
一.概述
并查集是一种树型的数据结构 ,并查集可以高效地进行如下
功能:
①查询元素p和元素q是否属于同一组 (即看两个元素所在的树是不是同一棵树,即看树的根节点是否相同)
②合并元素p和元素q所在的组(本质是合并两棵树,让一棵树的根节点被另一棵树的根节点所指向)
并查集的结构
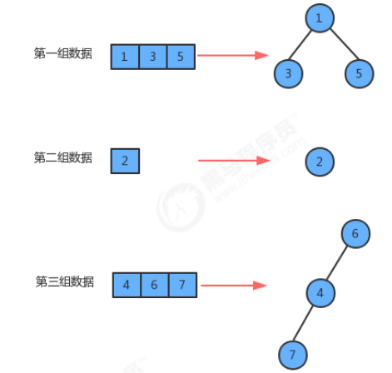
并查集也是一种树型结构,但这棵树跟之前讲的二叉树、红黑树、B树等都不一样,这种树的要求比较简单:
- 每个元素都唯一的对应一个结点;
- 同一组数据中的多个元素都在同一颗树中;
- 一个组中的数据对应的树和另外一个组中的数据对应的树之间没有任何联系;(不同组所在的树之间无关)
(可视为森林中不同树之间没有关系) - 元素在树中并没有子父级关系的硬性要求;(同一组中的树在一棵树内即可,无层次、顺序)

二. 实现

2.1. uf(int N)构造方法实现
- 初始情况下,每个元素都在各自独立的分组中,所以并查集中的数据默认分为N个组;
- 初始化数组eleAndGroup;
- 把eleAndGroup数组的索引看做是每个结点存储的元素,
把eleAndGroup数组每个索引处的值看做是该结点所在的组的标识,那么初始化情况下,i索引处存储的值就是i
2.2.union(int p,int q)合并方法实现
- 如果p和q已经在同一个分组中,则无需合并
- 如果p和q不在同一个分组,则只需要将p元素所在组的所有的元素的组标识符修改为q元素所在组的标识符即可
- 分组数量-1
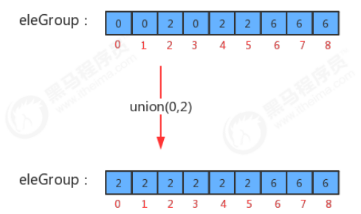
eleAndGroup值(组的标识)为0的都变成值(组的标识)为2
public class uf {
private int[] eleAndGroup;//记录结点元素和该元素所在组的标识
private int count;// 分组个数
public uf(int N) {
//初始情况下,每个元素都在各自独立的分组中,所以,初始情况下 并查集中的数据默认分为N个组
this.count = N;
//初始化数组
eleAndGroup = new int[N];
for (int i = 0; i < eleAndGroup.length; i++) {
eleAndGroup[i] = i; //索引是顶点,值是组的标识,所以每个组标识初始化为i
}
}
public int count() {
return count;
}
public int find(int p) { //元素p所在组的标识
return eleAndGroup[p]; //组的标识即eleAndGroup数组的值
}
public boolean conn(int p, int q) {//判断并查集中元素p和元素q是否在同一分组中
return (find(p) == find(q));
}
public void union(int p, int q) { //合并p所在组 和q所在组 合并
//判断是否已经在同一个组
if (find(p) == find(q)) {
return;
}
int pGroup = find(p);
int qGroup = find(q);
//合并:
for (int i = 0; i < eleAndGroup.length; i++) {
if (eleAndGroup[i] == pGroup) { //筛选出p所在的组
eleAndGroup[i] = qGroup; //使p所在组的标识 变为q所在组的标识
}
}
this.count--;
}
}
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/89350.html

