
1. 为什么使用分桶表?
- 问:查询分区表时,若使用where语句进行分区过滤,那么会对某分区进行全盘扫描。这里又出现了全盘扫描字眼,那么这里可不可以优化呢?
- 答:可以,把一个大文件按照 某字段(或多个字段) 进行拆分成多个小文件,最终每个文件里存放着 该字段值(或联合字段值相同) 的数据。那么,在查询数据时使用
where指定该字段的值就可以找到扫描哪个小文件,不会扫描其他小文件,从而避免了对大文件的全盘扫描。
好处总结:
-
基于分桶字段进行where过滤时,可以减少对 对表进行全面 或 对某分区全面扫描(如果是分区表的话),提高效率。


-
基于分桶字段进行join时可以提高MR程序效率【因为这样可以减少笛卡尔积数量】

-
从分桶表中每个桶抽取样本,能够有很好的抽样效果,可用于机器学习的样本抽样。
2. 创建分桶表
在创建分区表时选择clustered by ... into ...buckets关键字。比如:
create table person(
id int,
name string comment '名字',
sex string comment '性别',
city string comment '城市'
kind string comment '种族'
)
partitioned by (sex_part string, city_part string)
-- 分桶字段可以是1个,也可以是多个
-- 还可以使用 sorted by关键字进行排序
clustered by (kind) sorted by (cases desc) into 5 buckets;
注意:
- 分桶字段必须是表的字段。
- 有几个桶就会创建几个文件。分桶表按照
分桶字段值 % 分桶数量知道将该行数据放入哪个文件。所以,当分桶字段值的种类数小于分桶个数时,分桶字段值相同的会放入到同一个文件中。
- 如果是在分区表的基础上也是分桶表,那么在会将每个分区的数据文件按照分桶字段拆分成好几个小文件。


3. 分桶表的数据导入
-
语法:使用
insert into+select关键字insert into table_name select * from other_table; -
例子:
--step1:把源数据加载到普通hive表中 CREATE TABLE itheima.t_usa_covid19( count_date string, county string, state string, fips int, cases int, deaths int) row format delimited fields terminated by ","; --将源数据上传到HDFS,t_usa_covid19表对应的路径下 hadoop fs -put us-covid19-counties.dat /user/hive/warehouse/itheima.db/t_usa_covid19 --step2:使用insert+select语法将数据加载到分桶表中 insert into t_usa_covid19_bucket select * from t_usa_covid19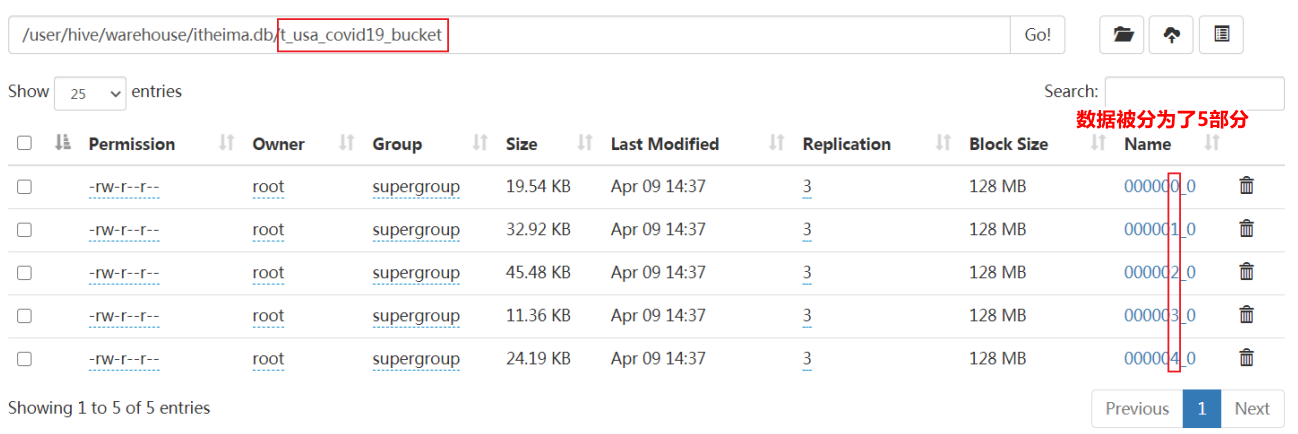
—- 关于基于分桶字段进行join时的注意事项
基于分桶字段进行join时以达到提高MR效率时,需要提前开启一些功能:

--开启分桶SMB(Sort-Merge-Buket) join
set hive.optimize.bucketmapjoin = true;
set hive.auto.convert.sortmerge.join=true;
set hive.optimize.bucketmapjoin.sortedmerge = true;
--查看执行计划
explain
select
a.id,
a.name,
b.subject,
b.num
from tb1 a join tb2 b on a.id = b.id;
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/84532.html

