
Python网络爬虫
1.urllib基础
urlretrieve(“网址”, "本地文件存储地址")方法,用来将文件下载到指定路径urlcleanup()方法,用来清除内存中爬取的网页内容urlopen()方法,用来爬取网页信息info()方法,看爬取的网页的简介信息getcode()方法,用来返回网页爬取的状态码,如果返回200表示处于爬取状态,反之,不处于geturl()方法,用来获取当前访问的网页的url
eg:
import urllib.request,re
sock = urllib.request.urlopen("https://www.baidu.com/")
data = sock.read().decode("utf-8")
urllib.request.urlretrieve("https://www.baidu.com/", "D:\\python\\1.html")
urllib.request.urlcleanup()
print(sock.info())
print(sock.getcode())
print(sock.geturl)
sock.close()
2.超时设置
说明:有的网站能很快的被访问,有的访问很慢,因此,通过超时设置,合理分配时间,能够增加我们爬取网页信息的效率。
eg:
import urllib.request,re
#语法:超时设置就是在urlopen()方法中多加一个timeout参数,所接的数字是几秒响应
sock = urllib.request.urlopen("https://www.baidu.com/", timeout=0.1)
#通常超时设置与异常处理一起用
for i in range(1, 100):
try:
data = urllib.request.urlopen("https://www.baidu.com/", timeout=0.1).read().decode("utf-8")
print(len(data))
except Exception as err:
print("网页响应超时!")
3.自动模拟http请求之get方法和post方法
urllib.request.urlopen()的urlopen默认是以get的请求方式,如果要以post发送请求,需要用到urllib.request.Request()中设置meta参数.
(1) get方法自动请求方式实现自动爬取网页信息
说明:如何爬取搜索引擎中多页信息。
首先,我们要对爬取的网页的网址进行分析,下面拿360搜索引擎来做试验:
①用360搜索引擎搜索python

②切换页码,观察每页网址的共同点

③我将前三页的网址放在了一起,容易观察到红色方框内是相同的,其中q=python中的python就是我们搜索的内容,称为关键字,而pn=1中的1代表的是第几页。

④知道了pn=1的含义,那么我们可以更改pn=的值,来切换页面,从而访问前10页网页信息。这里我们要爬取的信息是每页下方的相关搜索内容。

⑤在要爬取的网页中点击鼠标右键,点击“查看网页源代码”,然后按ctrl + f出来搜索款,搜索你要获取的内容。
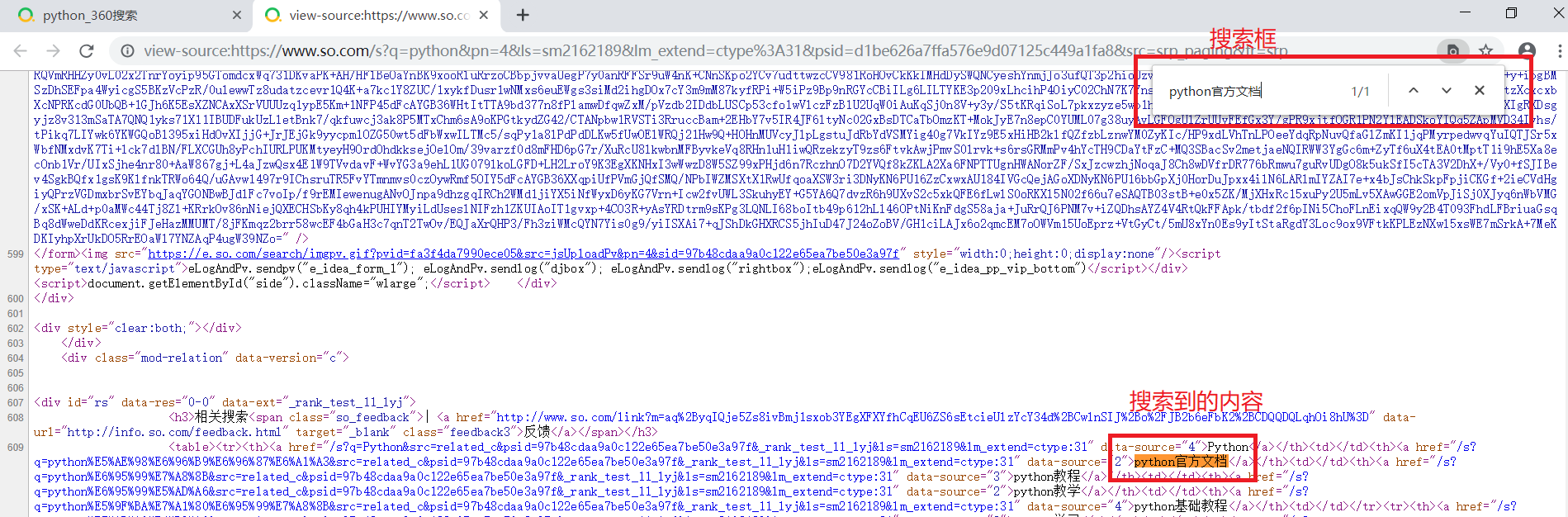
⑥多搜几个,发现规律,都是这个模式data-source="2">python官方文档</a>,只是数字为2或3或4。因此,我们的正则表达式可以为为data-source="[234]">(.*?)</a>
⑦编写代码,代码如下:
#简单爬虫编写,自动爬取网页信息
import urllib.request,re
keywd = "python"
#如果关键字是汉字,则需要对汉字进行转码,因为浏览器不能识别汉字
keywd = urllib.request.quote(keywd) #对关键字进行编码,若不是汉字则可以省略这一步
for i in range(1, 11):
url = "https://www.so.com/s?q=" + keywd + "&pn=" + str(i)
data = urllib.request.urlopen(url).read().decode("utf-8")
pat = 'data-source="[234]">(.*?)</a>'
res = re.compile(pat).findall(data)
for x in res:
print(x)
#结果太长,这里我给出小部分答案:
Python
python官方文档
python教学
python学习
python官网
python发音
Python官网
python是什么
python下载
python例子练手
python3
python能做什么
Python
(2) post方法自动请求方式实现自动爬取网页信息
说明:有的网页是需要用户填写并提交一些信息后才显示出来的,这种情况,我们用post方法来进行自动爬取网页信息。
这里有一个网址是提供post请求的练习的。我是网址
对于这种网页,我们看其源代码的时候,要着重看其name属性,比如:

可以看见name所对应的值就是所提交的post请求的关键,所以,我们可以通过代码模拟出post请求,从而获得信息。
代码如下:
import urllib.request
import urllib.parse #要导入该模块
post_url = 'http://www.iqianyue.com/mypost'
post_data = urllib.parse.urlencode({'name':'asdasd', 'pass':'1123'}).encode("utf-8")
url = urllib.request.Request(post_url, post_data, meta='post')
data = urllib.request.urlopen(url).read().decode('utf-8')
print(data)
#结果:
<html>
<head>
<title>Post Test Page</title>
</head>
<body>
<form action="" method="post">
name:<input name="name" type="text" /><br>
passwd:<input name="pass" type="text" /><br>
<input name="" type="submit" value="submit" />
<br />
you input name is:asdasd<br>you input passwd is:1123</body>
</html>
总结:
get方法就是在爬取信息之前,用关键字和页码数对网址进行处理,再进行信息爬取post方法是在爬取信息之前,创建dict,再用dict模拟请求,从而得到真实网址,再进行信息爬取
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/84814.html

