
一:分词
一个 tokenizer(分词器)接收一个字符流,将之分割为独立的 tokens(词元,通常是独立 的单词),然后输出 tokens 流。
例如,whitespace tokenizer 遇到空白字符时分割文本。它会将文本 “Quick brown fox!” 分割 为 [Quick, brown, fox!]。
该 tokenizer(分词器)还负责记录各个 term(词条)的顺序或 position 位置(用于 phrase 短 语和 word proximity 词近邻查询),以及 term(词条)所代表的原始 word(单词)的 start (起始)和 end(结束)的 character offsets(字符偏移量)(用于高亮显示搜索的内容)。 Elasticsearch 提供了很多内置的分词器,可以用来构建 custom analyzers(自定义分词器)。
1.安装 ik 分词器
注意:不能用默认 elasticsearch-plugin install xxx.zip 进行自动安装。ik分词器要和es版本保持一致
es安装地址:
https://github.com/medcl/elasticsearch-analysis-ik
1)进入到es的plugin中
cd /mydata/elasticsearch/plugin
2)安装wget
yum install wget
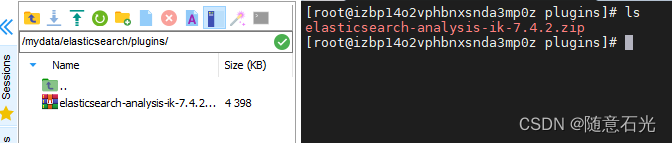
3)将下载好的ik分词器拖入到plugins目录下
4)解压ik分词器
unzip elasticsearch-analysis-ik-7.4.2.zip
二:测试分词器
1.使用默认
POST _analyze
{
"text": "我是中国人"
}
2.使用分词器
POST _analyze
{
"analyzer": "ik_smart",
"text": "我是中国人"
}
3.另外一个分词器
POST _analyze
{
"analyzer": "ik_max_word",
"text": "我是中国人"
}
能够看出不同的分词器,分词有明显的区别,所以以后定义一个索引不能再使用默 认的 mapping 了,要手工建立 mapping, 因为要选择分词器。
三:在nginx里配置es
nginx的安装:https://editor.csdn.net/md/?articleId=123170992
1.在nginx的html文件夹下新建es文件夹
cd /mydata/nginx/html
mkdir es
2.在es当中新建fenci.text
cd /mydata/nginx/html/es
vi fenci.html
四:自定义词库
1.进入到ik分词器里面
cd /mydata/elasticsearch/plugins/ik/config
2.修改IKAnalyzer.cfg.xml
vi IKAnalyzer.cfg.xml
将注释去掉,并且修改为自己配置的词库
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">http://192.168.128.130/fenci/myword.txt</entry>
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/84116.html

