
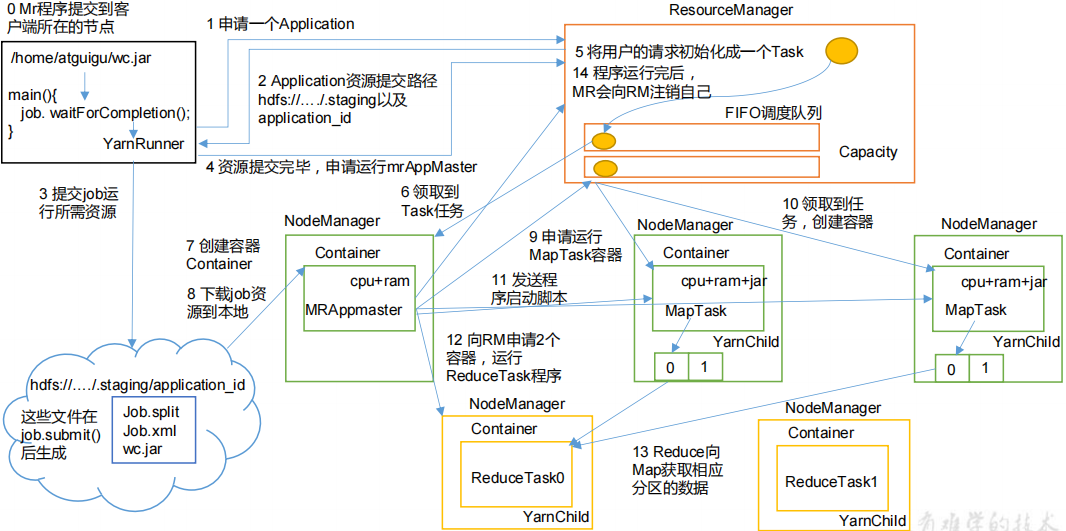
(一)作业提交:
1.MR程序提交到客户端所在的节点上,产生一个YarnRunner ,(如果是本地则产生localRunner)
2.YarnRunner客户端向 ResourceManager 申请运行程序。ResourceManager 会将程序提交的资源路径和job id返回给客户端。
3.客户端将运行程序所需要的资源(配置文件XML、切片信息split、jar包)提交到指定的资源提交路径。
4.客户端提交完资源后,向ResourceManager 申请运行 MRAppMaster(单个job的老大)。
(二) 作业初始化
5.ResourceManager 将客户端的请求初始化成一个Task任务。 将任务放到FIFO任务队列里面
6.ResourceManager 找到一个空闲的NodeManager 领取到 Task 任务,用于运行MRAppMaster。
7.该 NodeManager 创建容器 Container用于运行MRAppmaster,并产生 MRAppmaster。(任何任务都是在容器里面运行)
8.Container 从 HDFS 上的集群资源的路径上拷贝资源(split切片信息)到本地。
(三) 任务分配
9.MRAppmaster 向 ResourceManager 申请运行多个MapTask 资源。 (切片个数对应MapTask个数)
10.ResourceManager 将运行 MapTask 任务分配给另外两个 NodeManager,另两个 NodeManager 分别领取任务并创建容器。
(这两个containier也可能在一个NodeManager上)
(四)任务运行
11.MRAppmaster 向两个接收到任务的 NodeManager 发送程序启动MapTask脚本,这两个 NodeManager 分别启动 MapTask,MapTask工作完后,对数据按照分区持久化到磁盘,等待ReduceTask来拉取。 (MapTask和ReduceTesk对应的进程都是Yarnchild)
12.MrAppMaster 等待所有 MapTask 运行完毕后,又向ResourceManager 申请容器,在容器中运行 ReduceTask。 (其对应的进程为Yarnchild)
13.ReduceTask 向 MapTask 获取相应分区的数据。
14.程序运行完毕后,MRAppmaster 会向 ResourceManager 申请注销自己。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/89360.html

