
用scrapy框架爬取腾讯新闻实战
文章目录
一、知识要求
- 掌握python基础语法
- 异常处理
- 会建立和简单使用scrapy框架
- 会抓包分析
二、爬取腾讯新闻实战
1.通过分析获取存放每个新闻链接的网址
(1)分析网页源代码中是否有新闻的链接:
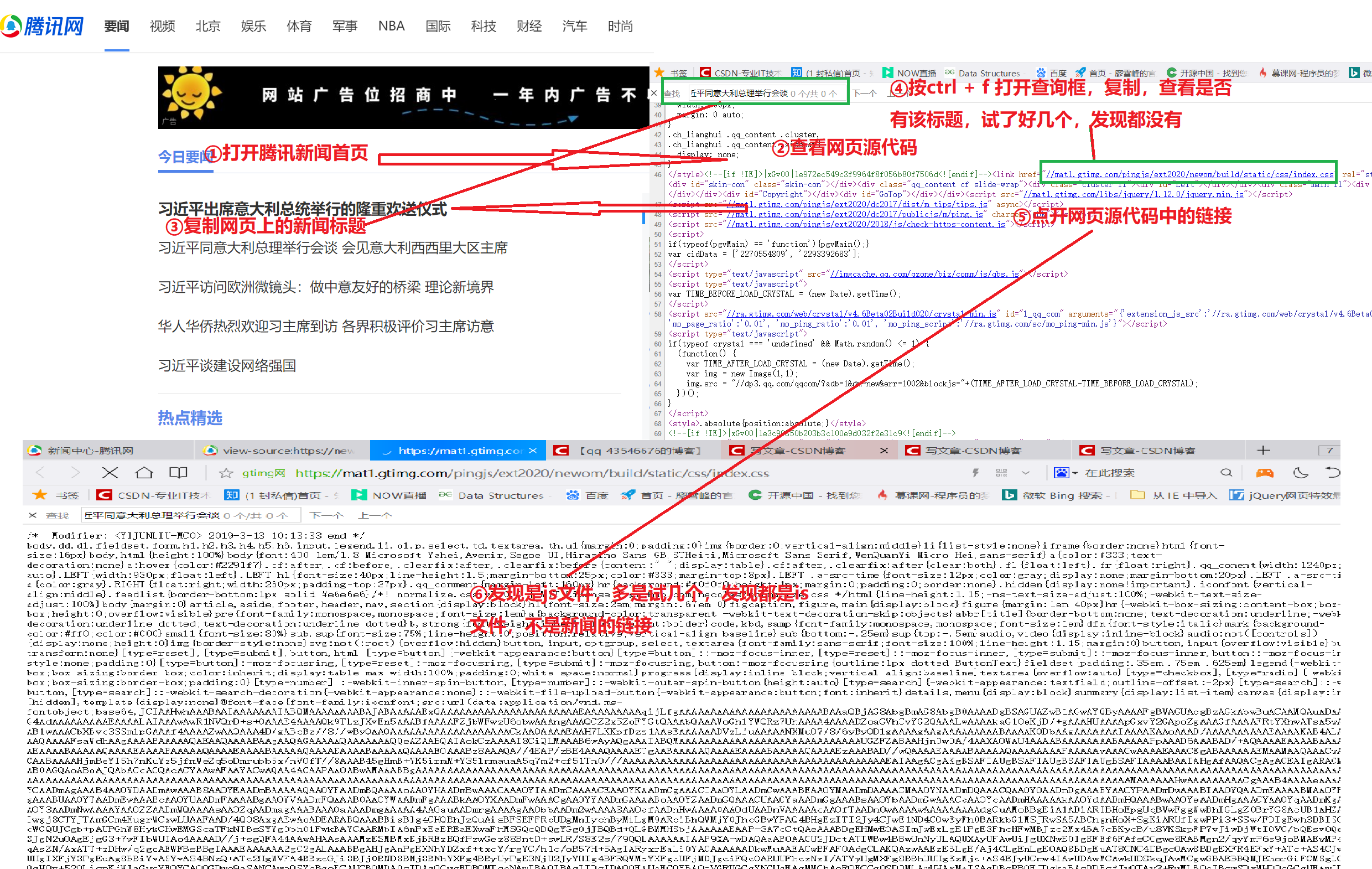

通过分析,我们发现网页源代码中不含有新闻链接,但是,有很多js包,由此,我们自然的想到抓包分析。
(2)抓包分析:
①打开安装过代理的浏览器,我这里是火狐浏览器,然后进入到腾讯新闻首页
②打开抓包分析的工具Fiddler,然后用clear命令清空列表。如下:
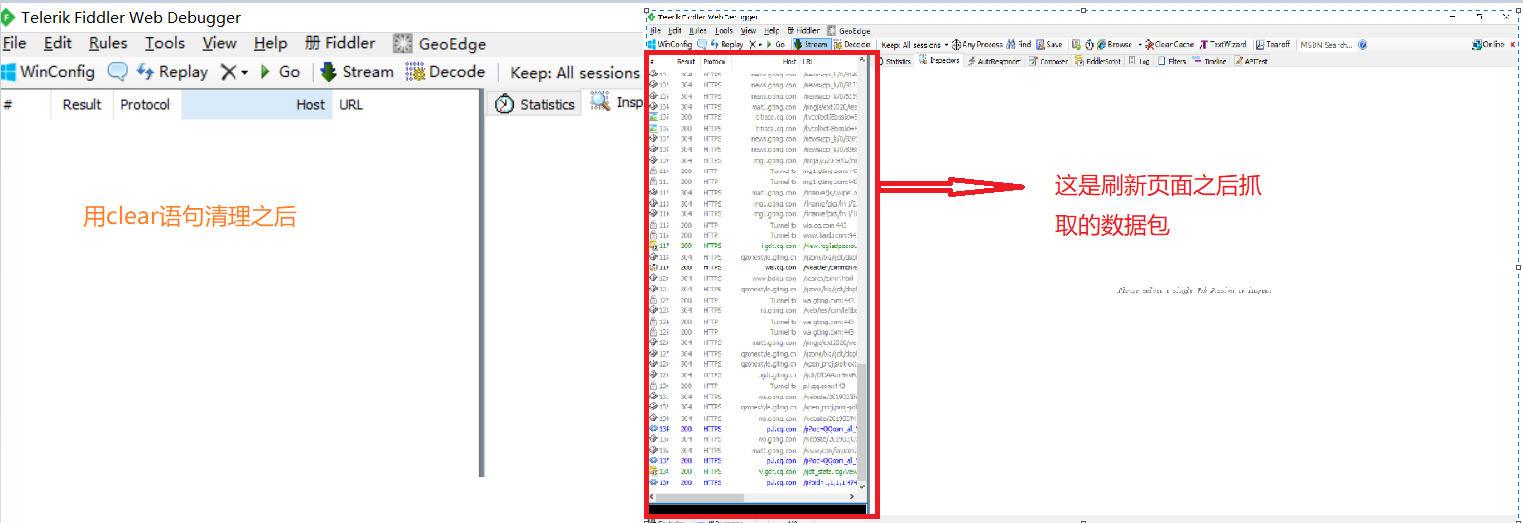
③在火狐浏览器中刷新腾讯首页,Fiddler中会出现抓取一些数据包:
④通过看包分析,发现带有/irs/rcd?cid的js包含有新闻的链接和标题,所以我们的任务是要找到所有的这样的js包的网址:
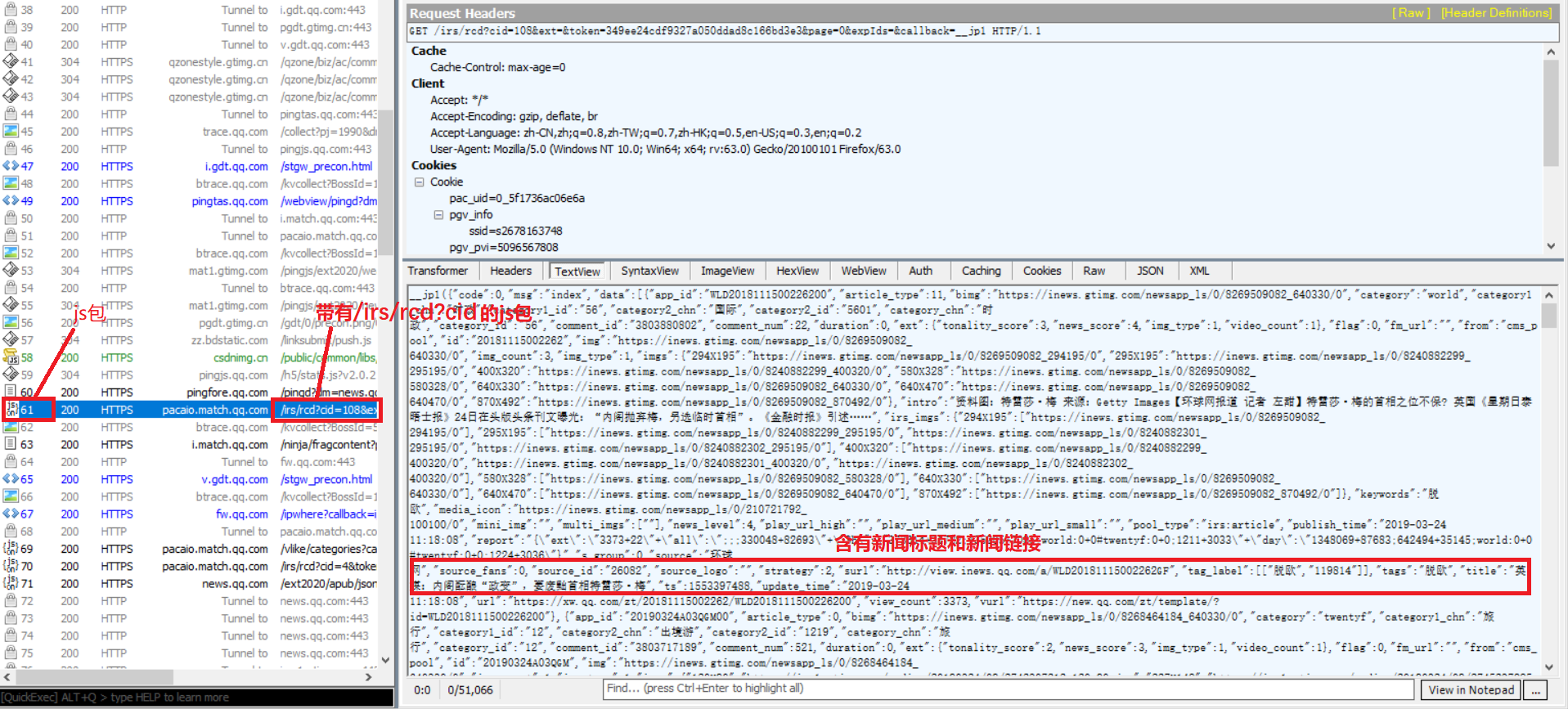
④找出所有的这样的js包,复制其网址,找出规律:发现第一个js包和第二个js包的网址没有规律,从第三个js包开始就有规律了,有这样的规律:https://pacaio.match.qq.com/irs/rcd?cid=108&ext=&token=349ee24cdf9327a050ddad8c166bd3e3&page=6&callback=__jp9其中page=6是第4个js包,jp9总是比前面的page=的值大3,所以,我们通过构造page的值和jp的值,就可以构造出js包的网址。

2.创建数据库来存放爬取的新闻标题和链接
这里,我创建了一个名为tengxun的数据库,并在该数据库中建立了一张名为news的表:

3.创建并编写一个爬取爬取腾讯新闻的scrapy项目
(1)创建该爬虫项目和爬虫文件我就不多做说明了,如果不会可以点我,我创建的项目如下:
(2)编写爬虫项目:
①item.py文件:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class TengxunnewsItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field() # 设置标题容器
link = scrapy.Field() # 设置链接容器
②tx.py文件:
# -*- coding: utf-8 -*-
import scrapy
from tengxunnews.items import *
from scrapy.http import Request
import re
class TxSpider(scrapy.Spider):
name = 'tx'
allowed_domains = ['qq.com'] # 允许爬取的网址的域名
# 第一次爬取的网址,虽然写出是两行,实际是一行,只是很长换成两行了
start_urls = ['https://pacaio.match.qq.com/irs/rcd?cid=108&'
'ext=&token=349ee24cdf9327a050ddad8c166bd3e3&page=0&expIds=&callback=__jp1']
# 来存放所有的js包地址
allLink = ['https://pacaio.match.qq.com/irs/rcd?cid=108&ext=&token=349ee24cdf9327a050ddad8c166bd3e3&page=0&expIds=&callback=__jp1',
'https://pacaio.match.qq.com/irs/rcd?cid=4&token=9513f1a78a663e1d25b46a826f248c3c&ext=&page=0&expIds=&callback=__jp2']
# 后面再爬取7个js文件,总共爬取9个js文件
for i in range(0, 7):
# 构造每个js文件的地址
url = 'https://pacaio.match.qq.com/irs/rcd?cid=108&ext=&token=349ee24cdf9327a050ddad8c166bd3e3&page='+str(i+1)+'&callback=__jp'+str(i+4)
allLink.append(url) # j将构造的js包网址追加到allLink列表中
def parse(self, response):
# 爬取每个js包的数据
for link in self.allLink:
yield Request(link, callback=self.next)
def next(self, response):
# 获取每个js包内存放的新闻标题和新闻链接
item = TengxunnewsItem()
data = response.body.decode("utf-8", "ignore")
pat1 = '"title":"(.*?)"'
pat2 = '"surl":"(.*?)"'
item["title"] = re.compile(pat1).findall(data)
item["link"] = re.compile(pat2).findall(data)
yield item
③pipelines.py文件:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymysql
class TengxunnewsPipeline(object):
def __init__(self):
# 链接数据库
self.conn = pymysql.connect(host="127.0.0.1", user="root", passwd="wanghao211", db="tengxun")
self.cursor = self.conn.cursor()
def process_item(self, item, spider):
for i in range(0, len(item["title"])):
sql = "insert into news(title, link) values('{}', '{}')".format(item["title"][i], item["link"][i])
# print(sql)
# 将sql语句写入数据库
try:
self.cursor.execute(sql)
self.conn.commit()
except Exception as err:
# 如果发生错误,立即回滚
self.conn.rollback()
# 并打印出错误
print(err)
print("信息写入数据库成功!")
return item
def close_spider(self, spider):
# 关闭数据库
self.cursor.close()
self.conn.close()
4.运行项目
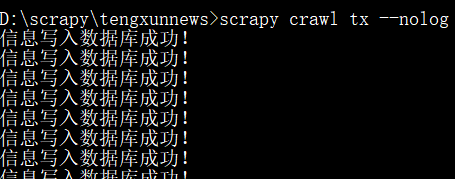
(1)运行项目:
(2)到数据库中查看结果:
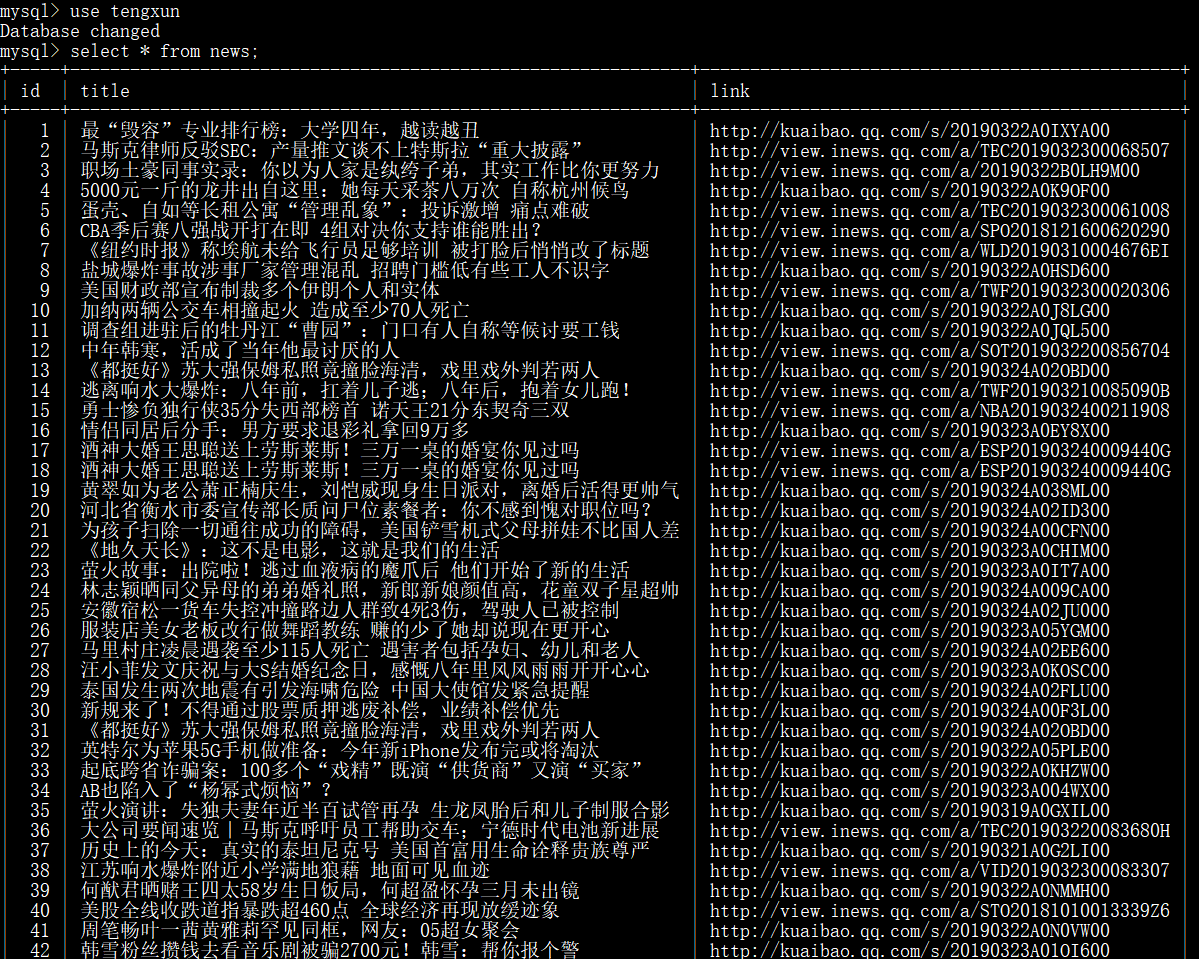
写数据库入成功!!!
(3)复制第一个一个网址,进入:
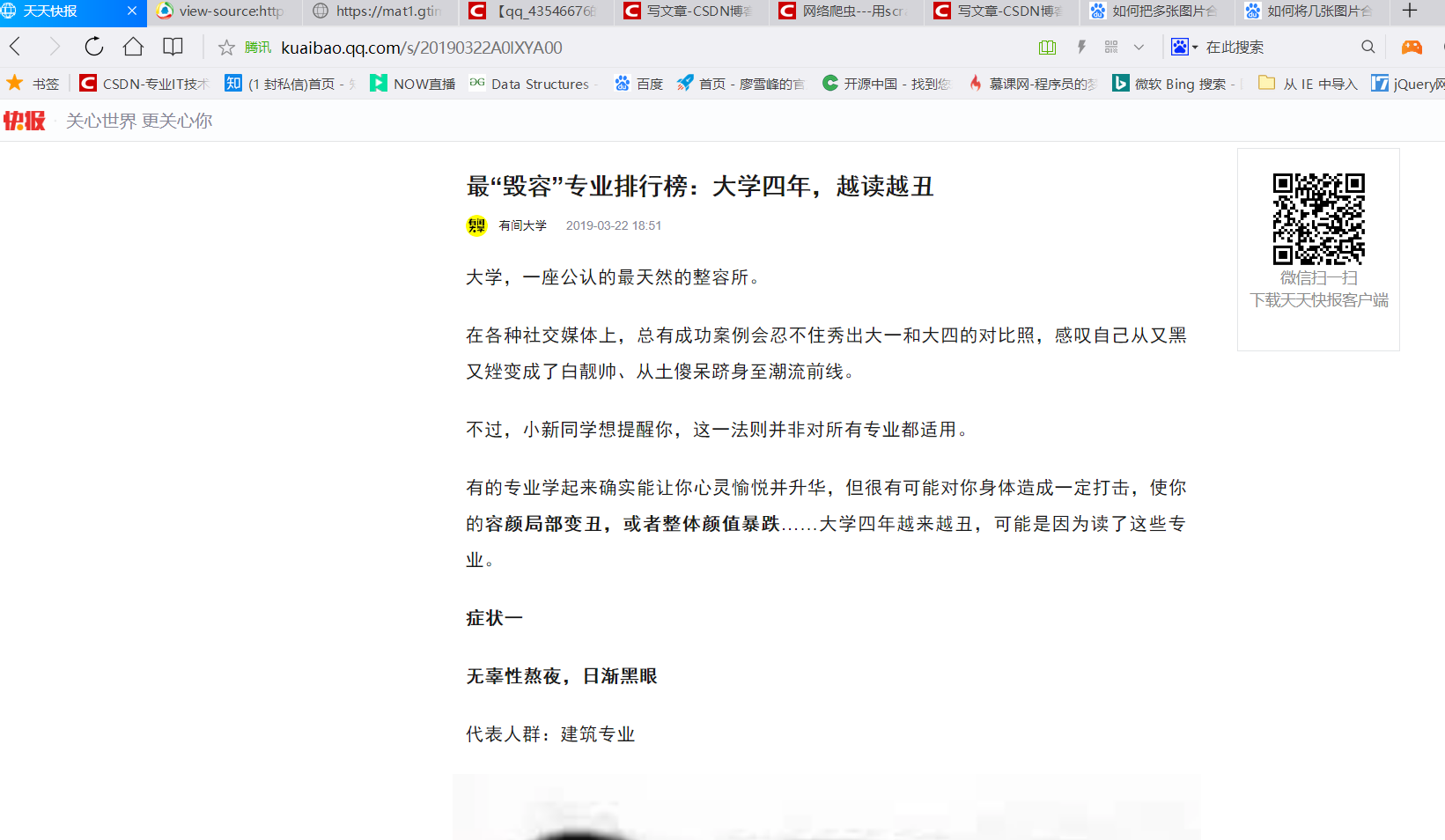
与其标题相符合,确实就是该文章的链接。
(4)至此,实战成功!!!

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/84804.html

