
tensorflow—优化器
一、基础知识
1.损失函数
损失函数是评估特定模型参数和特定输入时,表达模型输出的推理值与真实值之间不一致程度的函数。形式化定义如下:
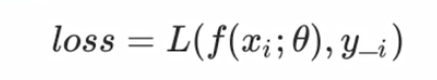
其中xi是样本,θ是模型参数,f(xi;θ)是模型预测的值,y-i是真实的测试数据。f(xi;θ)越接近y-i,说明模型拟合越的接近真实值。
常见的损失函数有平方损失函数、交叉熵损失函数和指数损失函数:
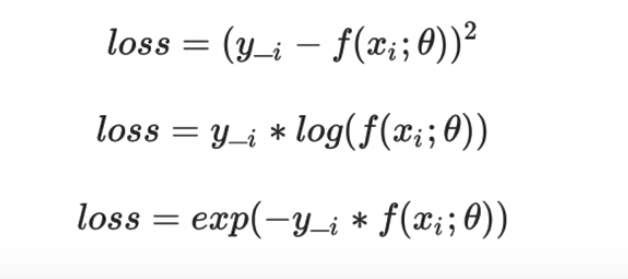
2.经验风险
使用损失函数对所有训练样本求损失值,再累加求平均值可得到模型的经验风险,f(x)关于训练集平均损失就是经验风险,其形式化定义如下:
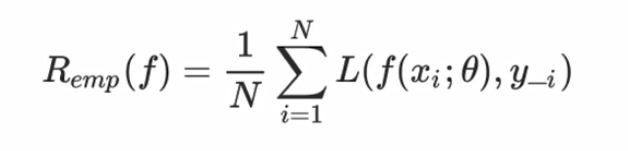
理想情况是经验损失越小越好,但是,如果我们过分的追求低损失值,就是出现过拟合的现象。因为虽然损失值越小越好,但是我们不能保证训练集能完全的代表真实场景。过分的低损失值,固然会很好的拟合训练集,但是当两者分布不一致时,最终结果是反而偏离了真实的情况,这时模型的泛化能力就会变差。
所以,面对经验风险时,一定要合理的衡量经验风险。
3.结构风险最小化
模型训练的目标是不断最小化经验风险。随着训练步数的增加,经验风险将降低,模型复杂度也会上升。为了降低过度训练可能造成的过拟合风险,可以专门引入用来度量模型复杂度的正则化项(regularizer)或惩罚项(penaly term)—J(f),J(f)可以降低模型复杂度。常用的正则化项有L0\L1\L2范数。所以,我们将模型最优化的目标替换为鲁棒性更好的结构风险最小化(srm)。如下图:
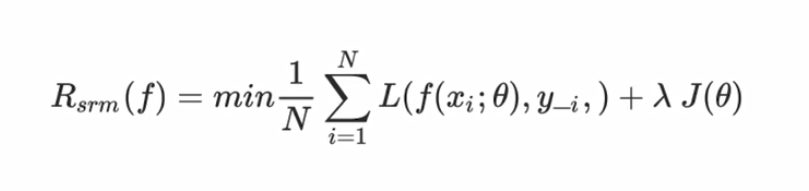
其中,λ是正则化参数的权重。
4.最优模型参数
在模型训练过程中,结构风险不断低降低。当小于设置的损失值阈值(比如10^-6),则认为此时的模型已经满足需求。因此,模型训练的本质就是在最小化结构分析取得最优的模型参数。最优模型参数形式化定义如下:
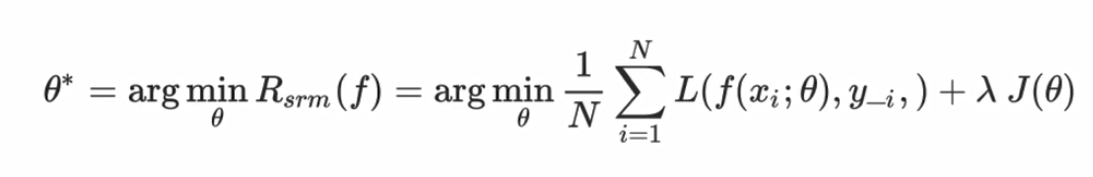
θ*就是模型参数,他一系列参数的组成。
5.优化算法
典型的机器学习和深度学习问题通常都需要转换为最优化问题进行求解。
而求解最优化问题的算法称为优化算法,他们通常采用迭代方式实现:首先设定一个初始的可行解,然后基于特定的函数(模型就相当于一个复杂的函数)反复重新计算可行解,直到找到一个最优解或达到预设的收敛条件。不同的优化算法采取的迭代策略各有不同:
- 有的使用目标函数的一阶导数,如梯度下降法
- 有的使用目标函数的二阶导数,如牛顿法
- 有的使用前几轮迭代的信息,如Adam
eg:梯度下降算法是最简单的优化算法:
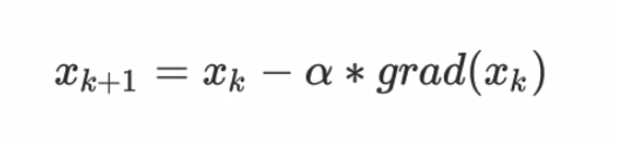
α是步长或者学习转换率,grad(xk)是xk是方向导数,函数沿着方向导数的负方向下降最快,所以,α前面是负号。
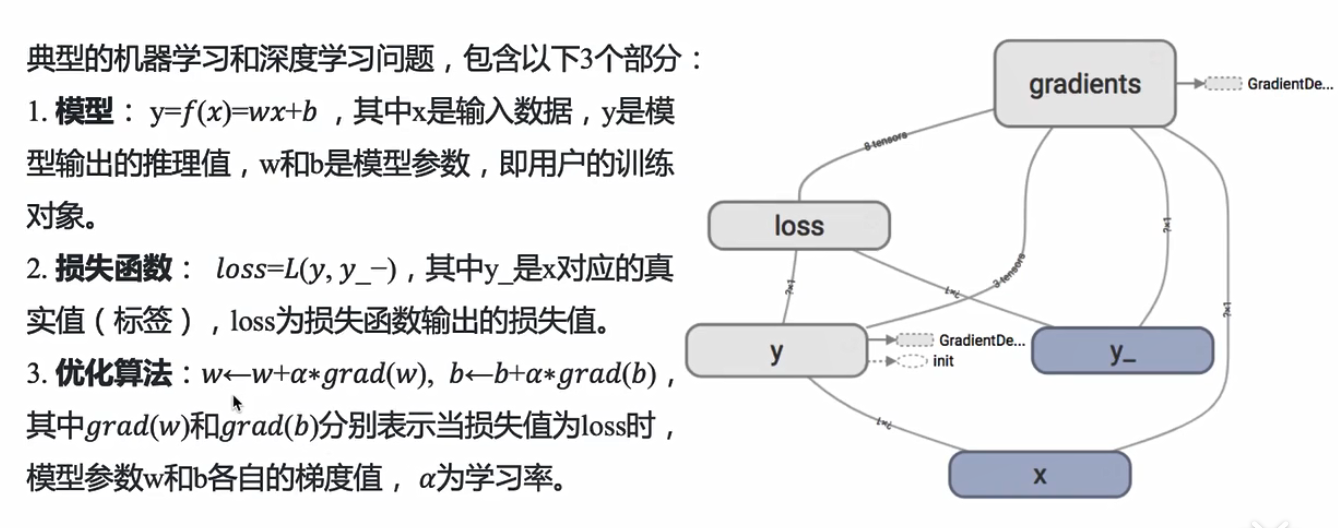
6.模型的训练机制
二、优化器
1.优化器
优化器是实现优化算法的载体。
- 计算梯度:调用compute_gradients方法
- 处理梯度:用户按照自己需求处理梯度值,如梯度裁剪和梯度加权等
- 应用梯度:调用apply_gradients方法,将处理后的梯度值应用到模型参数。
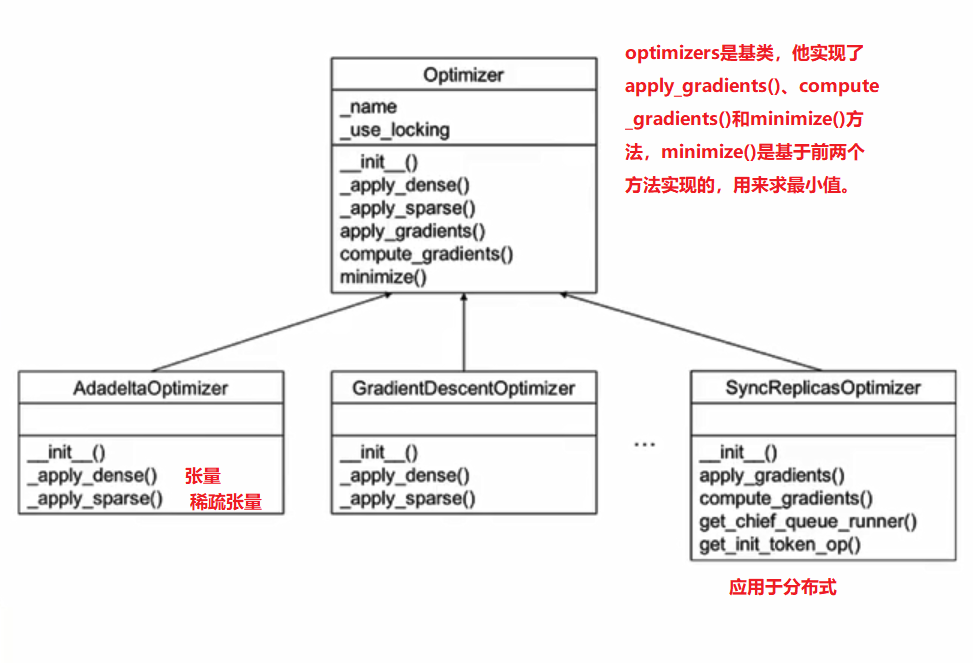
所有优化器的核心都是继承于基类optimizer优化器的计算梯度(compute_gradients)和应用梯度(apply_gradients)方法。
2.GradientDescentOpertimizer优化器使用流程
基于optimizer优化器的优化器中,梯度下降优化器(GradientsDescentOptimizer)用的比较多。
下面是其应用的一般化方法:
(1)需要处理梯度值
# 1.构建优化器
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01) # 构建优化器 learning_rate是学习转换率
# 2.计算梯度var_list是变量列表
grads_and_vars = optimizer.compute_gradients(loss, var_list, ...) # loss是损失值, var_list是变量列表
# 3.处理梯度
clip_grads_and_vars = [(tf.clip_by_value(grad, -1.0, 1.0), var) for grad, var in grads_and_vars]
# 4.应用梯度
train_op = optimizer.apply_gradients(clip_grads_and_vars) # train_op是单步训练后的最后操作,用会话执行train_op就相当于执行整个数据流图
(2)不需要处理梯度值
# 1.构建优化器
optimizer = tf.train.GradientDescentOptimizer(learning_rate=0.01)
# 2.设置变量
globel_step = tf.Variable(0, name='globel_step', trainable=False)
# 3.计算并应用梯度模型
train_op = optimizer.minimize(loss, var_list, ...)
3.tensorflow内置优化器路径

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/84747.html

