
Python网络爬虫
1.知识要求
如果你对相关知识有些遗忘,可以点上面的链接,熟悉一下相关知识点。
2.用户代理池
说明:如果我们只是单一的用一个用户代理去不断爬取博客,来增加访问量,会被网站后台发现,可能导致你的用户代理在一段时间内禁止访问该博客,很不安全。所以,我们要多建立几个用户代理,每次随机的选一个用户代理去访问博客,这样相对来说就要安全很多。将你获得的所以用户代理放在一个list中就构成了一个用户代理池,获取用户代理有两个方法:
(1)用自己电脑下载不同的浏览器,同一电脑使用不同浏览器的用户代理是不一样的。下面是我自己QQ浏览器和Google浏览器的用户代理,你会发现是不一样的。
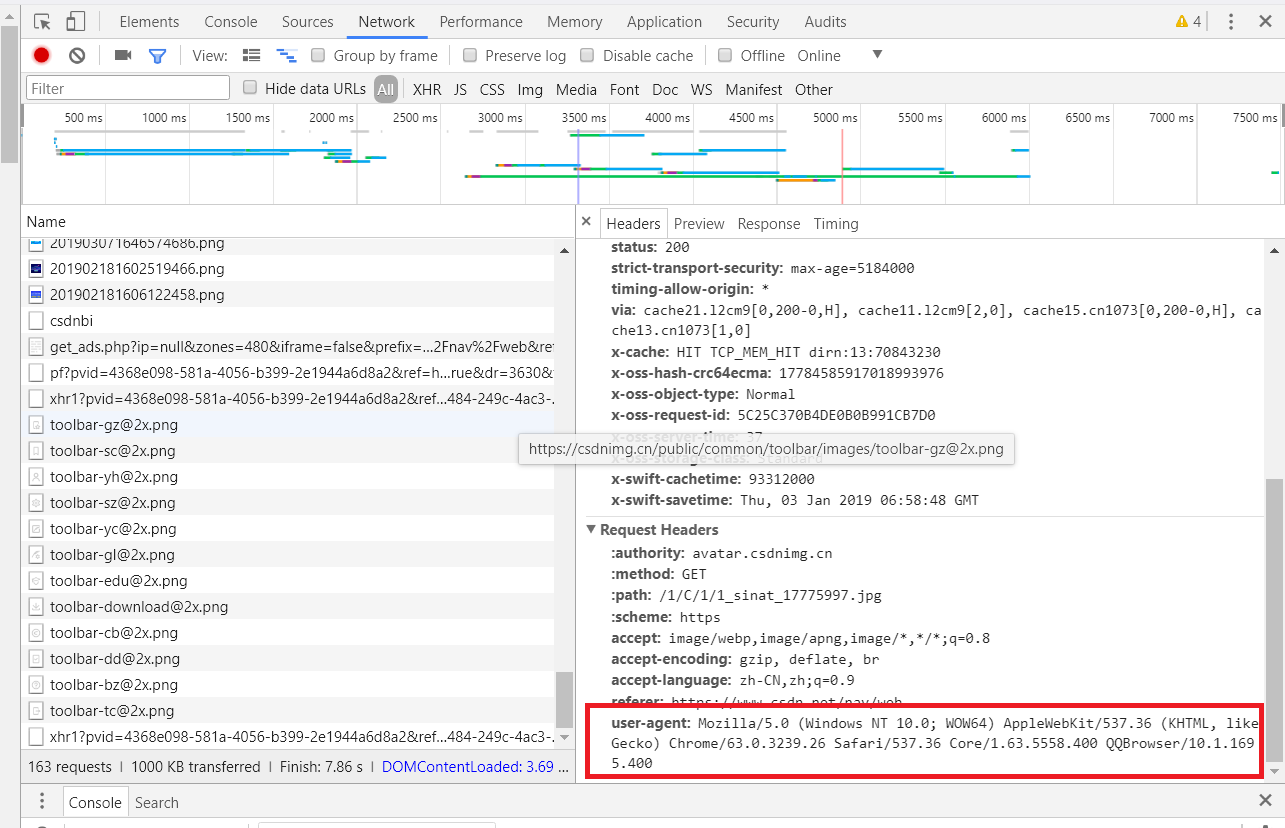
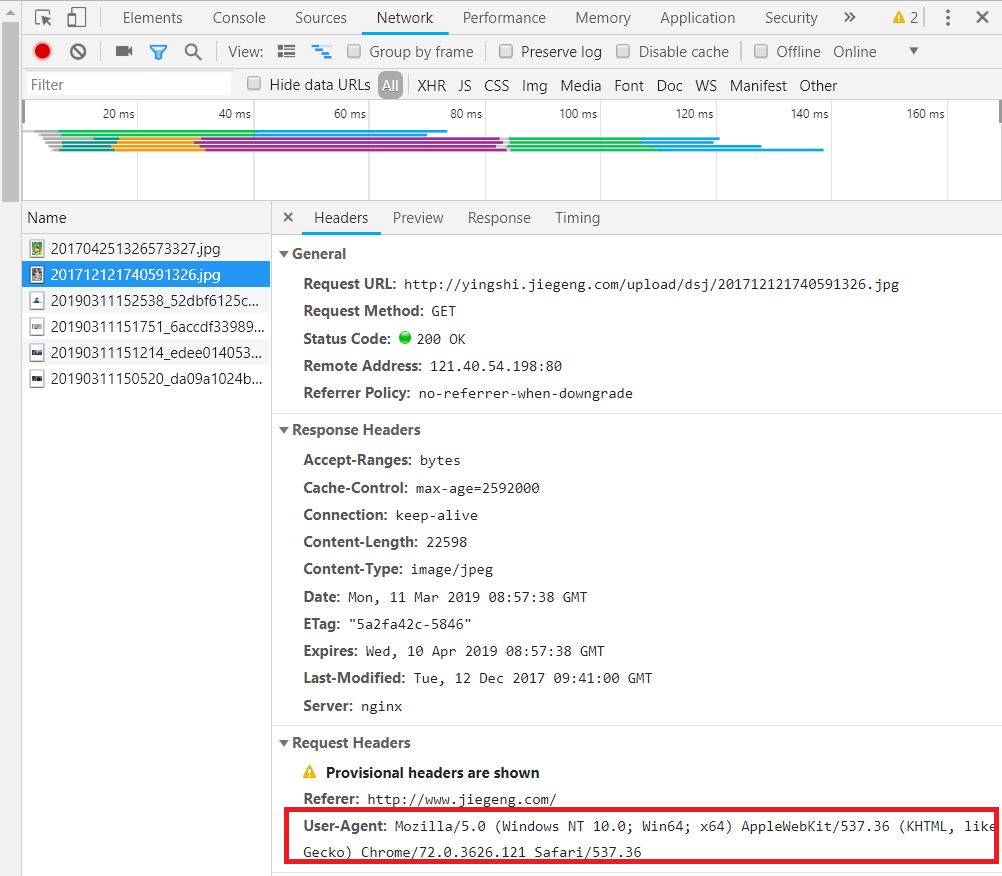
(2)百度搜索User-Agent复制一些用户代理

3.爬取CSDN个人博客,增加博客阅读量实战
#为csdn博客刷阅读量
import urllib.request
import urllib.error
import random
import socket #为了防止访问链接超时(timeout),而需要导入的模块
#要访问的网址,多弄几个,然后用随机的方法选取,这样更安全
urls = [
'https://blog.csdn.net/qq_43546676/article/details/88385755',
'https://blog.csdn.net/qq_43546676/article/details/88365136',
'https://blog.csdn.net/qq_43546676/article/details/88356667',
'https://blog.csdn.net/qq_43546676/article/details/87953860',
'https://blog.csdn.net/qq_43546676/article/details/87865197',
'https://blog.csdn.net/qq_43546676/article/details/87907607',
'https://blog.csdn.net/qq_43546676/article/details/88121447',
'https://blog.csdn.net/qq_43546676/article/details/88210284',
'https://blog.csdn.net/qq_43546676/article/details/86678908'
]
#用户代理池,对于同一台电脑来说,不同的浏览器的用户代理也是不一样的
ua_pools = [
'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5558.400 QQBrowser/10.1.1695.400',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; .NET4.0E; SE 2.X MetaSr 1.0)',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; Media Center PC 6.0; InfoPath.3; .NET4.0C; .NET4.0E)',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)'
]
#随机获取一个访问网址
def getUrl(urls):
this_url = random.choice(urls)
return this_url
#随机获取一个报头,并安装为全局
def ua(ua_pools):
ua = random.choice(ua_pools)
headers = ('User-Agent', ua)
opener = urllib.request.build_opener()
opener.addheaders = [headers]
#设置为全局
urllib.request.install_opener(opener)
#访问10000次
for i in range(0, 10000):
#异常处理,使程序变的健壮,遇到错误之后还能继续爬取信息
try:
#随机获取一个网址
url = getUrl(urls)
#随机获取并安装一个报头
ua(ua_pools)
data = urllib.request.urlopen(url, timeout=2).read().decode('utf-8', 'ignore')
#print(len(data))
except urllib.error.HTTPError as e:
if hasattr(e, 'code'):
print(e.code)
if hasattr(e, 'reason'):
print(e.reason)
except socket.timeout as e: #为了防止访问链接超时(timeout)
print(e)
print('爬取成功!')
后面我们会用更加安全的一种方式,即IP代理与用户代理结合的方式去爬取网页来增加访问量,链接在此处

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/84810.html

