
Python网络爬虫
1.爬虫的异常处理实战
说明:爬虫在运行过程中会遇到很多异常,而通过异常处理可以使我们的爬虫变得健壮,不轻易崩溃。异常处理我们主要是通过URLError和HTTPError这两个异常处理类来处理异常的。
(1)URLError只会返回异常原因
(2)HTTPError会返回异常状态码和异常原因
注意:HTTPError是URLError的子类
下面介绍几种常见的状态码:
- 200 正常爬取
- 301 Moved Permanently:重定向到新的URL,永久性
- 302 Found:重定向到临时的URL,非永久性
- 304 Not Modified:请求的资源未更新
- 400 Bad Request:非法请求,设置了反爬技术
- 401 Unauthrized:请求未经授权
- 403 Forbidden:不允许访问那个资源
- 500 Internal Server Error:服务器内部资源出故障了
- 503 Service Unavailable:服务器不支持实现请求所需要的功能
eg:
import urllib.request
import urllib.error #要导入该模块
#异常处理基本上都是下面这个模板
try:
pass
except urllib.error.HTTPError as e:
if hasattr(e, 'code'):
print(e.code)
if hasattr(e, 'reason'):
print(e.reason)
2.浏览器伪装技术实战
说明:由于urlopen()对于一些高级功能不支持,很容易被网站发现是爬虫,而被禁止访问,导致爬取信息失败。这个时候,我们需要伪装成浏览器,再去爬取网页信息。
我们可以通过用urllib.request.build_opener()或者urllib.request.Request()下的add_header()来添加报头,实现浏览器的伪装技术。
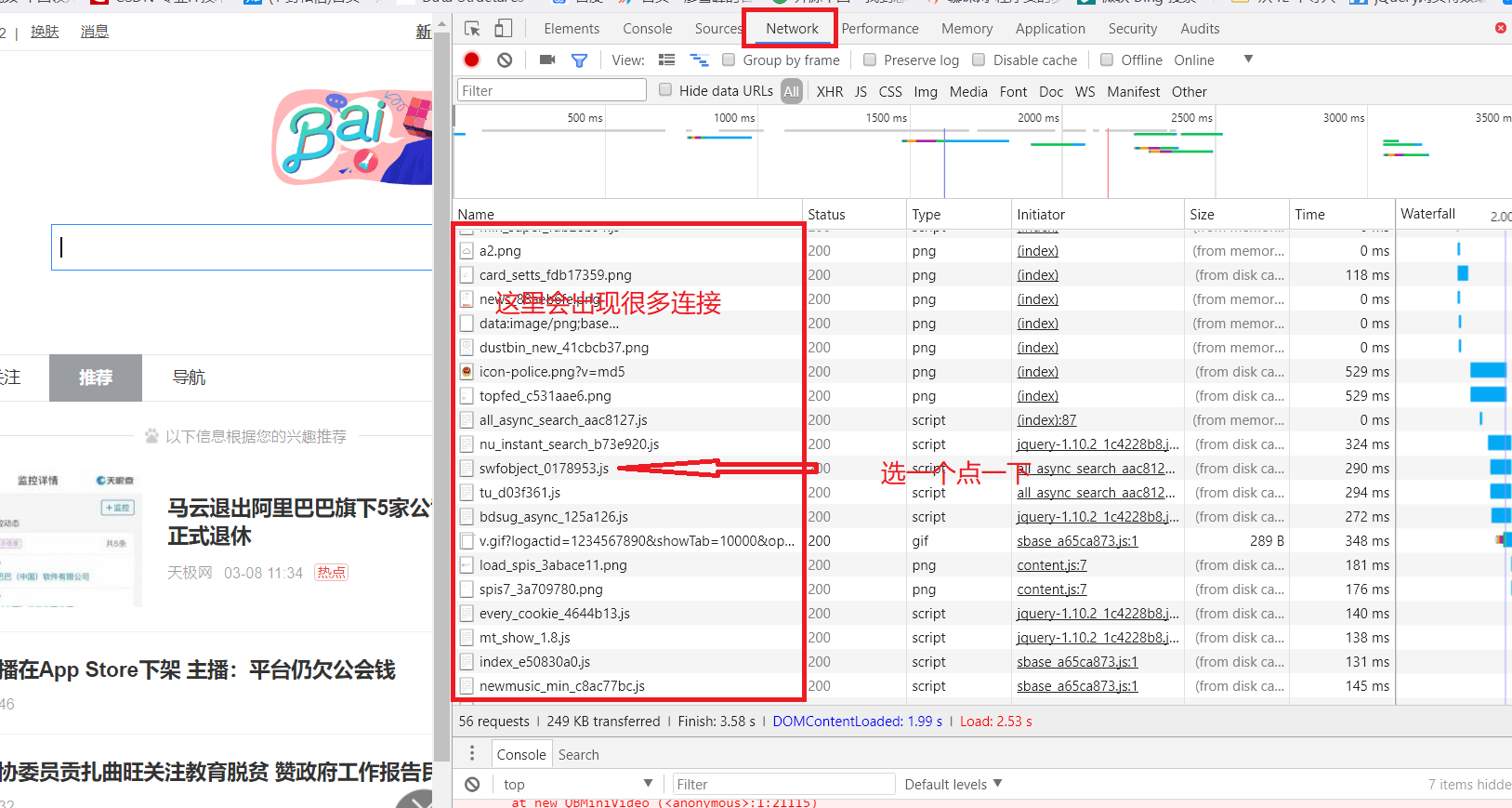
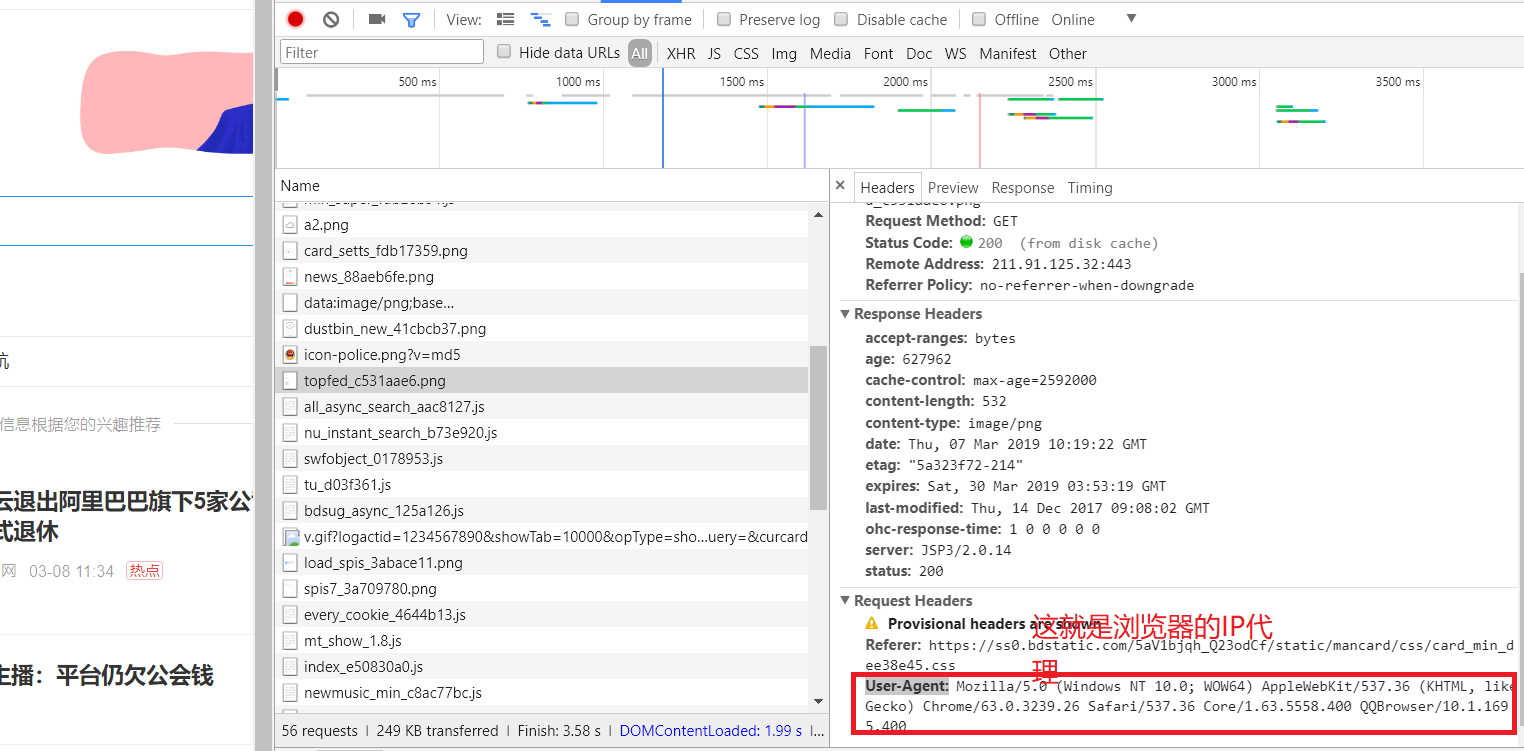
(1)首先,我们需要找到浏览器的用户代理。即在你要爬取的网站页面按F12,点击network,然后随便点击要爬取网页上的随便一个连接,你会发现有很多连接显示出来,随便选一个点一下,然后找到Headers下面的User-Agent:,User-Agent:后面的一串东西就是浏览器的用户代理。

(2)利用浏览器的用户代理让爬虫伪装成浏览器
①用urllib.request.build_opener()伪装
eg:
#导入urllib.request模块
import urllib.request
#要爬取的网站
url = "https://www.zhihu.com/"
#设置请求报头 头文件格式 headers = ("User-Agent", 用户具体代理值)
headers = ("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5558.400 QQBrowser/10.1.1695.400")
#创建一个opener
opener = urllib.request.build_opener()
#将headers添加到opener中
opener.addheaders = [headers]
#用opener.open()打开网页
data = opener.open(url).read().decode('utf-8')
print(len(data))
以上代码是用opener.open()直接打开网页,那么如何将opener安装成全局变量,从而方便我们的信息爬取?(因为我们爬取信息是用的urlopen()方法,如果不统一,会降低我们爬取信息的效率)
我们可以用urllib.request.install_opener(opener)方法将opener安装为全局,上面的代码可优化为:
#导入urllib.request模块
import urllib.request
#要爬取的网站
url = "https://www.zhihu.com/"
#设置请求报头 头文件格式 headers = ("User-Agent", 用户具体代理值)
headers = ("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.26 Safari/537.36 Core/1.63.5558.400 QQBrowser/10.1.1695.400")
#创建一个opener
opener = urllib.request.build_opener()
#将headers添加到opener中
opener.addheaders = [headers]
#将opener安装为全局
urllib.request.install_opener(opener)
#用urlopen()方法打开网页
data = urllib.request.urlopen(url).read().decode('utf-8')
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/84813.html

