
一.DataNode工作流程
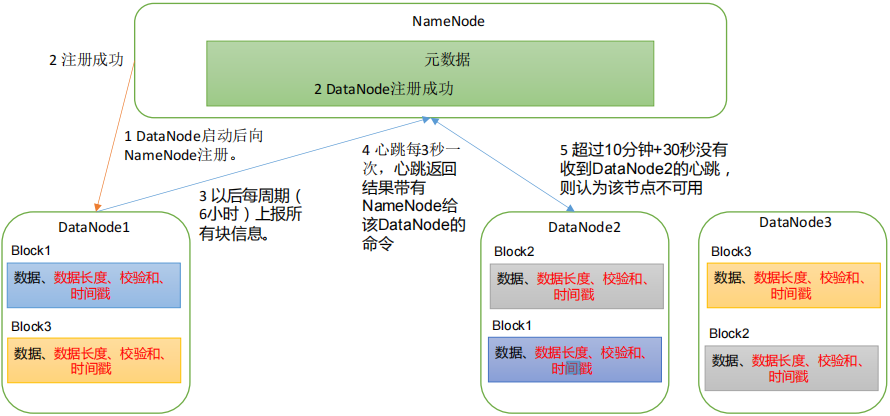
(1)注册 register:当DataNode启动的时候,DataNode将自身信息告诉NameNode。作用是使得这个DataNode注册成为HDFS集群中的成员。
注:一个数据块在 DataNode 上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据,(包括数据块的长度,块数据的校验和,以及时间戳)

上面是DataNode 实际存储的文件内容 ,XXX.meta存储的是元数据
(2)汇报 blockreport: DataNode向 NameNode注册通过后,会周期性(6 小时)的向 nn汇报所有的块信息(块是否完好)以维持NameNode和数据块之间的映射关系。 这一步完成后,DtaNode才正式启动完成。
DN 向 NN 汇报当前解读信息的时间间隔,默认 6 小时;
 扫描自己节点块信息列表的时间(自查时间)也是 6 小时一次,查完就向nn报道
扫描自己节点块信息列表的时间(自查时间)也是 6 小时一次,查完就向nn报道
 //如果服务器质量较差,可以缩短自查周期
//如果服务器质量较差,可以缩短自查周期
(3)心跳机制 heartbeat: 心跳默认 3 秒一次
作用:
①告诉NameNode 块的信息
②NameNode在心跳响应中将命令给到Datanode
当复制块数据到另一台机器,或删除某个数据块。如果超过 **10 分钟+30秒(10次心跳)**没有收到某个 DataNode的心跳,则认为该节点不可用。则以后nn就不会允许客户端往该节点读、写数据。
总结: DataNode与NabeNode之间的交互非常的简单,大部分都是DataNode到NameNode的心跳,考虑到一个规模的HDFS集群,一个名字节点会管理上千个DataNode,所以这样的设计也非常自然了
二.DataNode掉线时限参数设置
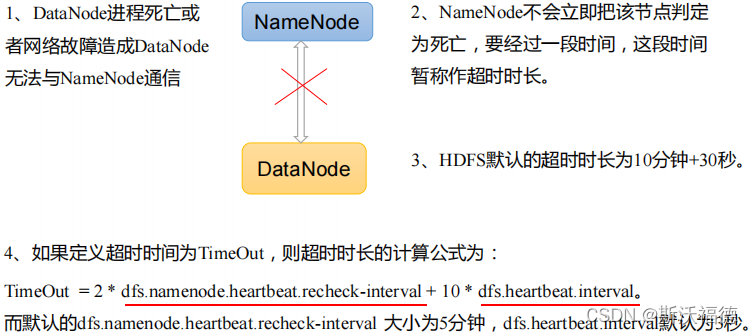
超时时间为TimeOut,有公式:
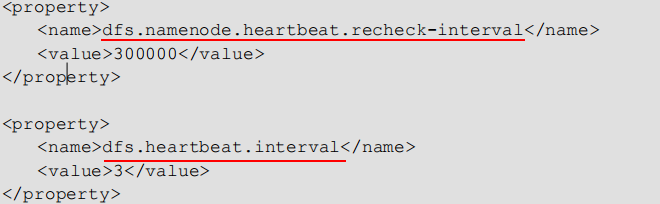
TimeOut = dfs.namenode.heartbeat.recheck.interval * 2 + dfs.heartbeat.interval * 10
(2x5min+10x3s=10min+30s)
dfs.namenode.heartbeat.recheck.interval单位为毫秒,默认5min=30000ms
dfs.heartbeat.interval(心跳周期)单位为秒,默认3s
若要再次尝试启动NameNode,命令:hdfs –daemon start datanode
参考:https://www.cnblogs.com/tesla-turing/p/11488004.html
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/89381.html

