
elasticsearch实现中文分词+远程自定义词库nginx
一、中文分词
elasticsearch本身自带的中文分词,就是单纯把中文一个字一个字的分开,根本没有词汇的概念。但是实际应用中,用户都是以词汇为条件,进行查询匹配的,如果能够把文章以词汇为单位切分开,那么与用户的查询条件能够更贴切的匹配上,查询速度也更加快速。
分词器下载网址:https://github.com/medcl/elasticsearch-analysis-ik
下载好的zip包,请解压后放到 /usr/share/elasticsearch/plugins/ik
二、为什么要用远程词库?
过滤一些不能够出现的词语,以及一些流行词语。
实现方式
同将远程词库放在Nginx中当静态资源使用
nginx安装参考https://blog.csdn.net/qq_45887180/article/details/120038664
这样添加的词语不用重启两个服务都就可以直接使用
需要的配置:
修改/usr/share/elasticsearch/plugins/ik/config/中的IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!--用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict"></entry>
<!--用户可以在这里配置自己的扩展停止词字典-->
<entry key="ext_stopwords"></entry>
<!--用户可以在这里配置远程扩展字典 -->
<entry key="remote_ext_dict">http://192.168.67.163/es/fenci.txt</entry>
<!--用户可以在这里配置远程扩展停止词字典-->
<!-- <entry key="remote_ext_stopwords">words_location</entry> -->
</properties>
并且在/mydata/nginx/html/下创建es文件夹,并创建一个fenci.txt,用来存放单词
单词用回车分开,每一行代表一个词。
测试访问nginx的静态资源
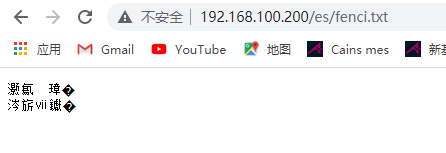
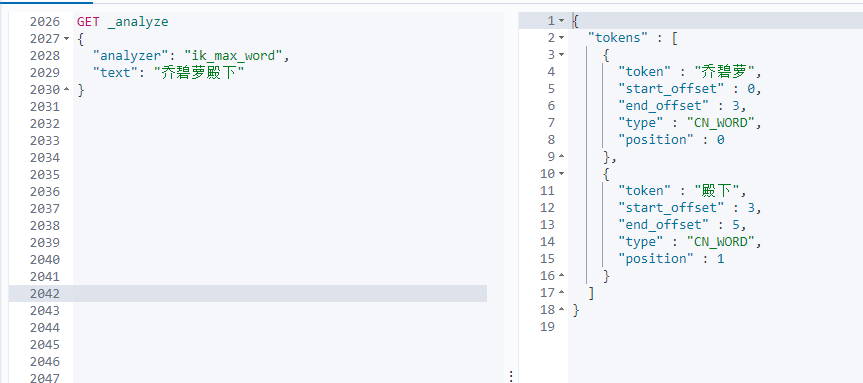
用kibana测试ik自定义分词词库
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/91012.html

