
基于fluentd实现读取nginx日志输出到kafka
一、浅谈fluentd
1.1、什么是Fluentd?
Fluentd是一个用于统一日志层的开源数据收集器。Fluentd允许您统一数据收集和使用,以便更好地使用和理解数据。Fluentd是云端原生计算基金会(CNCF)的成员项目之一,遵循Apache 2 License协议。
Treasure Data, Inc 对该产品提供支持和维护。fluent-bit 是一个用 C 写成的插件式、轻量级、多平台开源日志收集工具。它允许从不同的源收集数据并发送到多个目的地。这个两个日志收集组件完全兼容docker 和kubernetes 生态环境。随着 Kubernetes 的强势崛起,业务分布在多个计算节点,日志收集凸显重要,本文主要讲述本人在使用 fluentd 和 fluent-bit 中碰到的问题,以及解决方法。
| Fluentd | td-agent | |
|---|---|---|
| 支持 | 社区驱动 | Treasure Data提供支持和维护 |
| 安装 | Ruby gems | rpm / deb / dmg 软件包 |
| 配置 | 自己配置 | 预配置了几个建议设置 |
| 其它组件 | $ fluent-gem install fluent-plugin-xx | $ /usr/sbin/td-agent-gem install fluent-plugin-xx |
| /etc/init.d/ 脚本 | 无 | 有 |
| 内存分配方式 | 系统默认 | 优化(jemalloc) |
1.2、应该选择 fluentd 还是 td-agent?
td-agent 是基于 fluentd 核心功能开发,td-agent 优先考虑稳定性而不是新功能。如果您希望自己控制Fluentd功能和更新,建议使用 Fluentd gem。如果您是第一次使用 Fluentd 或在生产环境集群环境中使用它,建议使用td-agent。每2或3个月发布一次新版本的td-agent。
二、安装td-agent服务器
博主使用的是centos7虚拟机,所以按照官网的安装手册是这样的,别的系统可参考==>fluentd安装
2.1、安装td-agent
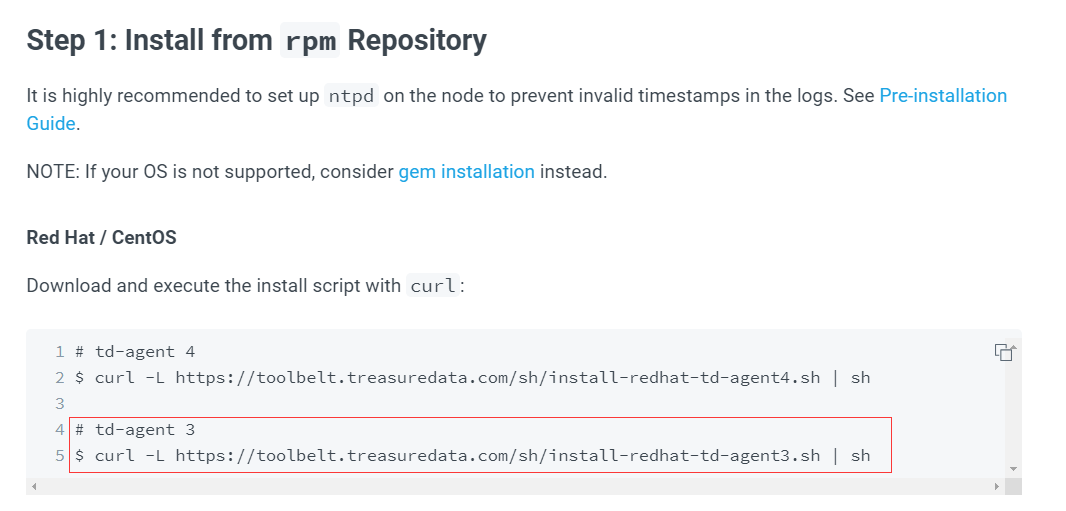
curl -L https://toolbelt.treasuredata.com/sh/install-redhat-td-agent3.sh | sh
2.2、启动td-agent服务
systemctl start td-agent.service
systemctl status td-agent.service

2.3、使用http post请求测试
td-agent的配置文件是/etc/td-agent/td-agent.conf
td-agent的日志文件是/var/log/td-agent/td-agent.log
curl -X POST -d 'json={"json":"message"}' http://localhost:8888/debug.test
tail -n 1 /var/log/td-agent/td-agent.log

三、怎么去使用这个td-agent
3.1、了解td-agent的内部结构
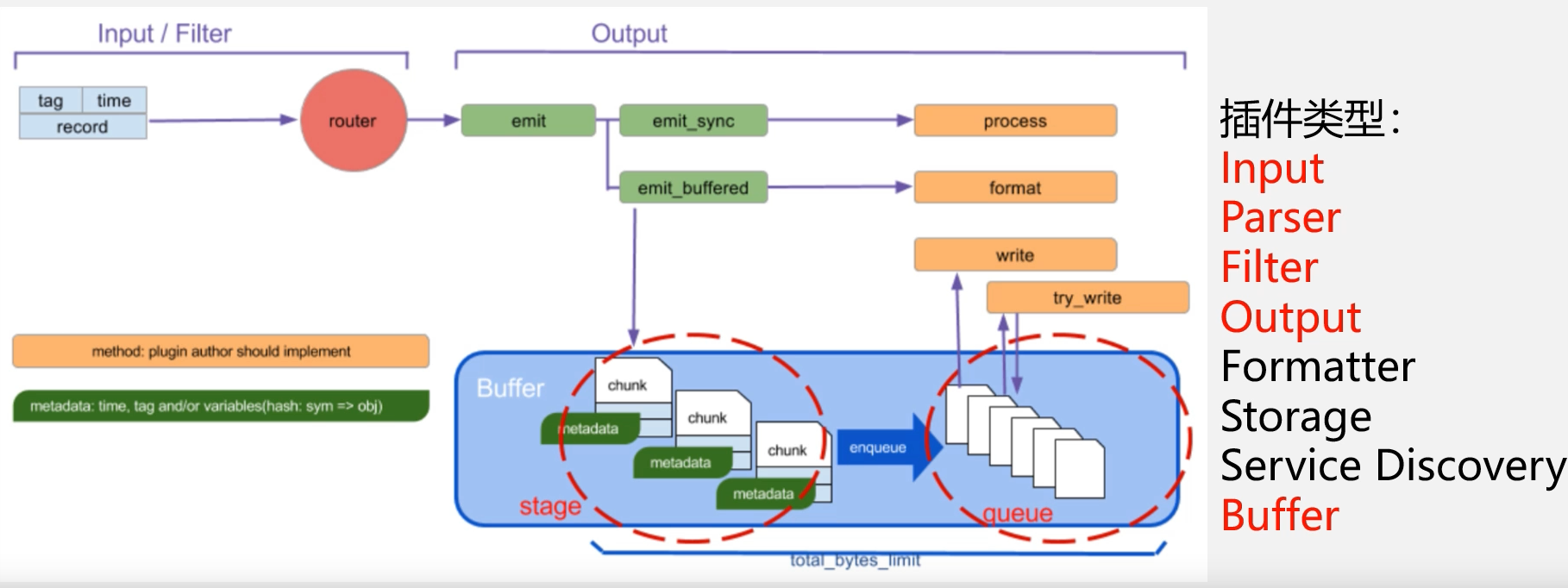
1)Input Plugin
自带插件:tail、forward、udp、tcp、http等等
需安装插件:sql、dstat等等
<source>
@type tail
path /var/log/httpd-access.log
pos_file /var/log/td-agent/httpd-access.log.pos
tag apache.access
<parse>
@type apache2
</parse>
</source>
2)Parse Plugin
自带插件:regexp、apache2、nginx、csv、json、multiline等等
<parse>
@type regexp
expression /^\[(?<logtime>[^\]]*)\] (?<name>[^ ]*) (?<title>[^ ]*) (?<id>\d*)$/
time_key logtime
time_format %Y-%m-%d %H:%M:%S %z
types id:integer
</parse>
3)Filter Plugin
自带插件:record_transformer、grep、parser等等
<filter foo.bar>
@type grep
<regexp>
key message
pattern /cool/
</regexp>
<regexp>
key hostname
pattern /^web\d+\.example\.com$/
</regexp>
<exclude>
key message
pattern /uncool/
</exclude>
</filter>
The value of the message field contains cool.
这个message值中包含cool
The value of the hostname field matches web<INTEGER>.example.com.
这个hostname中匹配这个规则
The value of the message field does NOT contain uncool.
这个message值中不包含uncool
4)Output Plugin
自带插件:file、forward、http、copy、kafka、elasticsearch等等
需要安装的插件:sql、hdfs等等
<match pattern>
@type kafka2
# list of seed brokers
brokers <broker1_host>:<broker1_port>,<broker2_host>:<broker2_port>
use_event_time true
# buffer settings
<buffer topic>
@type file
path /var/log/td-agent/buffer/td
flush_interval 3s
</buffer>
# data type settings
<format>
@type json
</format>
# topic settings
topic_key topic
default_topic messages
# producer settings
required_acks -1
compression_codec gzip
</match>
brokers kafka的服务器地址
buffer 缓存刷新(可以保存到文件,设置刷新时间)
format 格式化
topic 目标topic
default_topic 默认topic
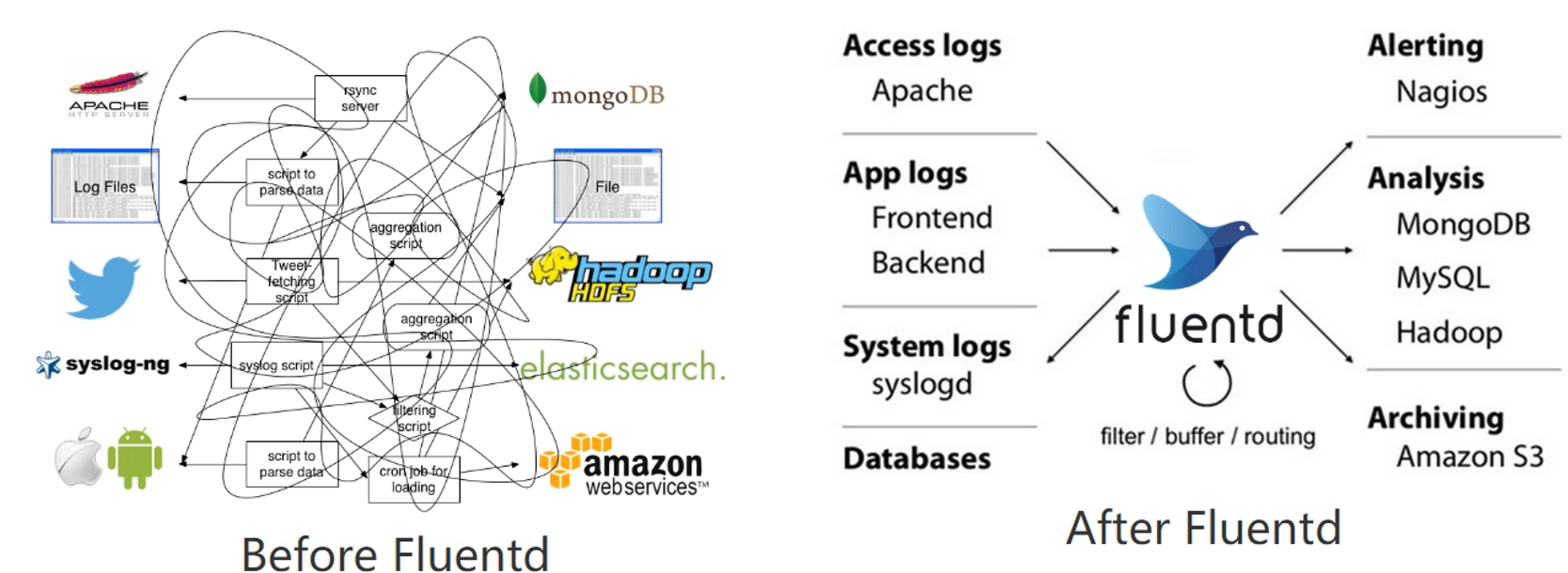
四、Fluentd在实际中的架构以及实际应用
利用Fluentd在各个服务器上抓取日志信息,再推送给Mysql或者ES或者JAVA应用等等进行可视化展示
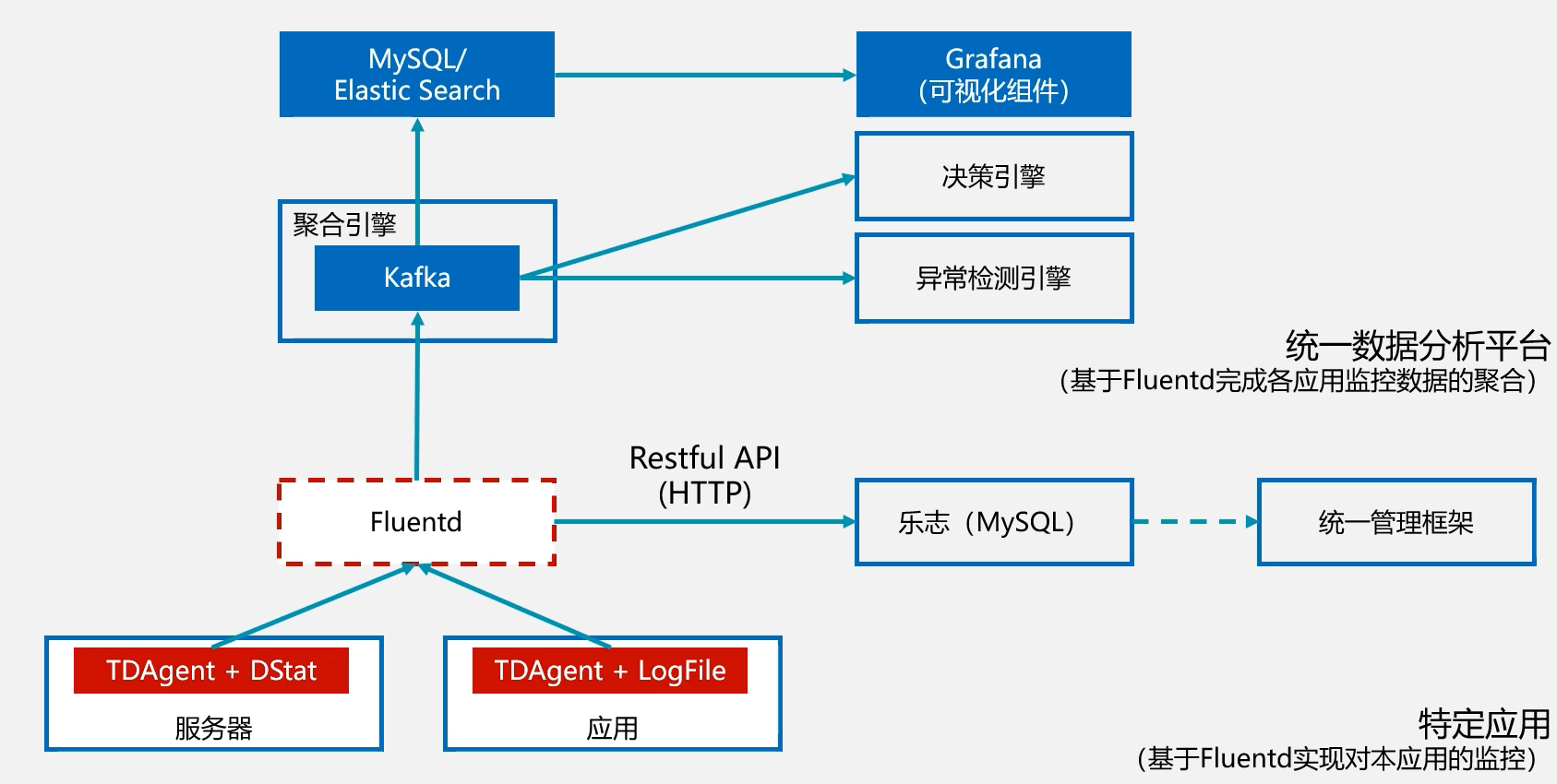
博主实现的是利用Fluentd抓取nginx日志到kafka
配置的td-agent.conf
<source>
@type tail
@id input_tail
path /mydata/nginx/logs/access.log
pos_file /var/log/td-agent/nginx-access.log.pos
<parse>
@type regexp
expression /^(?<remote>[^ ]*) (?<host>[^ ]*) (?<user>[^ ]*) \[(?<time>[^\]]*)\] "(?<method>\S+)(?: +(?<path>[^\"]*?)(?: +\S*)?)?" (?<code>[^ ]*) (?<size>[^ ]*)(?: "(?<referer>[^\"]*)" "(?<agent>[^\"]*)"(?:\s+(?<http_x_forwarded_for>[^ ]+))? "(?<request_time>[^\"]*)" "(?<response_time>[^\"]*)" "(?<request_length>[^\"]*)" "(?<upstream_addr>[^\"]*)")?$/
time_key time
time_format %d/%b/%Y:%H:%M:%S %z
</parse>
tag td.nginx.access
</source>
<filter td.nginx.access>
@type grep
regexp1 path catalog.json
</filter>
<match td.nginx.access>
@type kafka2
brokers 127.0.0.1:9092
use_event_time true
<buffer nginx>
flush_interval 5s
</buffer>
<format>
@type json
</format>
topic_key nginx
default_topic messages
required_acks -1
compression_codec gzip
</match>
根据nginx日志记录的格式抓取

使雍springboot继承kafka监听消息
成功消费kafka中推送的日志信息

最后感谢B站大佬的指导视频 ===> 分布式日志采集工具:fluentd-20200708-王子健
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/90994.html

