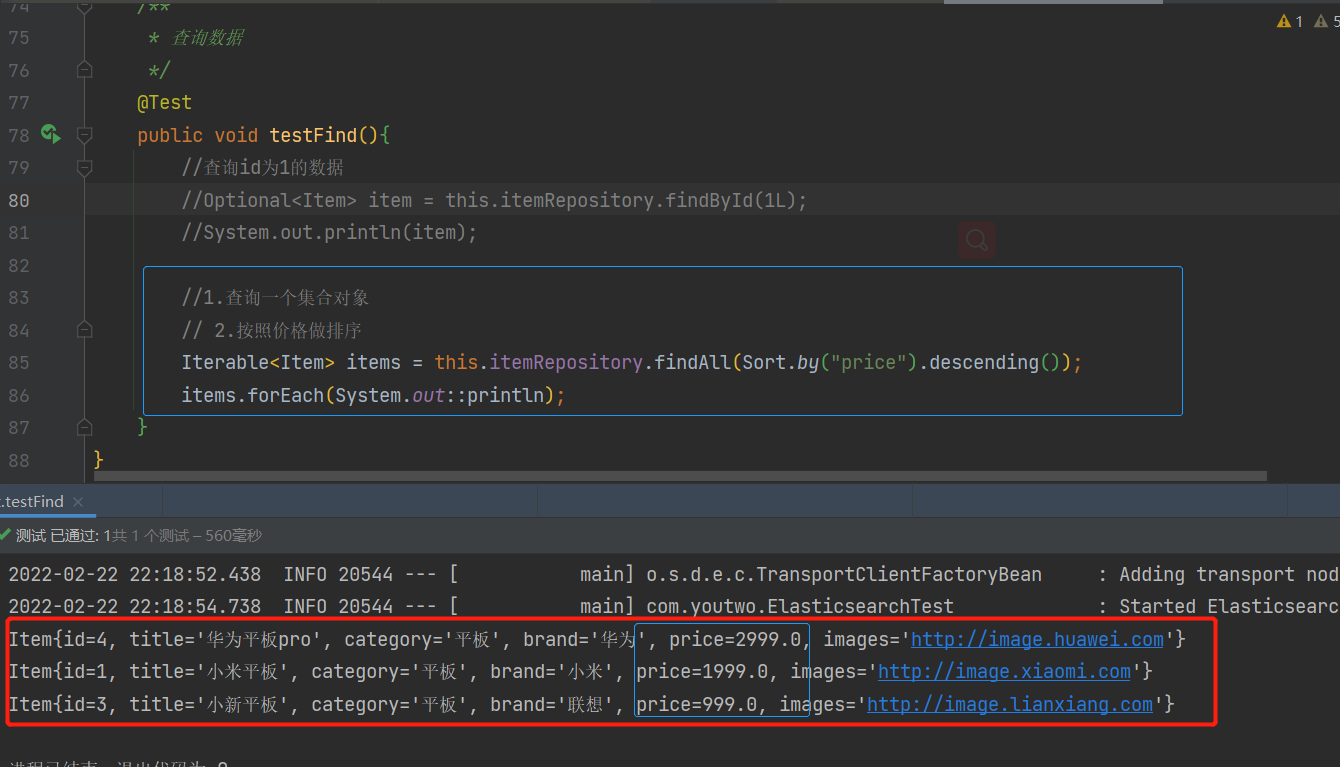
1.查询一个集合对象
2.按照价格做排序
//1.查询一个集合对象
// 2.按照价格做排序
Iterable<Item> items = this.itemRepository.findAll(Sort.by("price").descending());
items.forEach(System.out::println);
自定义方法
Spring Data 的另一个强大功能,是根据方法名称自动实现功能。
都不需要写实现代码就可以得到想要的值,但是方法命名需要按照以下格式命名才行!




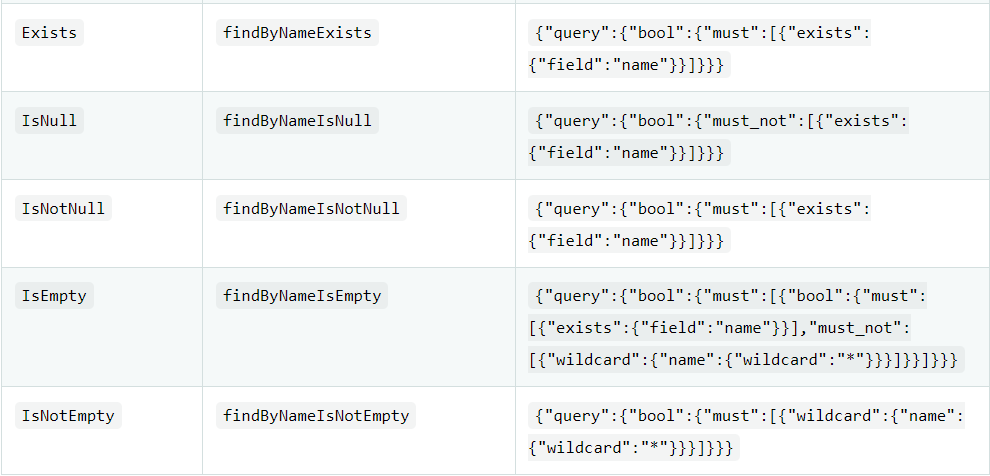
详细见官方文档

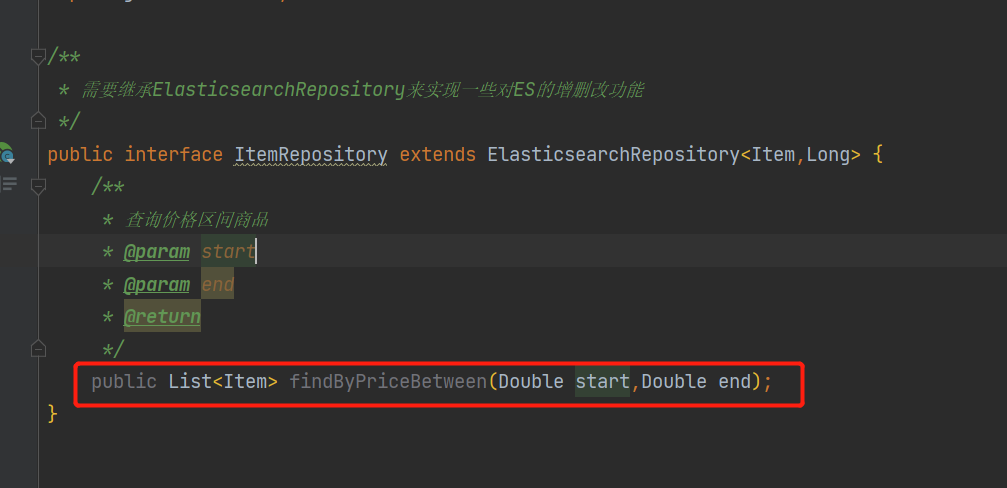
接下来我们来对价格区间进行查询
回到接口中创建方法
/**
* 查询价格区间商品
* @param start
* @param end
* @return
*/
public List<Item> findByPriceBetween(Double start,Double end);
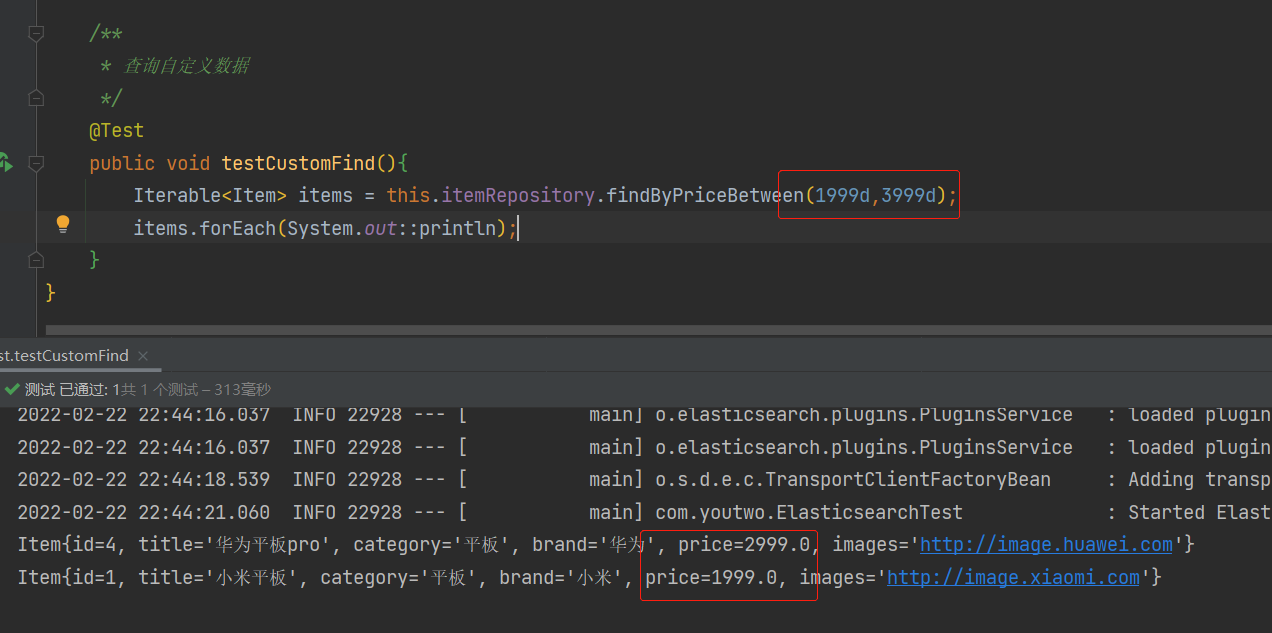
测试类添加方法
/**
* 查询自定义数据
*/
@Test
public void testCustomFind(){
Iterable<Item> items = this.itemRepository.findByPriceBetween(1999d,3999d);
items.forEach(System.out::println);
}
运行结果
虽然已经比较强大了,但是关于复杂查询(模糊、通配符、词条查询等)可能用起来就不太行了,所以后面用一些原生的查询解决
高级查询
基本查询
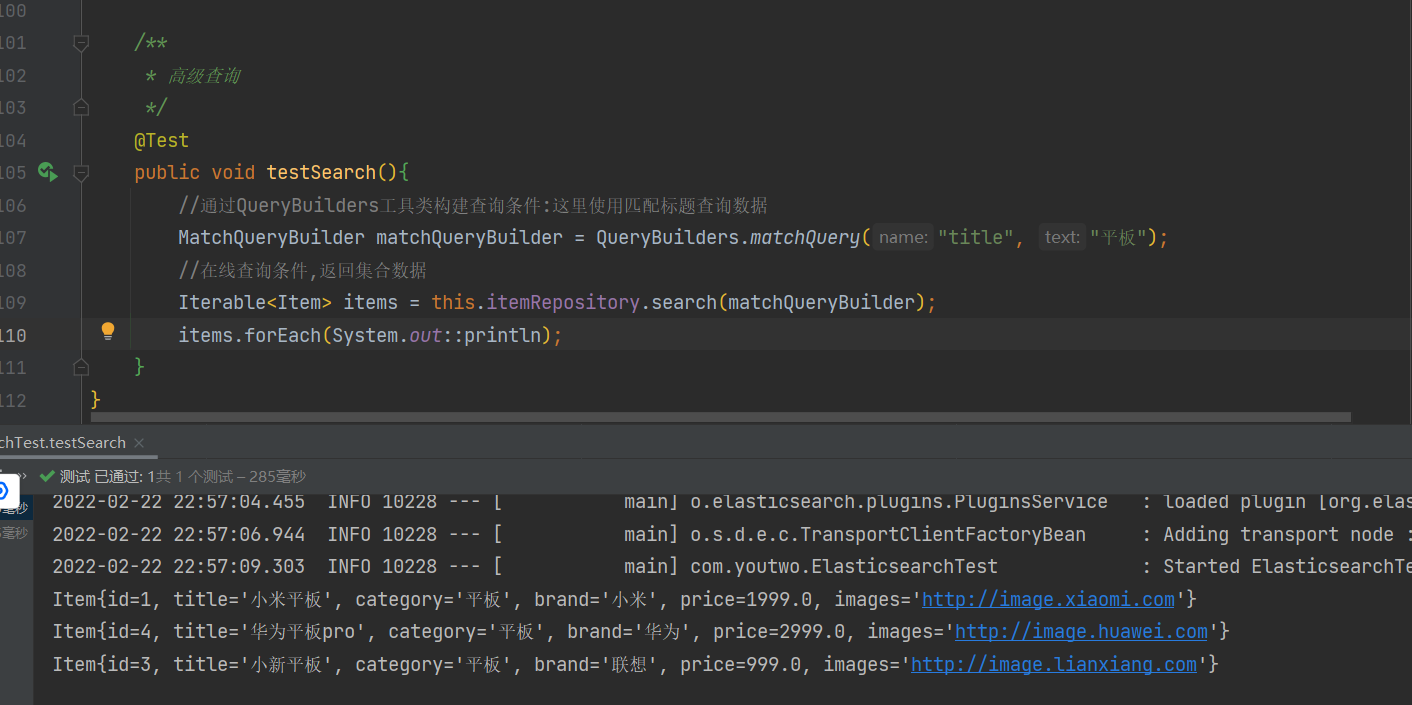
测试类添加代码
通过QueryBuilders工具类构建(模糊查询,通配符等)查询
/**
* 高级查询
*/
@Test
public void testSearch(){
//通过QueryBuilders工具类构建查询条件:这里使用匹配标题查询数据
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("title", "平板");
//在线查询条件,返回集合数据
Iterable<Item> items = this.itemRepository.search(matchQueryBuilder);
items.forEach(System.out::println);
}
运行结果
自定义查询
添加测试代码
/**
* 自定义查询
*/
@Test
public void testNative(){
//自定义查询构造器NativeSearchQueryBuilder
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
//添加基本查询条件
queryBuilder.withQuery(QueryBuilders.matchQuery("title","平板"));
//运行查询条件返回分页结果集
Page<Item> items = this.itemRepository.search(queryBuilder.build());
//可以获取分页数据
System.out.println("获取总页数"+items.getTotalPages());
items.forEach(System.out::println);
}
NativeSearchQueryBuilder:Spring提供的一个查询条件构建器,帮助构建json格式的请求体
Page< item >:默认是分页查询,因此返回的是一个分页的结果对象,包含属性:
- totalElements:总条数
- totalPages:总页数
- Iterator:迭代器,本身实现了Iterator接口,因此可直接迭代得到当前页的数据
- 其它分页属性:
运行结果
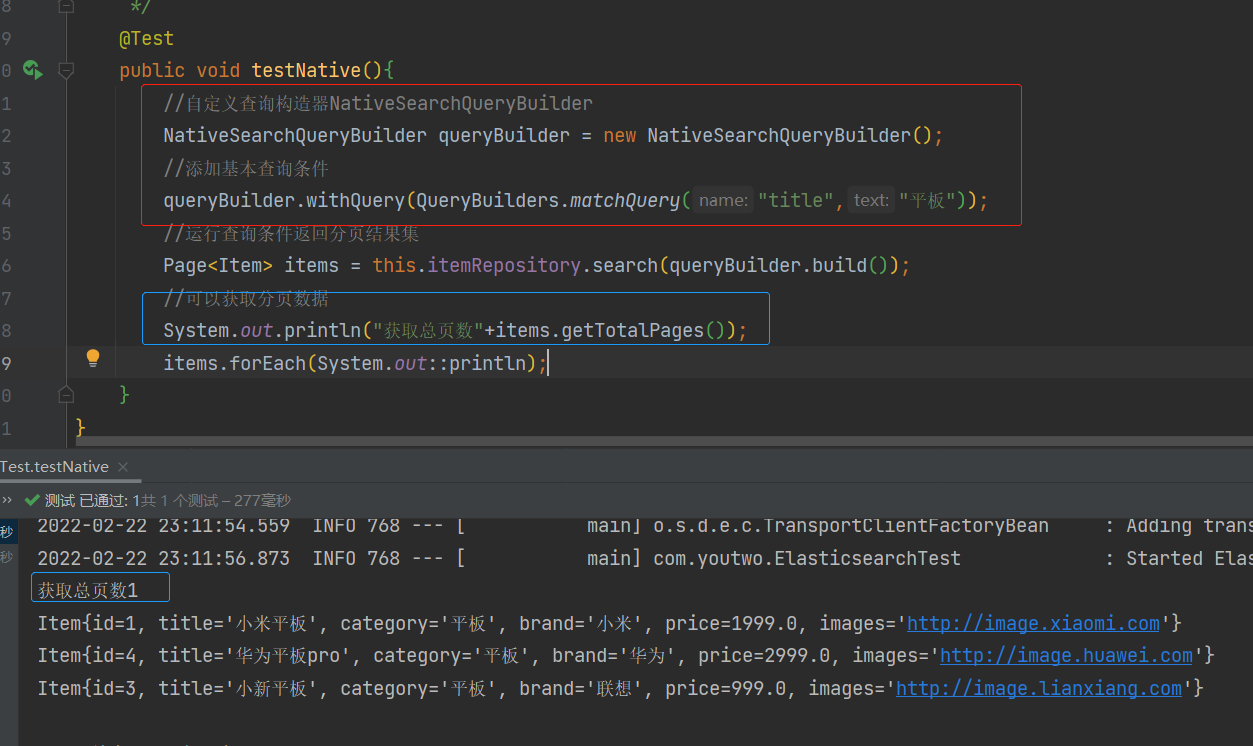
分页查询
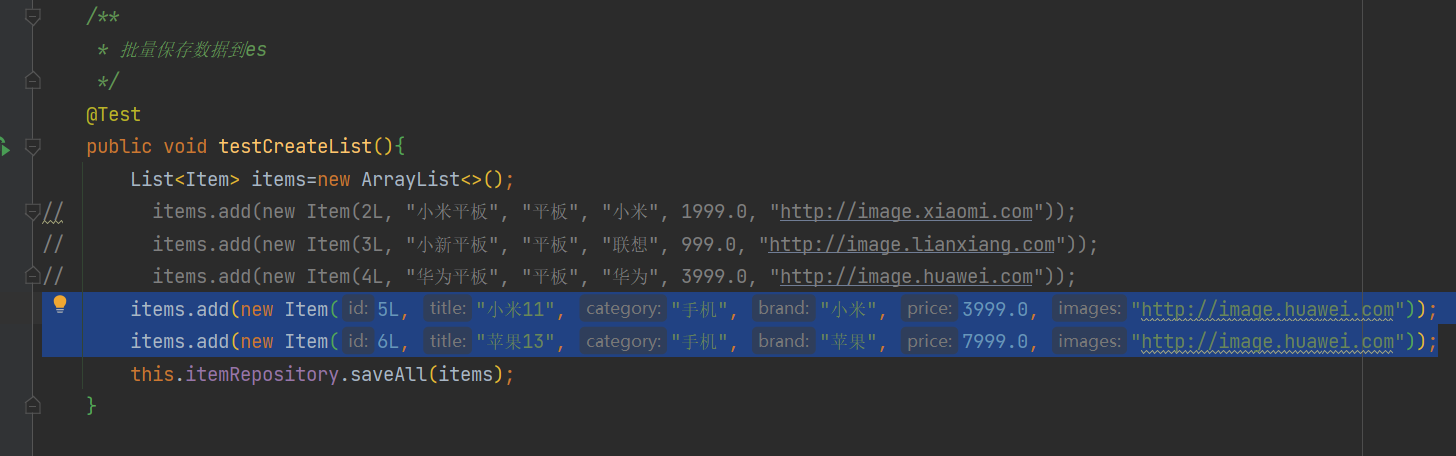
为了分页查询我们多插入2条数据到testCreateList方法里面,并且把之前的数据注释掉
items.add(new Item(5L, "小米11", "手机", "小米", 3999.0, "http://image.huawei.com"));
items.add(new Item(6L, "苹果13", "手机", "苹果", 7999.0, "http://image.huawei.com"));
如图
现在已经有5条数据了
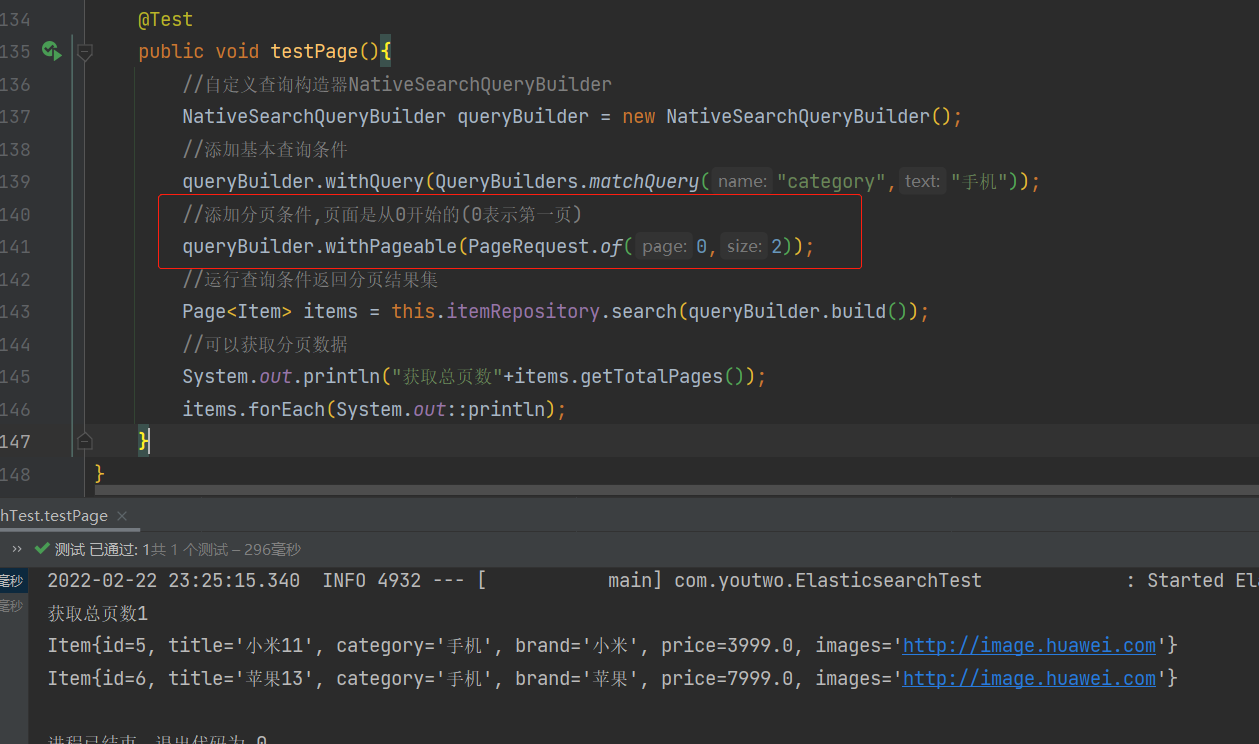
添加代码
查询类别为手机的数据并且从第一页开始查询2条数据,需要注意的是页码是从0开始的(0表示第一页)
@Test
public void testPage(){
//自定义查询构造器NativeSearchQueryBuilder
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
//添加基本查询条件
queryBuilder.withQuery(QueryBuilders.matchQuery("category","手机"));
//添加分页条件,页码是从0开始的(0表示第一页)
queryBuilder.withPageable(PageRequest.of(0,2));
//运行查询条件返回分页结果集
Page<Item> items = this.itemRepository.search(queryBuilder.build());
//可以获取分页数据
System.out.println("获取总页数"+items.getTotalPages());
items.forEach(System.out::println);
}
排序查询
排序也通用通过NativeSearchQueryBuilder完成:
测试代码
@Test
public void testSort(){
//自定义查询构造器NativeSearchQueryBuilder
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
//添加基本查询条件
queryBuilder.withQuery(QueryBuilders.matchQuery("category","手机"));
//排序:通过SortBuilders工具类来指定排序的字段按照降序排列
queryBuilder.withSort(SortBuilders.fieldSort("price").order(SortOrder.DESC));
//运行查询条件返回分页结果集
Page<Item> items = this.itemRepository.search(queryBuilder.build());
//可以获取分页数据
System.out.println("获取总页数"+items.getTotalPages());
items.forEach(System.out::println);
}
运行结果
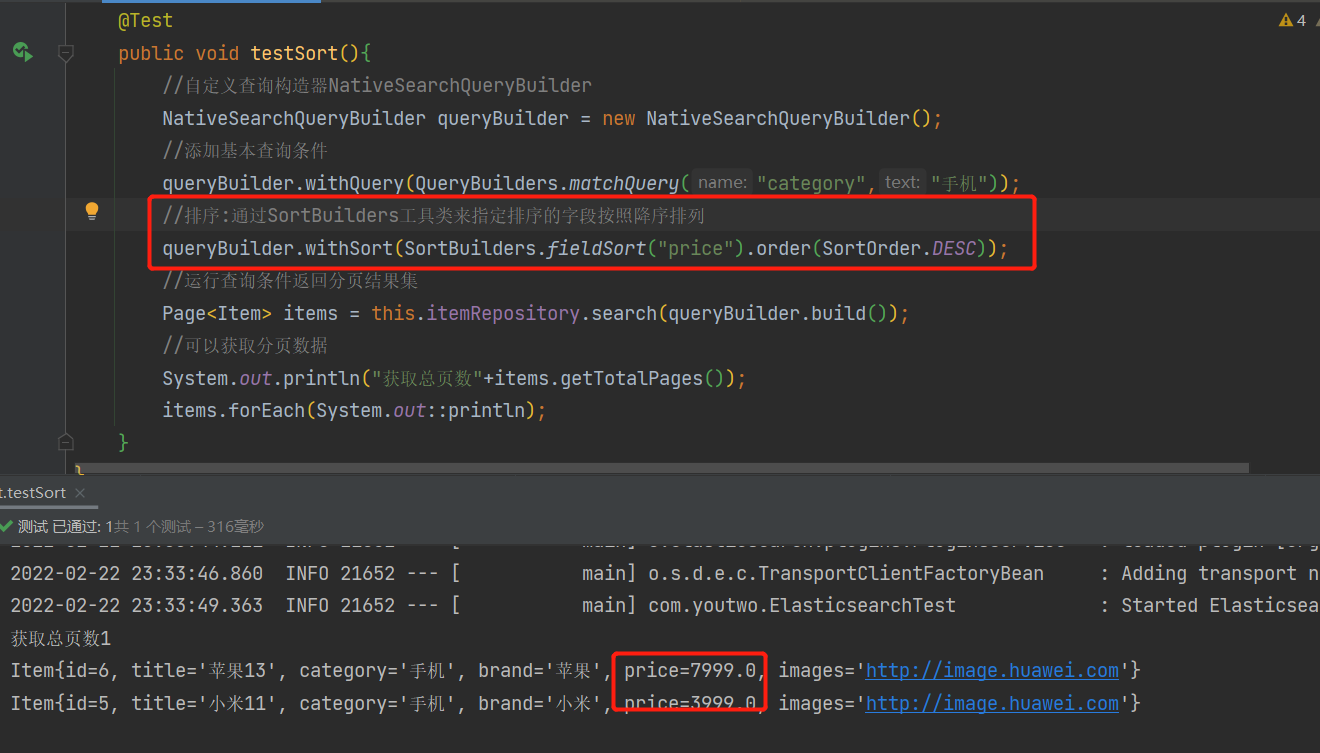
聚合查询
聚合为桶
桶就是分组,比如这里我们按照品牌brand进行分组:
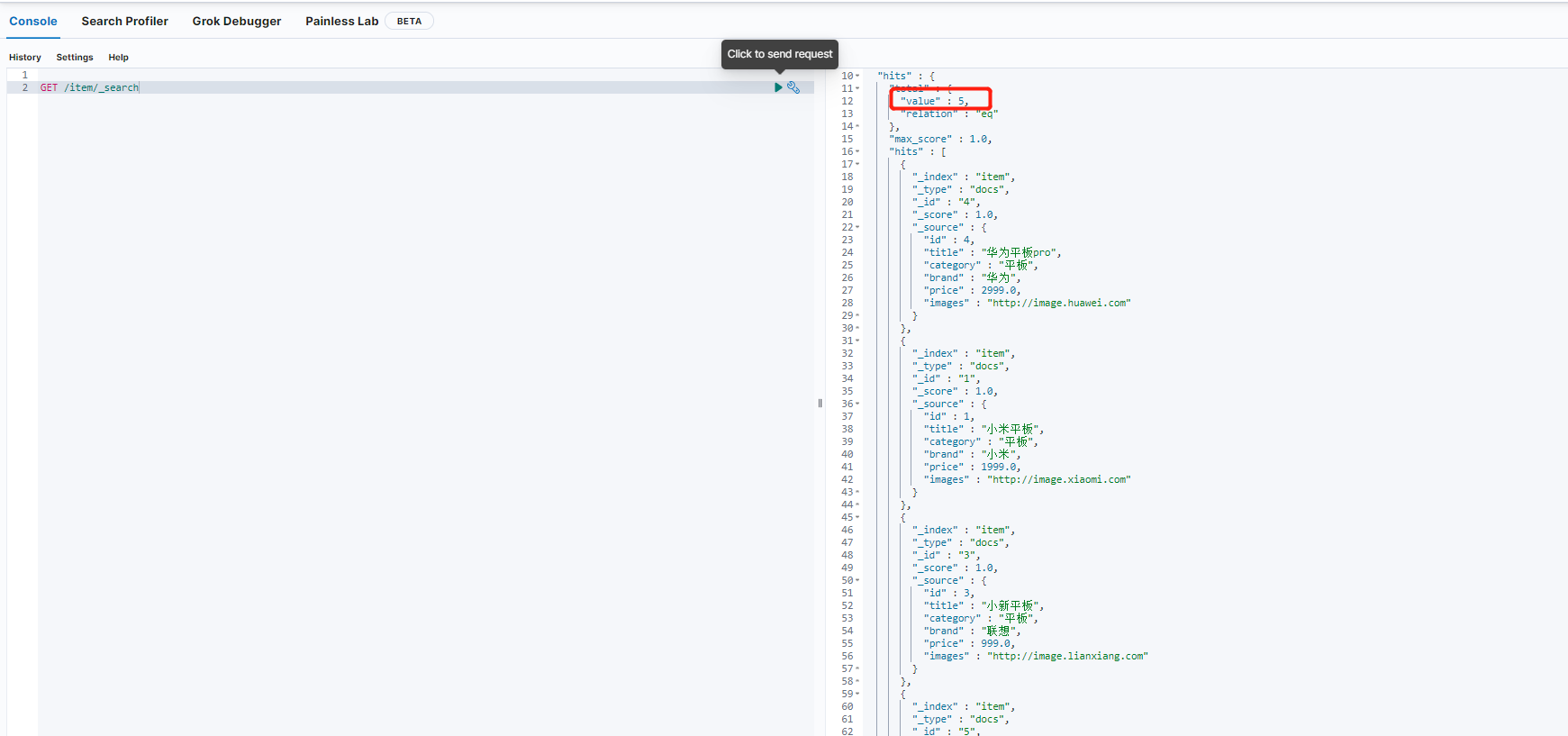
使用Kibana查询语句是:
GET /item/_search
{
"size": 0,
"aggs": {
"brandAggs": {
"terms": {
"field": "brand"
}
}
}
}
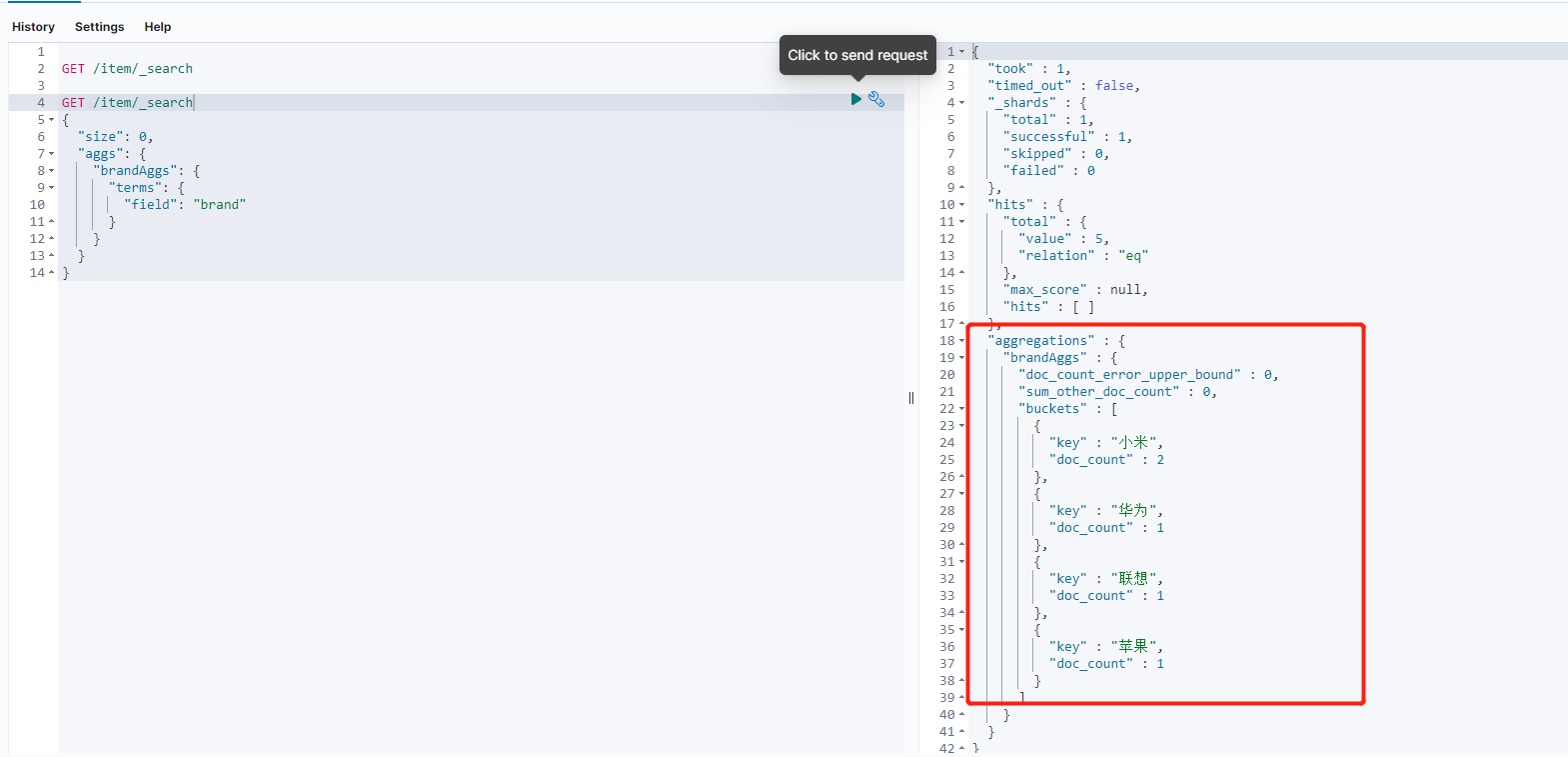
如果把上面的”size”:0去除会得到什么效果呢
GET /item/_search
{
"aggs": {
"brandAggs": {
"terms": {
"field": "brand"
}
}
}
}
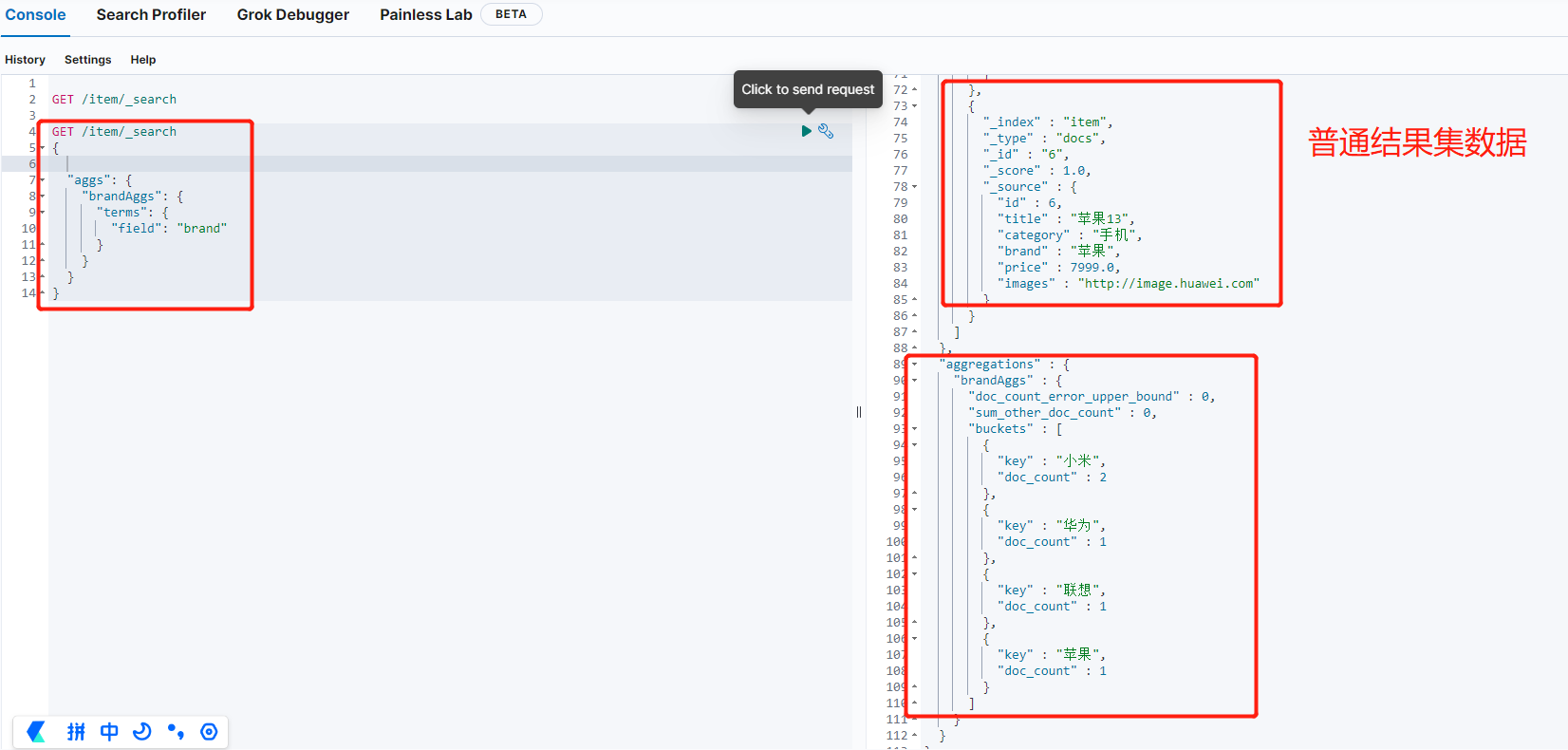
可以看出去除”size”:0就会把普通结果集数据也一起展示所以,我们后面需要设置过滤普通结果集,只需要展示分组数据.
添加测试方法
/**
* 聚合查询
*/
@Test
public void testAggs(){
//自定义查询构造器NativeSearchQueryBuilder
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
//添加聚合设置 聚合名称 和 字段
queryBuilder.addAggregation(AggregationBuilders.terms("brandAggs").field("brand"));
//添加过滤不包含任何字段 类似 size:0
//FetchSourceFilter(包括数组,排除数组)
queryBuilder.withSourceFilter(new FetchSourceFilter(new String[]{},null));
//需要使用到Page的子类(AggregatedPage)获取聚合数据
AggregatedPage<Item> itemsPage = (AggregatedPage<Item>)this.itemRepository.search(queryBuilder.build());
//解析聚合结果集 通过聚合名称强转对应的聚合类型 获取
//需要注意的是:brand字段是字符类型的所以需要强转成(StringTerms)
// 如果是Long类型使用(LongTerms),浮点型用(DoubleTerms)
StringTerms brandAggs = (StringTerms)itemsPage.getAggregation("brandAggs");
//获取桶分组
List<StringTerms.Bucket> buckets = brandAggs.getBuckets();
buckets.forEach(bucket->{
System.out.println(bucket.getKeyAsString());
System.out.println(bucket.getDocCount());
});
}
运行查看结果
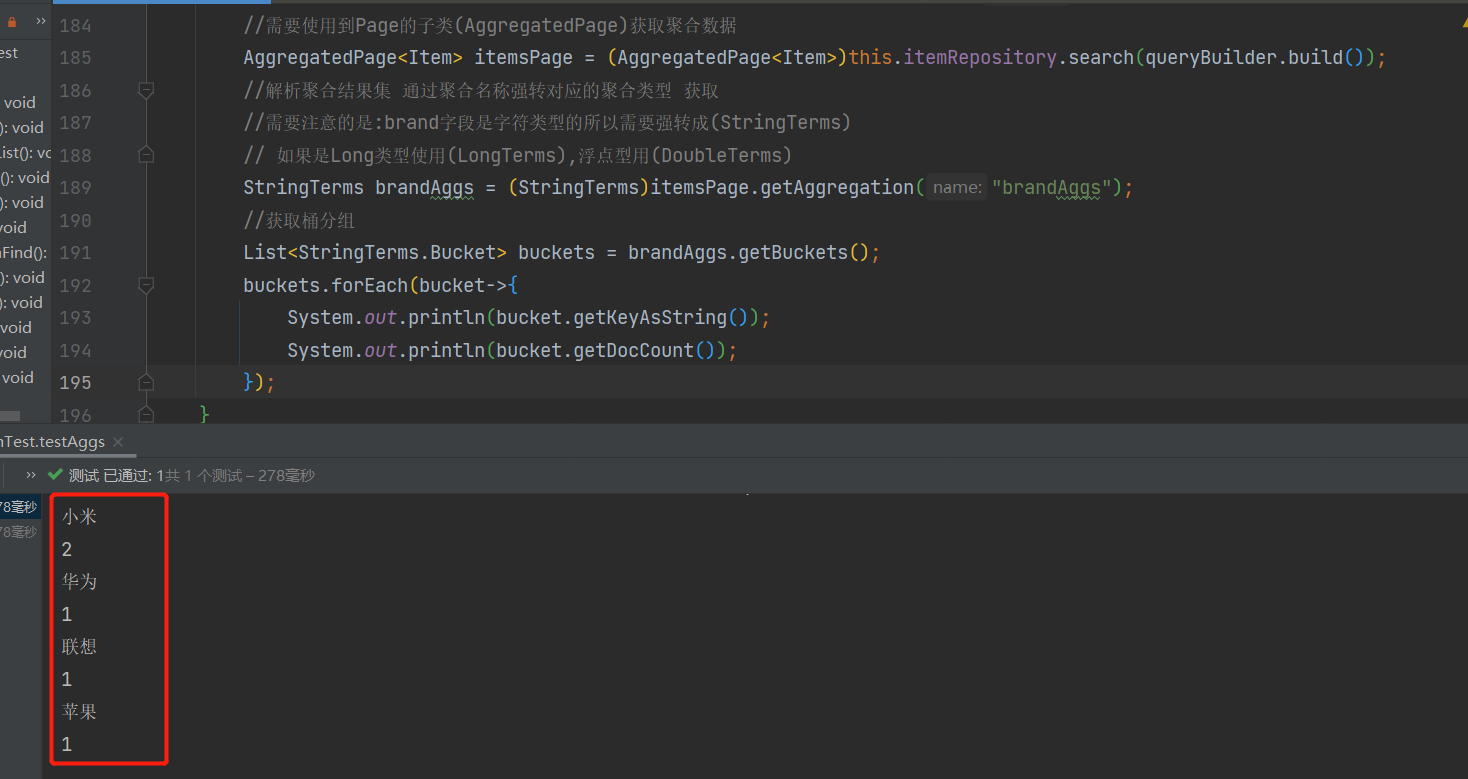
可以看出打印的数据和Kibana查询的数据是一致的!
嵌套聚合
什么为嵌套聚合,简单一点理解就是在聚合的里面在聚合一个字段,比如我查询一个品牌聚合,然后在里面在查询下这个品牌价格的平均值!
使用Kibana查询如下:
GET /item/_search
{
"size": 0,
"aggs": {
"brandAggs": {
"terms": {
"field": "brand"
},
"aggs": {
"priceAvg": {
"avg": {
"field": "price"
}
}
}
}
}
}
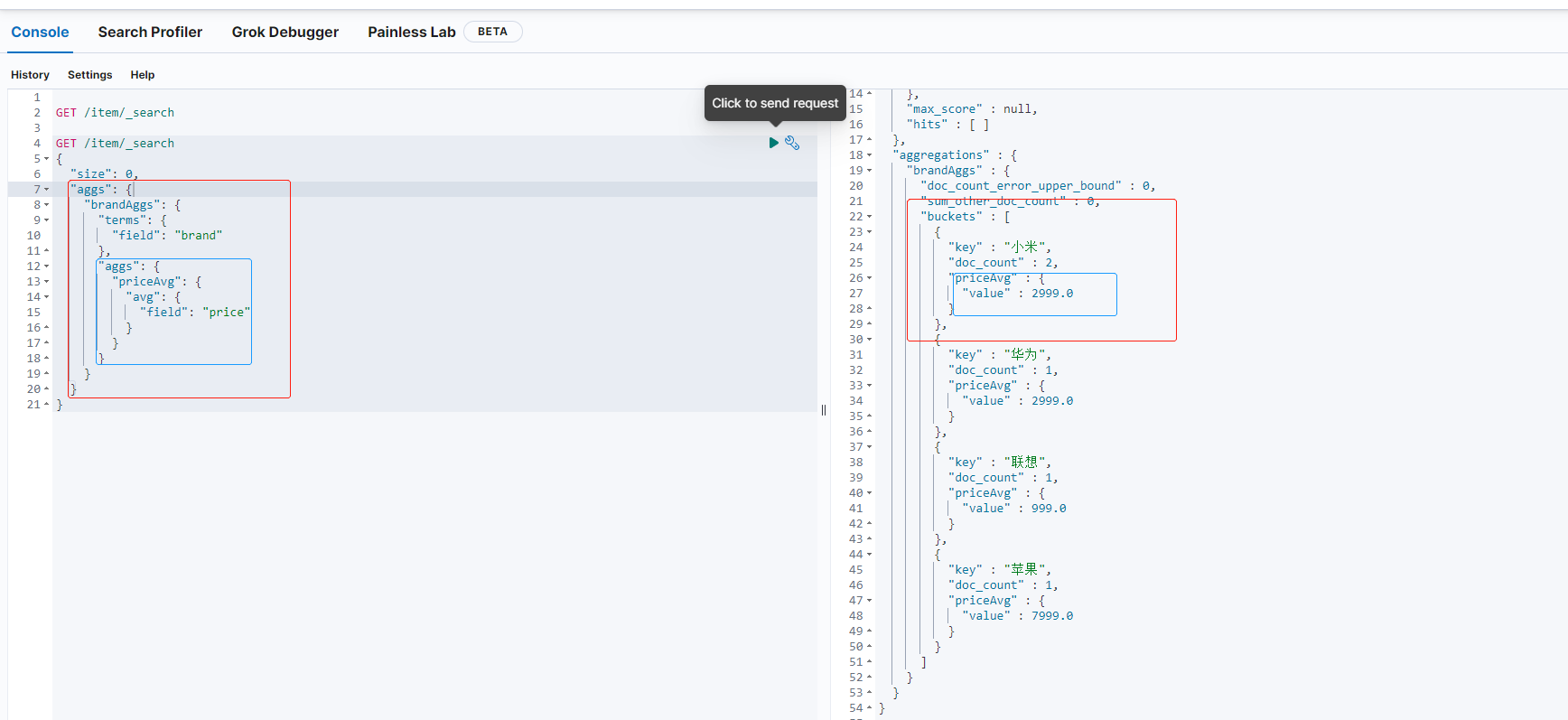
添加测试代码
/**
* 嵌套聚合查询
*/
@Test
public void testSubAggregation(){
//自定义查询构造器NativeSearchQueryBuilder
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
//添加聚合设置 聚合名称 和 字段
queryBuilder.addAggregation(
AggregationBuilders.terms("brandAggs").field("brand")//添加嵌套聚合
.subAggregation(AggregationBuilders.avg("priceAvg").field("price"))
);
//添加过滤不包含任何字段类似 size:0
//FetchSourceFilter(包括数组,排除数组)
queryBuilder.withSourceFilter(new FetchSourceFilter(new String[]{},null));
//需要使用到Page的子类(AggregatedPage)获取聚合数据
AggregatedPage<Item> itemsPage = (AggregatedPage<Item>)this.itemRepository.search(queryBuilder.build());
//解析聚合结果集 通过聚合名称强转对应的聚合类型 获取
//需要注意的是:brand字段是字符类型的所以需要强转成(StringTerms)
// 如果是Long类型使用(LongTerms),浮点型用(DoubleTerms)
StringTerms brandAggs = (StringTerms)itemsPage.getAggregation("brandAggs");
//获取桶分组
List<StringTerms.Bucket> buckets = brandAggs.getBuckets();
buckets.forEach(bucket->{
System.out.println(bucket.getKeyAsString());
System.out.println(bucket.getDocCount());
//获取子聚合Map聚合:key-聚合名称,value-聚合对象
Map<String, Aggregation> stringAggregationMap = bucket.getAggregations().asMap();
//需要强转对应类型记住关键字:interxxx查看自己需要的值
InternalAvg priceAvg =(InternalAvg) stringAggregationMap.get("priceAvg");
System.out.println(priceAvg.getValue());
});
}
运行结果
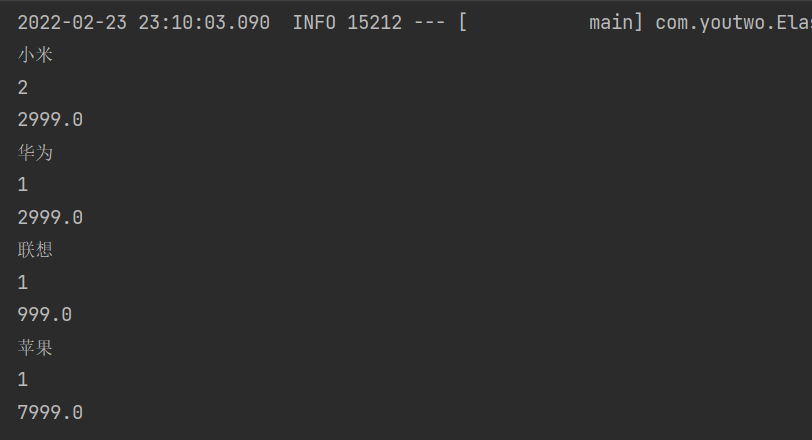
添加子聚合只要是在之前代码里面添加了以下2部分内容
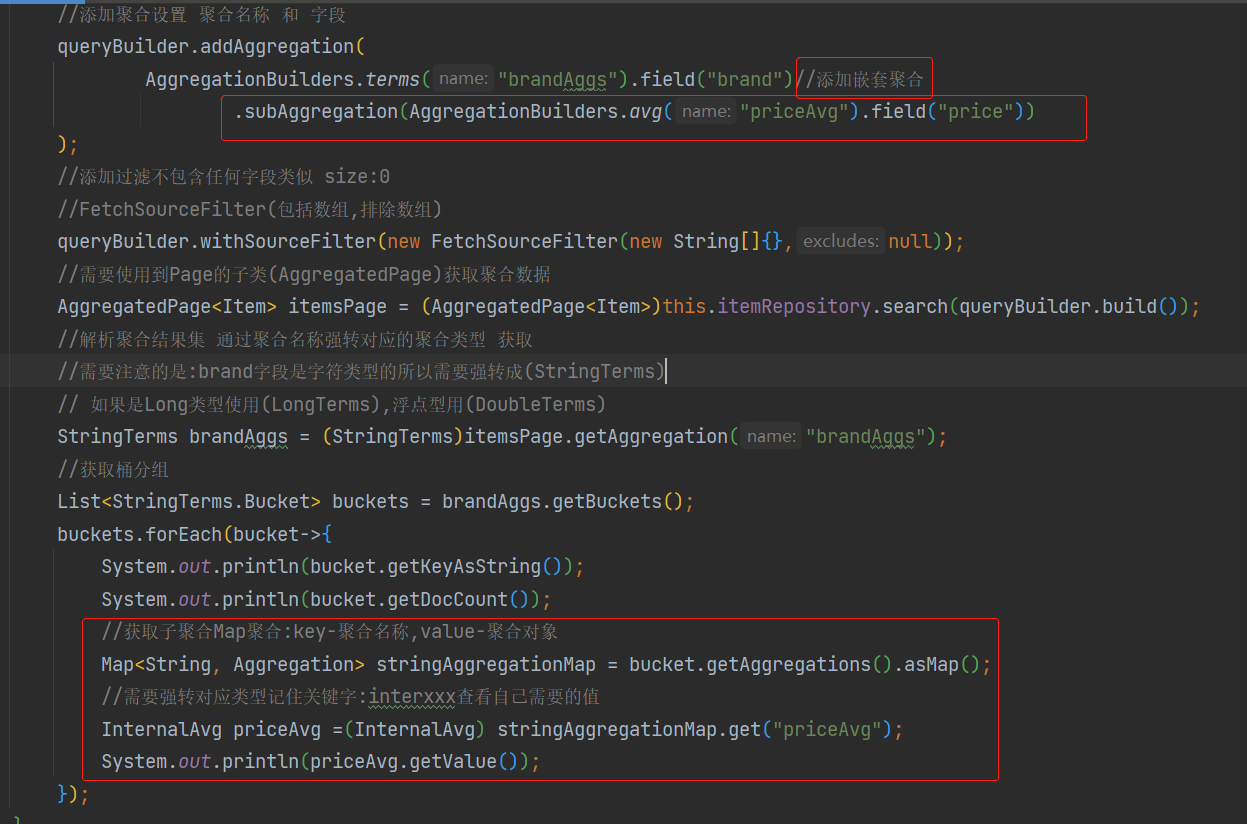
扩展Internxxx下有很多子类可以强转
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/83815.html

