
Linux操作系统——Shell编程 正则表达式
目录
正则表达式入门
正则表达式使用单个字符串来描述、匹配一系列符合某个语法规则的字符串。在很多文本编辑器里,正则表达式通常被用来检索、替换那些符合某个模式的文本。在 Linux 中,grep, sed,awk 等文本处理工具都支持通过正则表达式进行模式匹配。
1.1 常规匹配
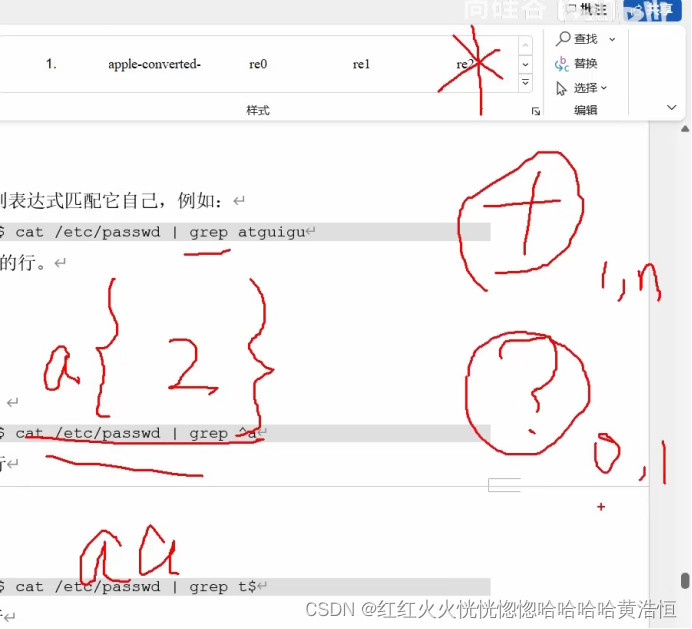
一串不包含特殊字符的正则表达式匹配它自己,例如:
[atguigu@hadoop101 shells]$ cat /etc/passwd | grep atguigu
就会匹配所有包含 atguigu 的行。

1.2 常用特殊字符
1)特殊字符:^
^ 匹配一行的开头,例如:
[atguigu@hadoop101 shells]$ cat /etc/passwd | grep ^a
会匹配出所有以 a 开头的行

2)特殊字符:$
$ 匹配一行的结束,例如
[atguigu@hadoop101 shells]$ cat /etc/passwd | grep t$
会匹配出所有以 t 结尾的行

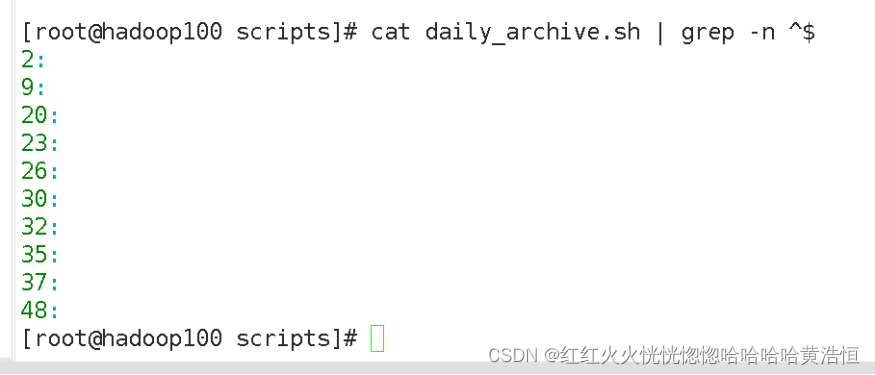
思考:^$ 匹配什么?

匹配的是空行

加一个“-n”参数显示当前的行号
3)特殊字符:.
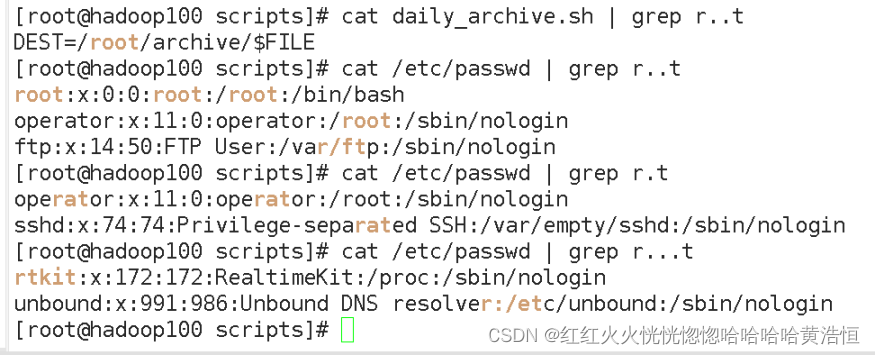
. 匹配一个任意的字符,例如
[atguigu@hadoop101 shells]$ cat /etc/passwd | grep r..t
会匹配包含 rabt,rbbt,rxdt,root 等的所有行
4)特殊字符:*
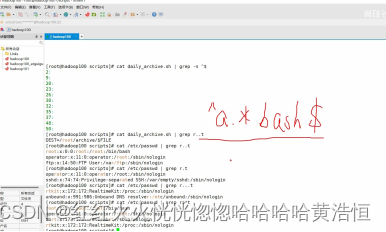
* 不单独使用,他和上一个字符连用,表示匹配上一个字符 0 次或多次,例如
[atguigu@hadoop101 shells]$ cat /etc/passwd | grep ro*t
会匹配 rt, rot, root, rooot, roooot 等所有行

思考:.* 匹配什么?
任意一个字符 出现 任意次=>任意的字符串
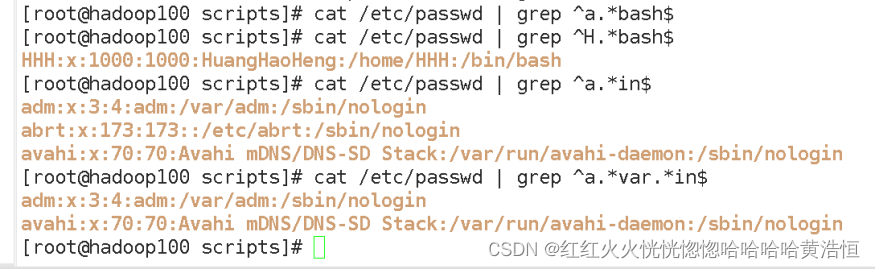
5)字符区间(中括号):[ ]
[ ] 表示匹配某个范围内的一个字符,例如
[6,8] 匹配 6 或者 8
[0-9] 匹配一个 0-9 的数字
[0-9]* 匹配任意长度的数字字符串
[a-z] 匹配一个 a-z 之间的字符
[a-z]* 匹配任意长度的字母字符串
[a-c, e-f]-匹配 a-c 或者 e-f 之间的任意字符
[atguigu@hadoop101 shells]$ cat /etc/passwd | grep r[a,b,c]*t
会匹配 rt,rat, rbt, rabt, rbact,rabccbaaacbt 等等所有行
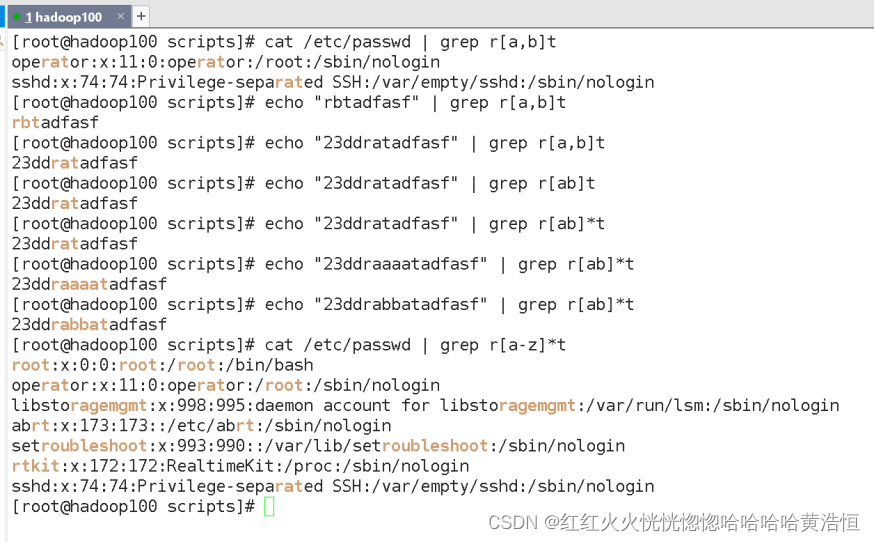
6)特殊字符:\
\ 表示转义,并不会单独使用。由于所有特殊字符都有其特定匹配模式,当我们想匹配某一特殊字符本身时(例如,我想找出所有包含 ‘$’ 的行),就会碰到困难。此时我们就要将转义字符和特殊字符连用,来表示特殊字符本身,例如
[atguigu@hadoop101 shells]$ cat /etc/passwd | grep ‘a\$b’
就会匹配所有包含 a$b 的行。注意需要使用单引号将表达式引起来。

结果输出了所有内容 $代表结尾

必须是单引号将’$’符号引起来

正则表达式拓展:
a{2} 匹配两次a,即aa
* 匹配0次1次或多次
+ 匹配一次或多次
? 匹配0次或1次
1.3 小应用案例
通过正则表达式匹配一串手机号

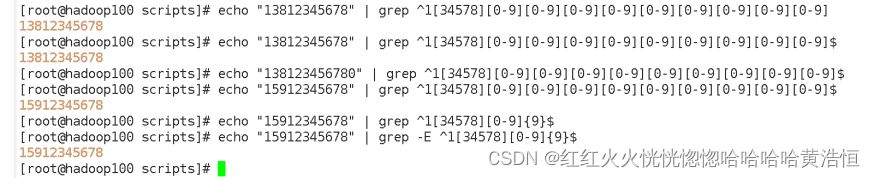
-E 支持可扩展的正则表达式
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/85622.html

