
一.概述
dfs深度优先搜索有一个特点,那就是在一个连通子图上,每个顶点只会被搜索一次,要将搜索过的顶点进行排序,只需要将搜索的顶点放入到线性序列的数据结构中即可
此处用栈存顶点,栈是后进先出,压栈时是由递归出口依次往回压入栈中,弹栈后顶点为正序排列。
排序过程:
从0出发,遍历0的邻接表: 2、3,搜索到2,遍历2的邻接表:4,搜索到4,遍历4的邻接表:5 ,遍历5的邻接表,没了,dfs递归结束,将5放入栈。
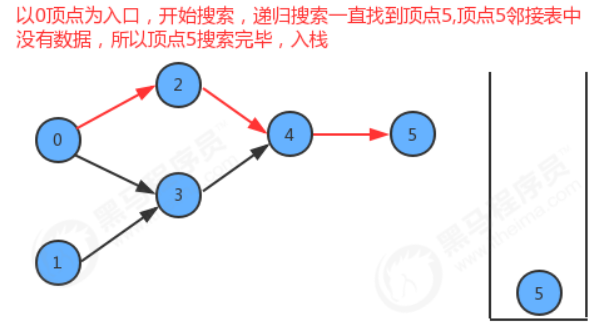
在5顶点处递归结束,回到上一层dfs, v=4,4进栈 ,4没有兄弟节点,递归结束,;
再回到上一层dfs, v=2,2的邻接表没有未被标记的节点(没有兄弟系节点),递归结束,2进栈;
再回到上一层,v=0 ,0的邻接表中有3(即2有兄弟节点3),3的邻接表中都被标记了,递归结束,3进栈;
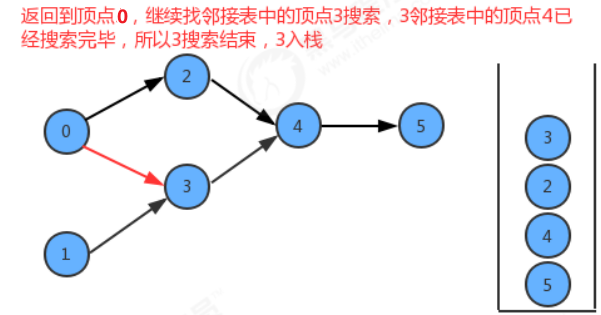
回到最初的v=0, 0进栈。

以0为入口的搜索完毕,再以顶点1进行搜索:
遍历1的邻接表,找到3,marked[3]=true, dfs 结束,顶点1入栈。
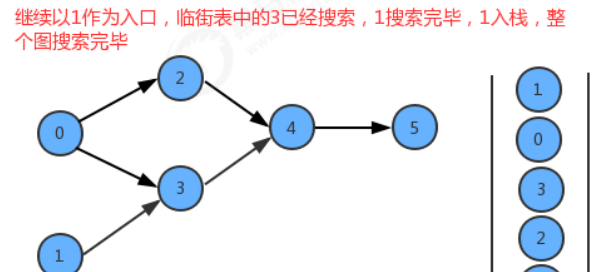
遍历其他顶点作为入口,但都被搜索过了 marked[s]=true,顶点排序结束。
结果: 1-0-3-2-4-5
API:
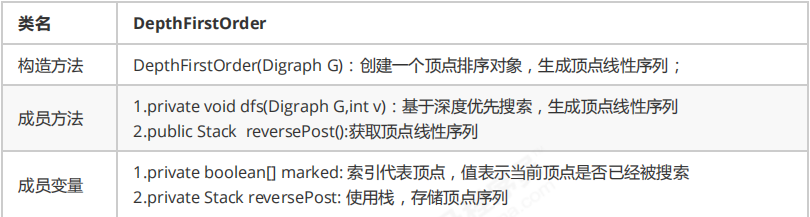
二.实现
public class DingDianPaiXu {
private boolean[] marked;
private Stack<Integer> reversePost;
public DingDianPaiXu(Digraph g) { // 给定一个有向图
this.marked = new boolean[g.V()]; // 图Digraph的V()方法是返回顶点个数
this.reversePost = new Stack<Integer>(); // 初始化栈
//生成的线性序列要包括所有顶点,所以要遍历每一个顶点进行搜索 !
//如果没被搜索过则作为顶点进行搜索
for (int i = 0; i < g.V(); i++) {
if (!marked[i]) { // 若未被标记则调用dfs
dfs(g, i);
}
}
}
public void dfs(Digraph g, int v) { //给定图和入口顶点
marked[v] = true;
//遍历v的邻接表
for (Integer k : g.adj(v)) {
if (!marked[v]) {
dfs(g, k);
}
}
reversePost.push(v);//注意! 顶点搜索完之后,是让当前顶点v入栈!且从最后一个开始逐层往回压栈
}
public Stack reversePost(){
return reversePost;
}
}
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/89354.html

