
解析xml文件是必须要掌握的,有以下几种方式。无论什么时候还是建议读者多看官方文档,官方文档才是王道。xml.dom — The Document Object Model API — Python 3.11.1 documentation
目录
2. 使用ElementTree(元素树): xml.etree.ElementTree
如果想要解析下面xml文件中红框框出来的部分,应该怎么解决?

1. 使用xml.dom:xml.dom.minidom
DOM解析器在解析XML 文档时,通过读取整个文档,把文档中所有元素保存成一个树结构,之后利用DOM 提供的不同的函数来读取或修改xml的内容和结构。python中用xml.dom.minidom来解析xml文件,minidom比完整的DOM简单,而且要小很多。代码和解释如下:
import xml.dom.minidom
if __name__ == '__main__':
'''
getElementsByTagName("contour")root下所有tagName为contour的结果, 为NodeList。
获取NodeList里面的元素使用: 该元素是element对象,所以使用item(idx)获取元素。
获取element对象下的值:使用.childNodes[0], 返回Text对象,使用.data获取text值
具体的element的相关属性可参考链接:https://docs.python.org/3/library/xml.dom.html#dom-element-objects
'''
xmlPath = './P2ILF22_patient1_1.xml'
dom = xml.dom.minidom.parse(xmlPath)
root = dom.documentElement # 返回以contours为根的解析结果
contour = root.getElementsByTagName("contour").item(0)
imagePoints = contour.getElementsByTagName("imagePoints").item(0)
ele_numOfPoints = imagePoints.getElementsByTagName("numOfPoints").item(0)
ele_x = imagePoints.getElementsByTagName("x").item(0)
ele_y = imagePoints.getElementsByTagName("y").item(0)
val_numOfPoints = ele_numOfPoints.childNodes[0].data
val_x = ele_x.childNodes[0].data
val_y = ele_y.childNodes[0].dataDom下objects的相关属性和方法可参考官方链接下的这个表格:xml.dom — The Document Object Model API — Python 3.11.1 documentation
2. 使用ElementTree(元素树): xml.etree.ElementTree
import xml.etree.ElementTree as et
if __name__ == '__main__':
xmlPath = 'xxx.xml' # xml文件路径
tree = et.parse(xmlPath) # 解析文件
root = tree.getroot() # 获取到文件数的根
Ridge_numOfPoints = root[1][1][0].text #其中[1][1][0]的具体位置看下图
Ridge_numOfPoints_x = root[1][1][1].text
Ridge_numOfPoints_y = root[1][1][2].text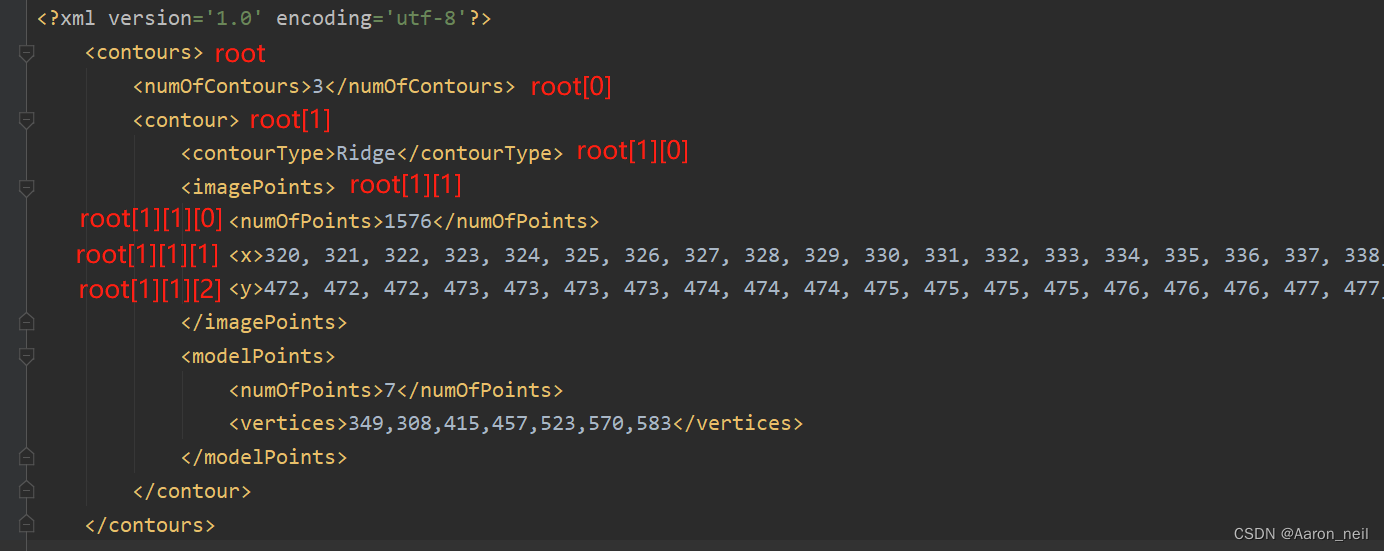
目前该方法在3.3版本后被弃用,如下官网截图:

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/87443.html

