
ConcurrentHashMap
一. 概述
引入:【多个线程访问一个Map时】,使用concurrentHashMap,以保证线程安全;
1.1 回顾HashMap
结构:数组+链表/红黑树;
扩容:初始容量16,到达负载因子 0.75(3/4)后数组开始扩容,扩容为2倍;
扩容以后下标会变化,链表长度减半(因为下标是hashcode和数组长度-1进行的与运算);
七上八下:
JDK7:头插法,【多线程下】,【扩容时】会将原先的链表迁移至新的链表数组中,可能会出现循环链表)—并发死链
JDK8:尾插法,【多线程下】,没有循环链表问题,但多线程下可能会丢数据;
1.2 ConcurrentHashMap 的结构
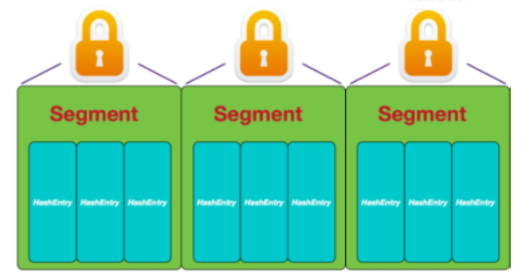
JDK1.7 : (分段锁)
底层数据结构:Segments数组+HashEntry数组+链表,采用分段锁保证安全性;
即整个ConcurrentHashMap 分成了多个Segments数组,每个Segment又存储多个HashEntry,每个HashEntry都是链表;
Segment继承了ReentrantLock锁,相当于把所有数据分成了一个一个的Segment分段,当线程访问一个段时会加锁,但是其他段不受影响,实现多线程并发;
缺点:
在jdk1.8之前,多线程操作同一个Segment不能并发;

JDK1.8 :
底层数据结构:和HashMap一致了,数组+链表 / 红黑树 +CAS+ Synchronized
1.3 重要属性、内部类

volatile sizeCtl :用于扩容,默认值=0, 当第一次数组初始化时,sizeCtl变成 -1 ,当初始化或扩容完成后,sizeCtl就是下次要扩容的阈值大小,即容量 x 0.75(3/4)
volatile Node :链表节点;
volatile table : Node数组,和HashMap一致;
ForwardingNode :【扩容时】搬迁完毕,用ForwardingNode 标记旧的【数组的】头节点使节点哈希码为 -1 !
其他线程看见头节点后就知道这个下标已经处理过了,如果其他线程用了get()方法,遇到头节点就知道去新的table[ ] 去寻找元素,而不是在旧的table[ ]数组中;
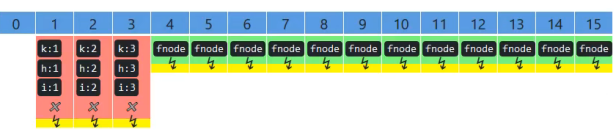
TreeBin:TreeBin是红黑树的根节点, TreeNode是红黑树中的其他节点;
当链表过长,时间复杂度会变成O(n) ,当链表超过8,就转变成红黑树;(转化之前先判断数组长度是否大于64,因为扩容也能使得链表长度减半,当数组长度>64 ,则将链表转换成红黑树)
红黑树还有个作用:一定程度上防止DOS攻击,攻击者会加入大量hashcode相同的对象以降低性能下降;
二. 源码解析
注意:
- 普通的HashMap允许null为空,但是HashTable和ConcurrentHashMap是线程安全的,他的key和value都不可以为null;
- spread() 保证哈希码是正整数,负数有特殊用途(扩容中 or 红黑树);
2.1 get() 方法
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
// spread 保证哈希码为正整数
int h = spread(key.hashCode());
if ((tab = table) != null && (n = tab.length) > 0 &&
// 获取下标
(e = tabAt(tab, (n - 1) & h)) != null) {
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
/ 如果哈希码为负数!即在扩容中或者红黑树
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
// 遍历当前下标对应链表
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
get()没有加锁!而hashTable的get是加锁的,没锁才效率高;
-
indexfor:当table数组不为空,就将正整数的hashCode值h 和(数组长度-1) 相与,得到数组的下标值,得到该处的头节点 e,
然后比较首位节点e的key、HashCode()和 要查找的key、HashCode() 是否一致,如果是直接返回首位节点的value; -
判断:如果头节点的哈希码为负,说明是在扩容中,或者是红黑树:
①可能是已经被forwardingNode标记过(-1),节点在扩容时已经被迁移到新的【table数组】了),就会调用节点的find()方法去新的数组去找key;
②可能是TreeBin即红黑树的头节点(-2);调用TreeBin的find()方法去【红黑树中】去找,找到就返回Node否则返回null; -
遍历链表:寻找的既不是首位节点,哈希码也不是负数,则循环遍历链表中寻找,如果key和哈希码与要查找的相同,则返回value,知道遍历到底,还没找到就返回null;
2.2 put() 方法
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
// spread 保证哈希码为正整数
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) {
Node<K,V> f; int n, i, fh; K fk; V fv;
// table数组不存在或length为0,则用CAS机制初始化创建table
if (tab == null || (n = tab.length) == 0)
tab = initTable();
// table不为0,头节点为null时,使用CAS机制new Node创建新节点;
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value)))
break; // no lock when adding to empty bin
}
// 帮助扩容:头节点不为null,并且哈希码为-1(MOVED),即正在扩容
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else if (onlyIfAbsent // check first node without acquiring lock
&& fh == hash
&& ((fk = f.key) == key || (fk != null && key.equals(fk)))
&& (fv = f.val) != null)
return fv;
// 到此之前,都未加锁!
else {
V oldVal = null;
// 锁住头节点
synchronized (f) {
// 判断头节点是否被移动过
if (tabAt(tab, i) == f) {
// 判断头节点哈希码是否大于0(普通节点)
if (fh >= 0) {
binCount = 1;
// 哈希码大于0,则遍历链表
for (Node<K,V> e = f;; ++binCount) {
K ek;
// 覆盖
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
// 添加到末尾
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key, value);
break;
}
}
}
// 哈希码小于0,红黑树
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
else if (f instanceof ReservationNode)
throw new IllegalStateException("Recursive update");
}
// 释放头节点的锁
}
// 链表长度达到8则转换为红黑树
if (binCount != 0) {
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
// 增加size计数
addCount(1L, binCount);
return null;
}
-
是否为空:“先判断 table 哈希表是否为空,或者长度是否为0,
如果是,就调用initTable()方法,使用CAS机制来创建哈希表,保障不会多个线程重复创建哈希表; -
indexfor:如果table 哈希表不为空, indexfor 使用key的哈希码和(数组长度-1)相与得到table数组的下标然后得到头节点 f ;
如果头节点 f 为null,就使用
CAS机制,new Node创建新阶段放在头节点位置;即如果有其他线程在头节点创建了,就继续尝试下一步; -
帮忙扩容:判断当前 f 的哈希码是否为 -1(被forwardingNode标记的),如果是则表名其他线程正在对哈希表扩容,则调用
helpTransfer()去锁住当前链表(扩容的时候都是以链表为单位来扩容),来帮助保证扩容时的线程安全;到此之前,都没有加锁!
-
遍历链表:说明是普通节点,对 头节点 使用
Synchronized加锁,判断头节点哈希码是否大于0,如果是,则遍历链表,找到key和哈希码相同的元素就覆盖,如果没找到就new Node创建新节点 添加到链表末尾;
-
如果头节点哈希码小于0,且是红黑树(-2),那么将头节点转换成红黑树,往红黑树中去添加添加键值对;
-
过程中,同时会判断,如果链表长度达到8,则尝试转换为红黑树;(先扩容,数组容量达到64再转换)
2.3 transfer() 方法

1.建立2倍新数组;
2.循环遍历,以链表为单位进行移动:
- 如果链表头节点是
null,说明处理完了,将头节点替换为ForwardingNode (哈希值-1); - 如果已经头节点的哈希值已经是-1,即被ForwardingNode标记了,就处理下一个链表;
- 如果头节点是有元素的,就把头节点用Synchronized锁住:
①节点哈希值>=0就拷贝,
②如果节点小于0 (-2) 即红黑树,就走树节点的搬迁;
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/89166.html

