
文章目录
1. Shuffle详细流程
Shuffle是MapReduce的一个阶段。
其详细流程见:MapReduce详细流程
2. 分区(Partitioner)
2.1 什么是分区?
分区:表现为将输入文件中的所有数据分成几块,每一块都单独的进行MapReduce,故最后有几个块就会产生几个文件。
2.2 默认分区器
在Shuffle阶段的第一步说到,调用分区器的getPartition()方法,为Mapper输出的键值打上分区号的标签。而默认分区器的定义如下:

默认分区是根据key的hashCode对ReduceTasks个数取模得到的。因此,用户没法控制哪个key存储到哪个分区。即没办法自定义的将哪些数据组成一块
2.2 自定义分区器
步骤:
- 自定义类继承Partitioner,重写getPartition()方法


- 在Driver类中,为job的配置自定义Partitioner规则

- 在Driver类中,为job设置分区数
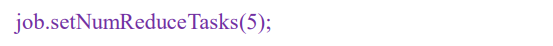
2.3 一个案例
分区的影响:分区数会产生相同数量的reduce,而一个reduce产生一个文件。所以,分区的数目就是最终文件的数目。

分类器的类定义如下:
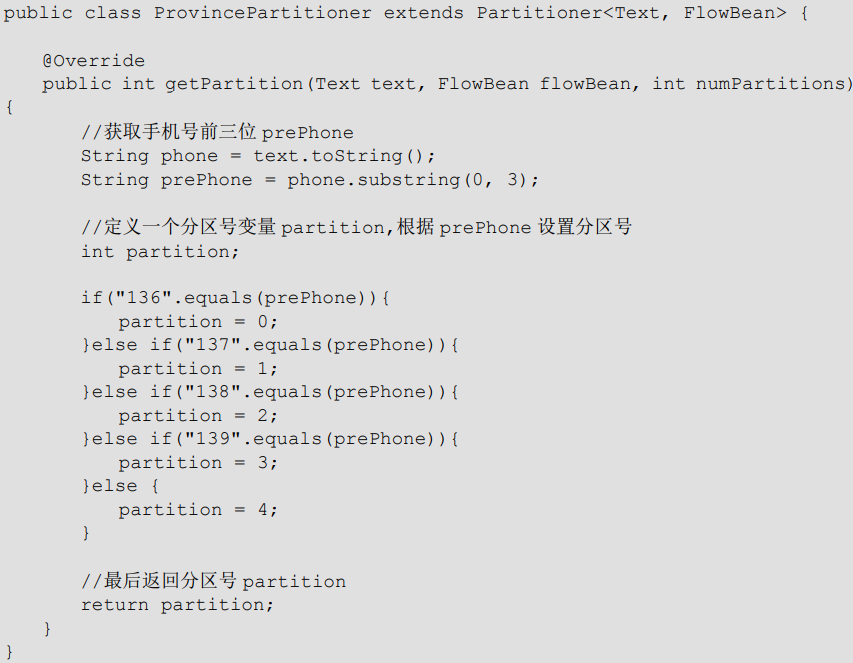
2.4 分区数 与 ReduceTask 不相等时会怎样?

3. 可选操作:规约(Combiner)
3.1 什么是Combiner?
- Combiner是指在MapTask阶段对数据进行局部汇总。
- 实现Combiner:自定义一个类继承Reducer,所以其的本质是Reducer。
- Combiner 与 Reducer 的区别:
- 处理的键值对量不同:
① Reducer是拉取所有Mapper的输出结果并处理。
② Combiner是只拉取一个Mapper的输出结果并处理。 - 存在性不同:
① Reducer是必须存在的。
② Combiner是可选的。
- 处理的键值对量不同:
- Combiner的意义:在MapTask中就进行数据的处理,以减少网络传输量,减轻ReduceTask的压力。
- Combiner运行的时机:如果为job指定了指定了Combiner,就会在如下两个时机调用
- 时机①:环型缓冲区溢写数据前
- 时机②:对当前MapTask中产生的所有溢写文件使用归并排序进行合并前
注意:时机①是一定会运行,时机②只有当待合并的文件数>=3时才运行。
3.2 在写 MR 时,什么情况下可以使用
Combiner的使用需要要谨慎,因为太可能影响最终的结果。比如:

总结:只要不影响任务的运行结果,就可以使用Combiner进行局部汇总。通常适合于求和问题,不适用于求均值。
3.3 如何定义及如何使用Combiner?
-
如何定义Combiner:
- 方式一:自定义类继承Reducer类:应用于Combiner的reduce()方法逻辑 与 Reducer的reduce()方法逻辑不相同的情况。
像Reducer一样,重写
reduce()方法即可。 - 方式二:将Reducer做为Combiner:应用于Combiner的reduce()方法逻辑 与 Reducer的reduce()方法逻辑相同的情况。
- 方式一:自定义类继承Reducer类:应用于Combiner的reduce()方法逻辑 与 Reducer的reduce()方法逻辑不相同的情况。
-
如何使用Combiner:在Driver类中为job绑定Combiner即可

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/84542.html

![【idea插件jrebel 运行报错 】JRebel-JVMTI [FATAL] Couldn‘t write to C:\Users\ 报错 已解决 亲测有效](https://www.bmabk.com/wp-content/uploads/2022/05/post-loading-480x300.gif)