
文章目录
1. Hadoop基本数据类型
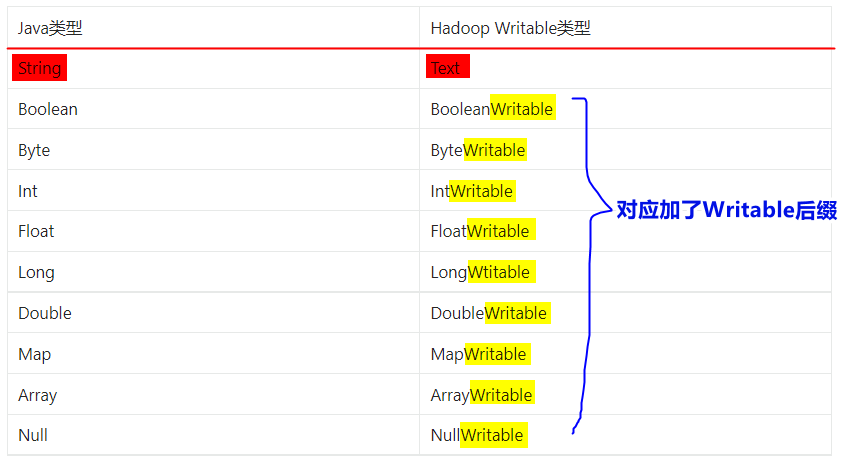

注意:
- 以上内容的导包都是
org.apache.hadoop.io.xxx- 以上类型都实现了序列化与反序列化接口,并且还实现了comparable接口。
- 关于
null使用NullWritable.get()获取。例如:

2. 序列化与反序列化
2.1 什么是序列化与反序列化?
- 序列化:把 内存 中的对象,转换成字节序列以便于存储到 磁盘(持久化)或 网络传输 (转移到另一台主机)。
- 反序列化:将收到 网络传输数据 或 磁盘 的持久化数据,转换成 内存 中的对象。
2.2 为什么要序列化?
- “活的”对象只生存在内存里,关机断电就没有了。
- “活的”对象不能被发送到网络上的另外一台计算机。
而通过序列化可以做到这些。
2.3 为什么不用 Java 的序列化?
Java 的序列化是一个重量级序列化框架(Serializable),一个对象被序列化后,会附带很多额外的信息(各种校验信息,Header,继承体系等),不便于在网络中高效传输。所以,Hadoop 自己开发了一套序列化机制(Writable)。
3. 自定义数据类型(Writable / WritableComparable)
在实际开发中,MapReduce阶段中基本类型往往不够用,所以需要自定义类。比如:
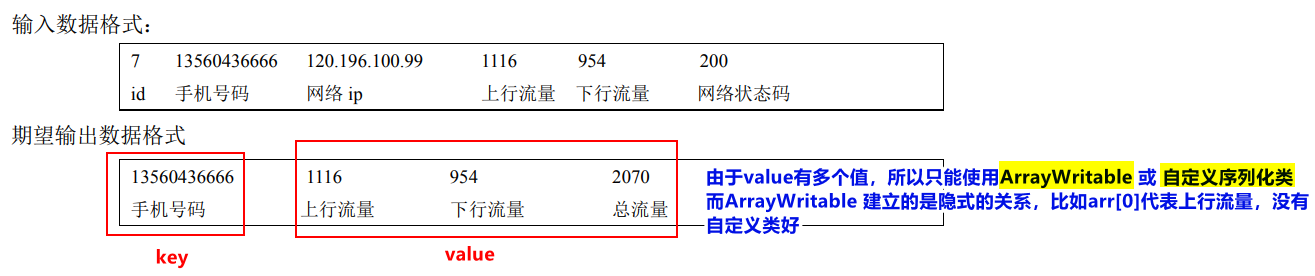
3.1 为什么自定义数据类型必须实现序列化接口
Hadoop基本类型都实现了
序列化与反序列化接口,并且还实现了排序接口。
Hadoop是分布式系统,一定涉及到文件的传输,故所有数据类型必须实现可序列化接口Writable 。
3.2 自定义数据类型必须实现排序接口吗?
通过 MapReduce详细流程 可知,整个过程中进行了三次排序,MapTask和ReduceTask均会对键值对按照key进行排序。该操作是Hadoop的默认行为,任何应用程序中的数据均会被排序,不管业务逻辑上是否需要。
所以,如果该数据类型在MapTask 和 ReduceTask中做为key,那么该数据类型必须实现可排序接口。
由于可序列化接口Writable 必须实现,所以要实现可排序用WritableComparable接口,,而不是Comparable接口。
3.3 自定义数据类型步骤
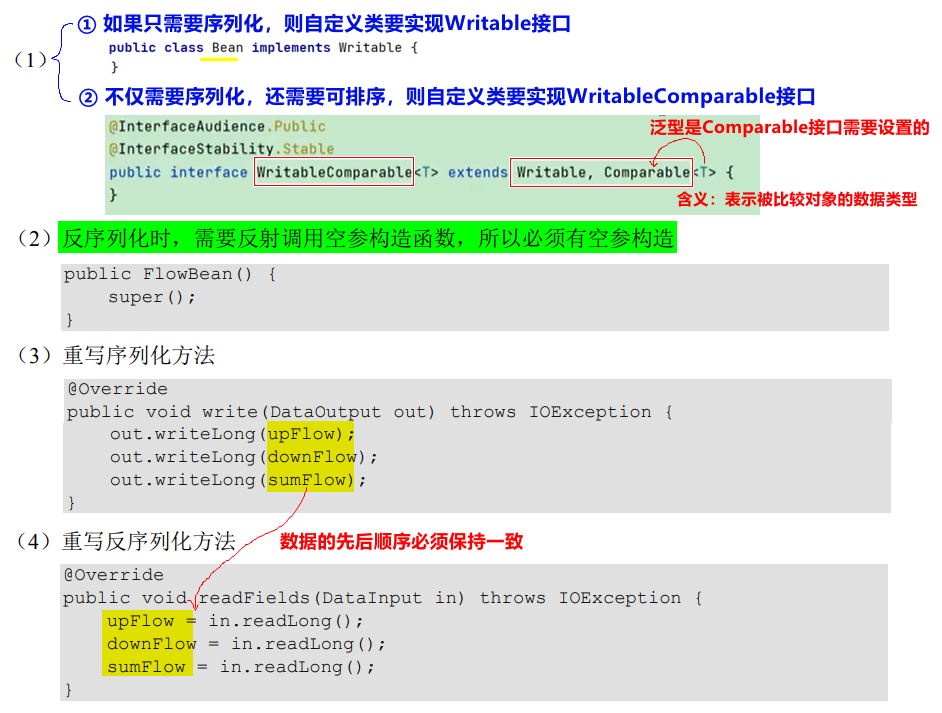
注意:
- 如果需要将自定义类对象 放在
map或reduce的key中传输,则此自定义类还需要实现WritableComparable 接口,并实现compareTo 方法。【因为MapReduce 框中的 Shuffle 过程会对key排序,否则会报异常】- 如果想在最终的结果文件中见到输出的变量值,而不是地址,则序列化对象需要重写Object父类的
toString 方法
- 该自定义类中的字段:只能定义为
java的数据类型。【因为out.write()方法传入的参数为java类型】
4. 案例:统计手机流量

第一步:确定 Map、Reduce 逻辑

第二步:编写Bean类
package com.flowcount;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class Bean implements Writable {
private long upFlow;
private long downFlow;
private long sumFlow;
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(upFlow);
out.writeLong(downFlow);
out.writeLong(sumFlow);
}
@Override
public void readFields(DataInput in) throws IOException {
upFlow = in.readLong();
downFlow = in.readLong();
sumFlow = in.readLong();
}
// getter and setter
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
@Override
public String toString() {
return upFlow + "\t" + downFlow + "\t" +sumFlow;
}
}
第二步:编写Mapper类
package com.flowcount;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class FlowMapper extends Mapper<LongWritable, Text, LongWritable, Bean> {
private LongWritable outK = new LongWritable();
private Bean outV = new Bean();
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, LongWritable, Bean>.Context context) throws IOException, InterruptedException {
// 1. 读取取一行并切分字段
String[] field = value.toString().split("\t");
// 2. 获取手机号、上行流量、下行流量
outK.set(Long.parseLong(field[1]));
outV.setUpFlow(Long.parseLong(field[field.length-3]));
outV.setDownFlow(Long.parseLong(field[field.length-2]));
// 3. 输出
context.write(outK, outV);
}
}
第三步:编写Reducer类
package com.flowcount;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.mapreduce.Reducer;
import javax.jws.Oneway;
import java.io.IOException;
public class FlowReducer extends Reducer<LongWritable, Bean, LongWritable, Bean> {
private LongWritable ouK = new LongWritable();
private Bean outV = new Bean();
@Override
protected void reduce(LongWritable key, Iterable<Bean> values, Reducer<LongWritable, Bean, LongWritable, Bean>.Context context) throws IOException, InterruptedException {
ouK = key;
// 1. 迭代输入的value,统计上行流量、下行流量
long sumUpFlow = 0;
long sumDownFlow = 0;
long sumFlow = 0;
for (Bean bean : values) {
sumUpFlow += bean.getUpFlow();
sumDownFlow += bean.getDownFlow();
}
sumFlow = sumUpFlow + sumDownFlow;
outV.setUpFlow(sumUpFlow);
outV.setDownFlow(sumDownFlow);
outV.setSumFlow(sumFlow);
// 2. 输出
context.write(ouK, outV);
}
}
第四步:编写Driver类
package com.flowcount;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class FlowDriver{
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
// 1. 获取job
Configuration config = new Configuration();
config.set("mapreduce.reduce.shuffle.memory.limit.percent", "0.25");
Job job = Job.getInstance();
// 2. 关联本 Driver 类
job.setJarByClass(FlowDriver.class);
// 3. 关联 mapper和reducer
job.setMapperClass(FlowMapper.class);
job.setReducerClass(FlowReducer.class);
// 4. 设置map输出的key、value类型
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Bean.class);
// 5. 设置最终输出(最终输出不一定是Reducer输出,有的只有map没有reduce)的key、value类型
job.setOutputKeyClass(LongWritable.class);
job.setOutputValueClass(Bean.class);
// 6. 设置输入路径和输出路径
FileInputFormat.setInputPaths(job, new Path("E:\\test\\phone_data.txt")); // 本地文件路径,可以输入多个
FileOutputFormat.setOutputPath(job, new Path("E:\\test\\temp\\flow")); // 本地文件路径(需要是一个不存在的文件夹,
// 7. 调用 job.submit() 提交作业
job.submit();
}
}
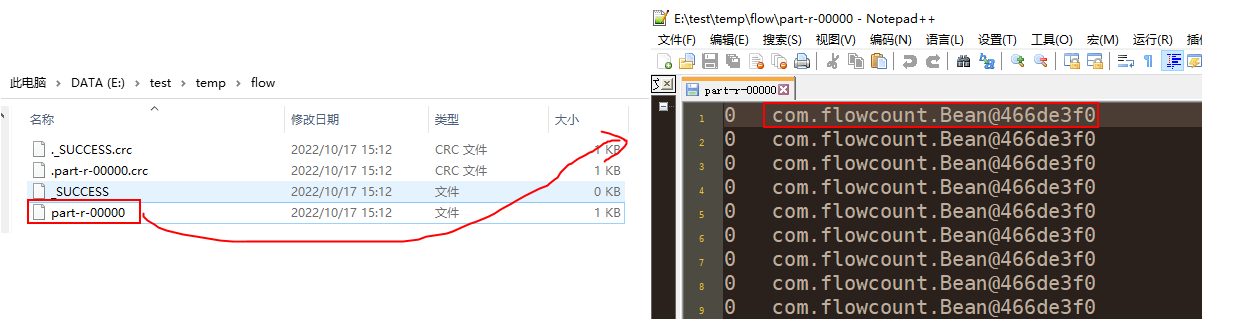
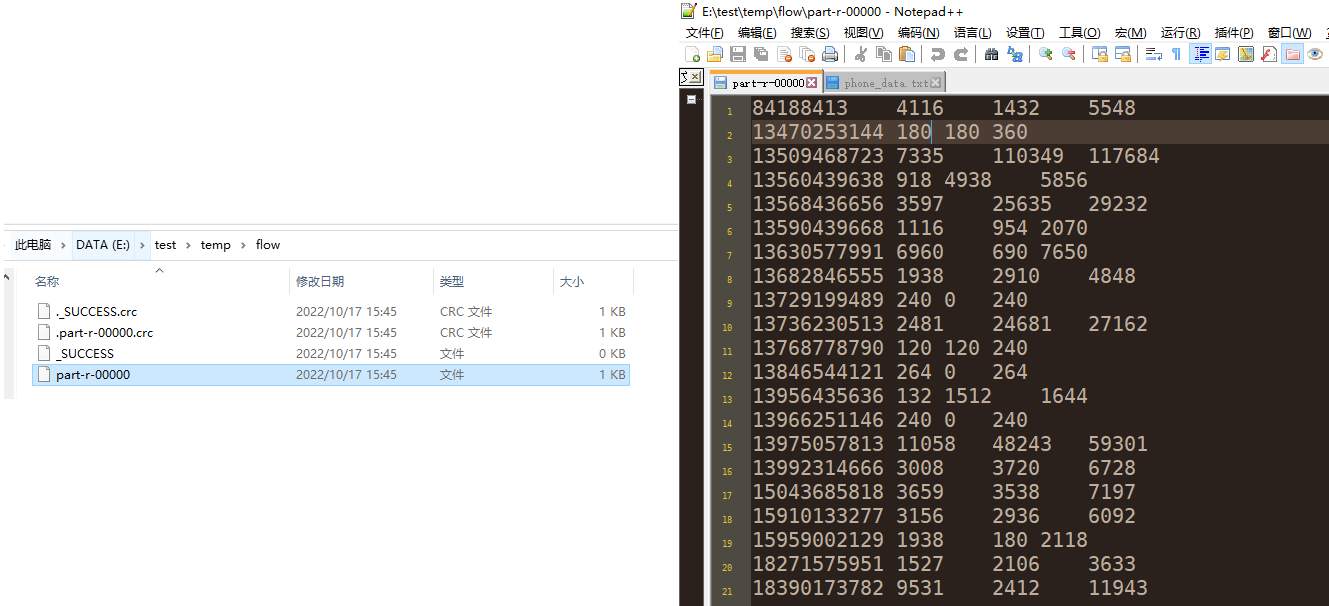
第五步:运行程序并查看结果
- 启动 hadoop
- 运行程序
- 结果
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/84544.html

