
python对.csv格式的文件进行I/O常规操作
一、csv简介
CSV (Comma Separated Values),即逗号分隔值(也称字符分隔值,因为分隔符可以不是逗号),是一种常用的文本格式,用以存储表格数据,包括数字或者字符。很多程序在处理数据时都会碰到csv这种格式的文件,它的使用是比较广泛的(Kaggle上一些题目提供的数据就是csv格式),csv虽然使用广泛,但却没有通用的标准,所以在处理csv格式时常常会碰到麻烦,幸好python内置了csv模块。下面简单介绍csv模块中最常用的一些函数。
二、写文件
1.介绍下writer()函数:
writer(csvfile, dialect='excel', **fmtparams)
参数:csvfile,必须是支持迭代(Iterator)的对象,可以是文件(file)对象或者列表(list)对象
dialect,编码风格,默认为excel的风格,也就是用逗号(,)分隔,dialect方式也支持自定义
fmtparam,格式化参数,用来覆盖之前dialect对象指定的编码风格。
一般我们只会用带形参csvfile,另外两个参数没有涉及
2.常用的数据写入语法:
import csv
# newline=''用来解决空行的问题
with open('D:\\python\\csv文件操作\\测试.csv', 'w', newline='') as csv_file:
csv_writer = csv.writer(csv_file)
head = ['姓名', '班级', '成绩'] # 构造标题信息
# 构造内容
rows = [
['王豪', '1702', '100'],
['李梦', '1702', '90']
]
'''
rows里面用()也行,但是推荐用上面的
rows = [
('张三', '1702', '100', ''),
('李四', '1702', '90')
]
'''
csv_writer.writerow(head) # 注意:这里是写入一行
csv_writer.writerows(rows) # 注意:这里是写入多行
print("写入成功!")
3.效果:
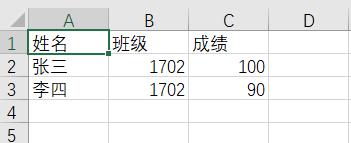
三、读文件
1.介绍下reader()函数:
reader(csvfile, dialect='excel', **fmtparams)
其参数的含义和writer()函数的参数含义一样
2.常用的数据写入语法:
import csv
with open('D:\\python\\csv文件操作\\测试.csv', 'r', newline='') as cvs_file:
csv_reader = csv.reader(cvs_file)
# 读取第一行的头信息(标题信息)
head = next(csv_reader)
print(head)
for row in csv_reader:
print(row)
'''
也可以直接转为列表
print(list(csv_reader))
'''
注意:csv_reader 是一个生成器,是一个惰性的可迭代对象,第一次迭代后,再往后迭代,他不会从头开始,而是从之前第一次迭代完的地方开始,再迭代。所以,我们可以用for循环来迭代,也可以用list来迭代。
这里,我稍微解释一下为什么这里用生成器,因为,如果当数据太大的时候,比如有10G,全读出来内存就炸了,用生成器的好处就是,每次迭代只取一行,这样就比较安全。
3.结果:
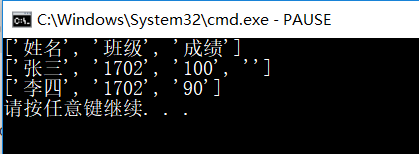
4.如果想读取某一行的信息:
import csv
data = []
with open('D:\\python\\csv文件操作\\测试.csv', 'r', newline='') as cvs_file:
csv_reader = csv.reader(cvs_file)
# 读取第一行的头信息(标题信息)
head = next(csv_reader)
data = list(csv_reader)
print(data)
print(data[1])
# 结果:
[['张三', '1702', '100', ''], ['李四', '1702', '90']]
['李四', '1702', '90']
5.使用DictReader,和reader函数类似,接收一个可迭代的对象,能返回一个生成器,但是返回的每一个单元格都放在一个字典的值内,而这个字典的键则是这个单元格的标题(即列头)。用下面的代码可以看到DictReader的结构:
import csv
data = []
with open('D:\\python\\csv文件操作\\测试.csv', 'r', newline='') as cvs_file:
csv_reader = csv.DictReader(cvs_file)
data = [row for row in csv_reader]
print(data)
# 结果:
[OrderedDict([('姓名', '张三'), ('班级', '1702'), ('成绩', '100'), (None, [''])]), OrderedDict([('姓名', '李四'), ('班级', '1702'), ('成绩', '90')])]
如果要用该方法获取数据列的第一列的成绩:
import csv
data = []
with open('D:\\python\\csv文件操作\\测试.csv', 'r', newline='') as cvs_file:
csv_reader = csv.DictReader(cvs_file)
data = [row for row in csv_reader]
print(data[0]['成绩'])
# 结果:
100

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/84790.html

