
用scrapy框架爬取当当网商品信息实战
1.用scrapy框架创建项目
(1)打开cmd,你想到到哪里创建scrapy爬虫项目,就用cd指令,进入到相应的路径。
(2)输入:scrapy startproject dangdang,后面的dangdang是项目名,这样你就建立了一个scrapy爬虫项目。
2.scrapy项目文件简介
进入到你所创建的scrapy爬虫项目,里面有如下几个文件:
spiders文件夹用来存放爬虫文件,里面的__init__.py文件为初始化文件。__init__.py为初始化文件items.py用来放爬取的目标,对象middlewares.py是一个中间件文件,比如存放IP代理和用户代理pipelines.py主要是爬取信息后的处理,比如数据是打印处理,还是存放在文件中等等
注意:Scrapy 默认会过滤重复的 URL,不会重复抓取相同的 URL,除非显式指定。
3.在scrapy框架下的爬虫文件
(1)scrapy genspider -l用来查看爬虫文件有哪些文件模板
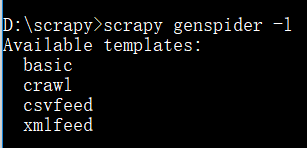
basic模板是基础模板,crawl模板主要是做自动爬虫,csvfeed是爬取csv格式的爬虫文件xmlfeed是爬取xml格式的爬虫文件
(2)建立爬虫文件:
scrapy genspider -t basic dd baidu.com
说明:basic是基础模型的爬虫文件,dd是爬虫文件名,baidu.com是允许爬取的域名。
(3)运行scrapy项目下的爬虫文件
scrapy crawl dd
注意:不在scrapy项目下的爬虫文件用scrapy runspider +文件名来运行
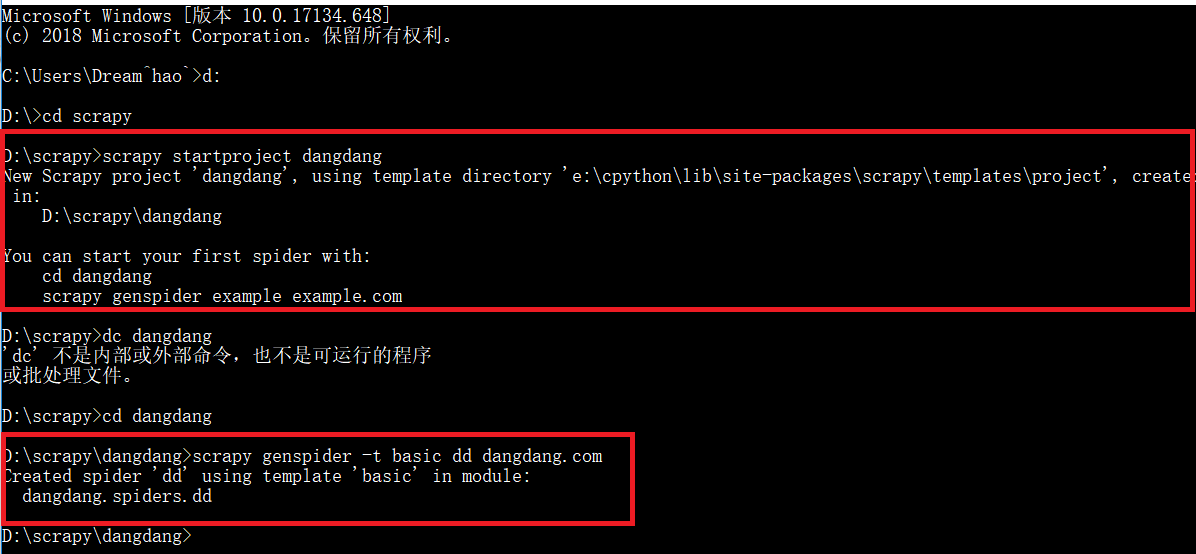
4.用scrapy框架爬取当当网商品信息实战
(1)先用命令行创建scrapy项目和一个爬虫文件。
创建scrapy项目:scrapy startproject <project_name>
创建爬虫文件:scrapy genspider [-t template] <name> <domain>
(2)在pycharm中点击File,再点击open导入该scrapy项目,可以在左边看见项目。
(3)点击items.py编辑文件:
创建容器,顾名思义就是要创建一个来存放爬取的数据东西,也就是创建Item。
这里我们要获取什么信息就设置什么变量,即设置什么容器。这里,我们要获取标题、对应链接和评论数,所有定义三个变量:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class DangdangItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
link = scrapy.Field()
comment = scrapy.Field()
(2)点击dd.py,编辑,要注意item["title"]不是item.title,它是一个键值对
# -*- coding: utf-8 -*-
import scrapy
from dangdang.items import *
from scrapy.http import Request
class DdSpider(scrapy.Spider):
# 一般和爬虫文件名一样
name = 'dd'
# 允许爬取域名为'dangdang.com'的网址
allowed_domains = ['dangdang.com']
# 第一次爬取的网址
start_urls = ['http://category.dangdang.com/cid4008149.html']
# response是爬取网页信息后返回的信息
def parse(self, response):
item = DangdangItem()
# item是一个字典dict,下面为每个key的value赋值都为一个列表
# response.xpath('//a[@name="itemlist-title"]/@title').extract()返回的是一个列表
item["title"] = response.xpath('//a[@name="itemlist-title"]/@title').extract()
item["link"] = response.xpath('//a[@name="itemlist-title"]/@href').extract()
item["comment"] = response.xpath('//a[@name="itemlist-review"]/text()').extract()
yield item
#接着爬取第一页之后的页面信息
for i in range(2, 4):
url = 'http://category.dangdang.com/pg' + str(i+1) + '-cid4008149.html'
yield Request(url, callback=self.parse)
(3)打开命令行输入:scrapy crawl dd --nolog运行爬虫文件,也是运行爬虫项目,因为,爬虫文件相当于是爬虫项目的入口。
语法:scrapy crawl <spider>
结果:
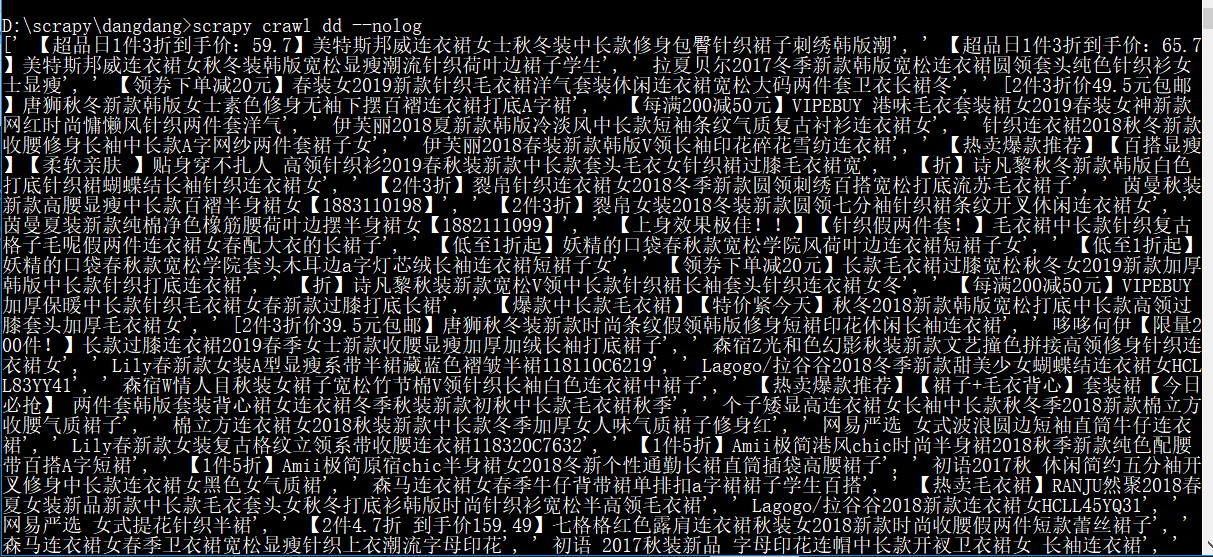
由上图可以看见,能爬取信息。
到此,用scrapy框架爬取当当网商品信息已经成功!接下来,更进一步,我们可以将爬取到的商品信息存放到数据库中。
(4)打开pipelines.py文件
上面只是检查能否爬取信息,而对于爬取指定信息后的处理需要交给pipelines.py文件处理,比如写入到文件中,或者写入到数据库等等,所以,上面第(2)步中的print(item["title"])不应该写在那里,应该写在pipelines.py文件中。但是,该文件默认是关闭的,我们需要在settings.py文件中去将pipelines.py开启。步骤:在settings.py文件中,按ctrl + f搜索pipe,会定位到下面位置:
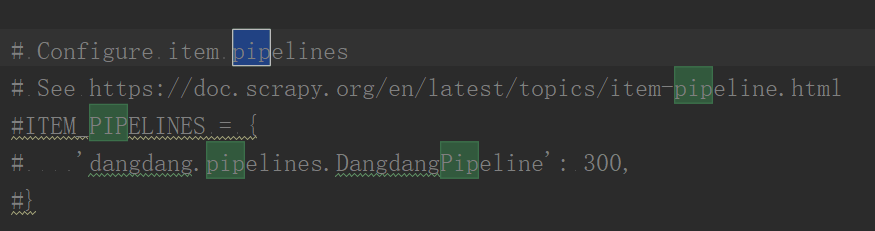
然后去掉注释符就可以了,这样就开启pipelines.py文件了
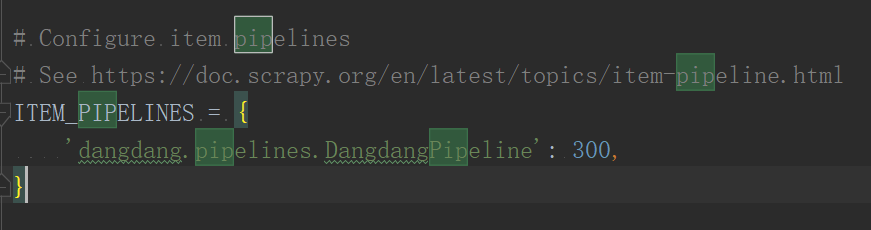
(5)编写pipelines.py文件
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymysql
class DangdangPipeline(object):
def __init__(self):
# 链接数据库
self.connect = pymysql.connect(host="127.0.0.1", user="root", passwd="wanghao211", db="dangdang")
self.cursor = self.connect.cursor()
def process_item(self, item, spider):
#将爬取的数据写入数据库
for i in range(0, len(item["title"])):
title = item["title"][i]
link = item["link"][i]
comment = item["comment"][i]
sql = "insert into goods(title, link, comment) values('"+title+"','"+link+"','"+comment+"')"
print(sql)
try:
self.cursor.execute(sql)
#提交操作
self.connect.commit()
except Exception as err:
# 发生错误时回滚
self.connect.rollback()
print(err)
return item
def close_spider(self,spider):
self.cursor.close()
self.connect.close()
(5)在命令行中运行该爬虫文件,即输入scrapy crawl dd --nolog,得到结果:

查看数据库中是否写入数据:
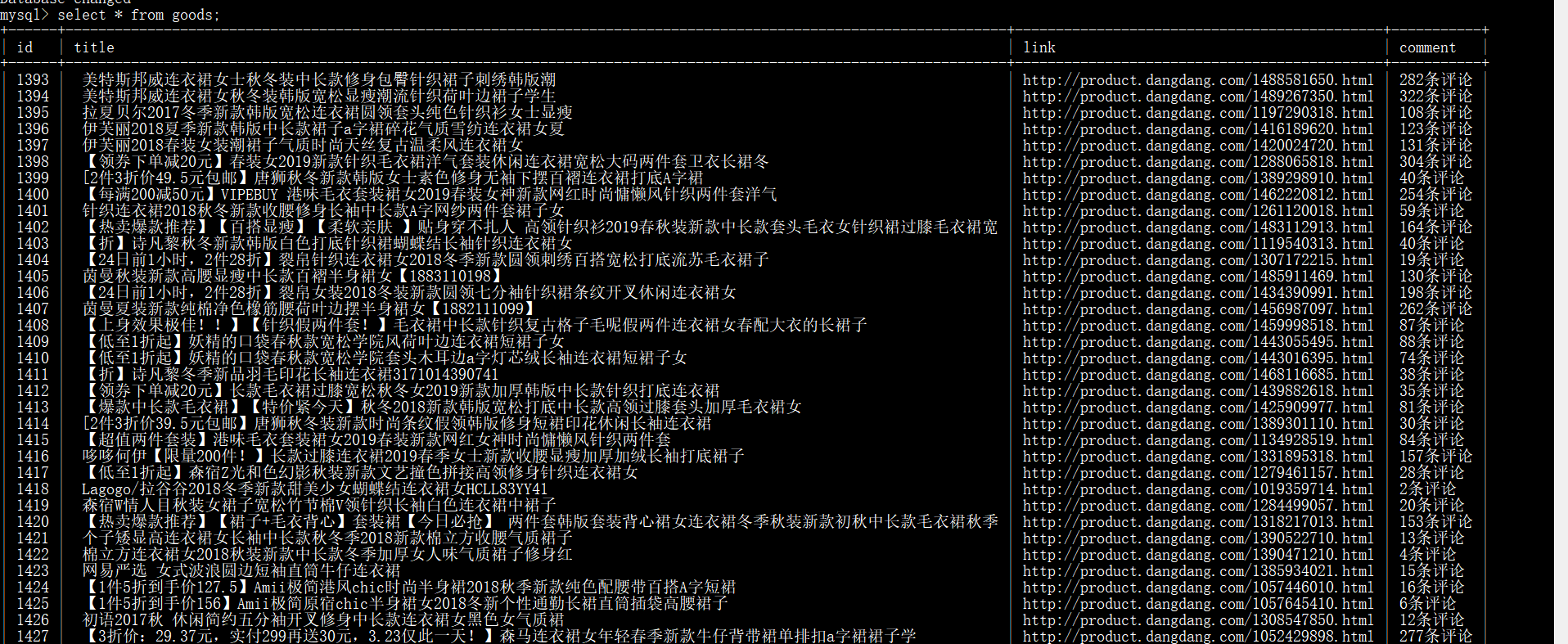
商品从1393开始,是因为我把之前的表中数据以记录日志的方式清除了,所以,这里的id还是接着之前的数据在自增长。
但是,可以看见,商品信息写入数据库成功!

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/84806.html

