
学习资料:
(55条消息) HBase常用命令(超全超详细)_小财迷,嘻嘻的博客-CSDN博客_hbase put命令
Hbase的安装(详细步骤) – 黄文超 – 博客园 (cnblogs.com)
1、Hbase的安装
1.1 前提条件
1、得安装的有hdfs系统
2、得安装zookeeper集群
1.2 准备安装包
- 下载安装包并上传到node01服务器
- 安装包下载地址:https://archive.apache.org/dist/hbase/2.2.6/hbase-2.2.6-bin.tar.gz
- 将安装包上传到node01服务器/opt/software路径下,并进行解压
[root@hadoop102 software]$ pwd
/opt/software
[root@hadoop102 soft]$ tar -zxvf hbase-2.2.6-bin.tar.gz -C /opt/module/
# ...
- 安装成功
[root@hadoop102 software]$ cd /opt/module/
[root@hadoop102 module]$ ls
hadoop-3.1.3 hbase-2.2.6 jdk1.8.0_212 spark-standalone spark-yarn
[root@hadoop102 module]$ cd hbase-2.2.6/
[root@hadoop102 hbase-2.2.6]$ ls
bin conf LEGAL LICENSE.txt README.txt
CHANGES.md hbase-webapps lib NOTICE.txt RELEASENOTES.md
1.3 修改Hbase配置文件
1.3.1 修改hbase-env.sh文件
- 修改文件
[root@hadoop102 hbase-2.2.6]$ cd /opt/module/hbase-2.2.6/conf
[root@hadoop102 conf]$ vim hbase-env.sh
- 修改如下两项内容,值如下
export JAVA_HOME=/opt/module/jdk1.8.0_212
export HBASE_MANAGES_ZK=false

1.3.2 修改hbase-site.xml文件
- 修改文件
[root@hadoop102 conf]$ vim hbase-site.xml
- 内容如下
<configuration>
<!-- 指定hbase在HDFS上存储的路径 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop102:8020/hbase</value>
</property>
<!-- 指定hbase是否分布式运行 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 指定zookeeper的地址,多个用“,”分割 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop102,hadoop103,hadoop104</value>
</property>
<!--指定hbase管理页面-->
<property>
<name>hbase.master.info.port</name>
<value>60010</value>
</property>
<!-- 在分布式的情况下一定要设置,不然容易出现Hmaster起不来的情况 -->
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
1.3.4 修改regionservers文件
- 修改文件
[root@hadoop102 conf]$ vim regionservers
- 指定HBase集群的从节点;原内容清空,添加如下三行
hadoop102
hadoop103
hadoop104
1.3.5 修改back-masters文件
- 创建back-masters配置文件,里边包含备份HMaster节点的主机名,每个机器独占一行,实现HMaster的高可用
[root@hadoop102 conf]$ vim backup-masters
- 将hadoop103作为备份的HMaster节点,问价内容如下
hadoop103
1.4 分发安装包
将 hadoop102上的HBase安装包,拷贝到其他机器上(xsync 是自己定义的分发脚本)
[root@hadoop102 module]$ xsync hbase-2.2.6
1.5 创建软连接
- ****注意:三台机器****均做如下操作
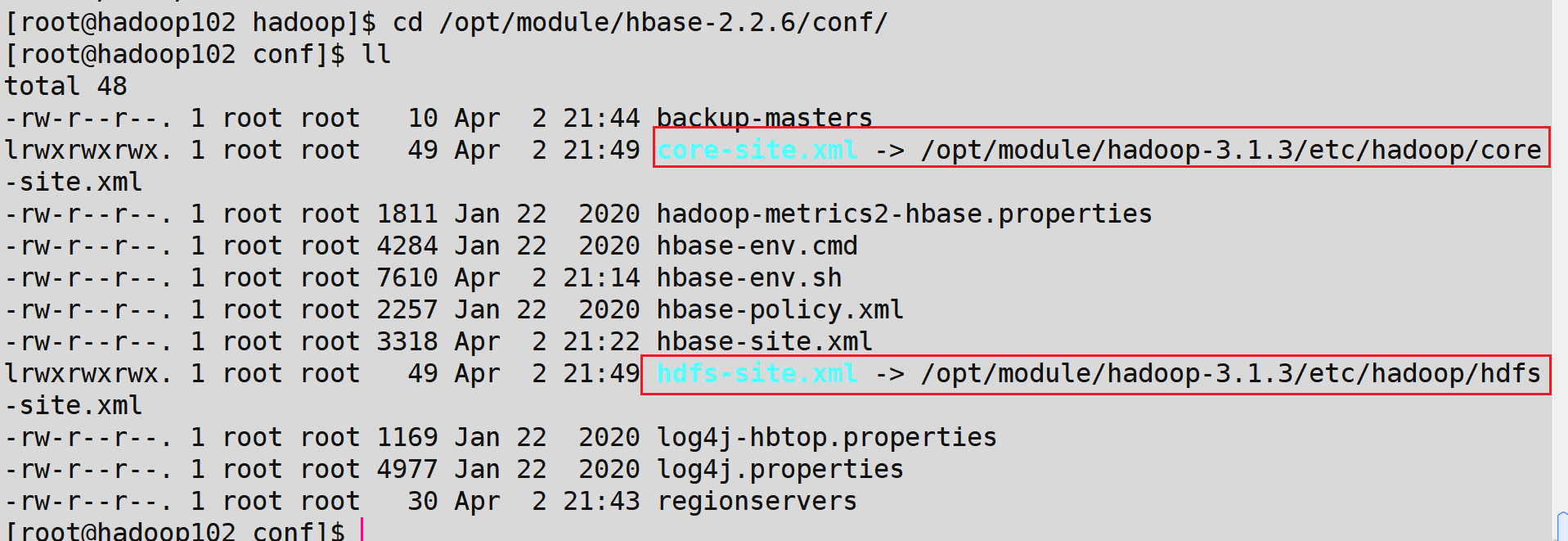
- 因为HBase集群需要读取hadoop的core-site.xml、hdfs-site.xml的配置文件信息,所以我们三台机器都要执行以下命令,在相应的目录创建这两个配置文件的软连接
ln -s /opt/module/hadoop-3.1.3/etc/hadoop/core-site.xml /opt/module/hbase-2.2.6/conf/core-site.xml
ln -s /opt/module/hadoop-3.1.3/etc/hadoop/hdfs-site.xml /opt/module/hbase-2.2.6/conf/hdfs-site.xml
- 执行完后,出现如下效果,以hadoop102为例

1.6 添加HBase环境变量
- 注意:三台机器均执行以下命令,添加环境变量
vim /etc/profile
- 文件末尾添加如下内容
export HBASE_HOME=/opt/module/hbase-2.2.6
export PATH=$PATH:$HBASE_HOME/bin
- 重新编译/etc/profile,让环境变量生效
source /etc/profile
1.7 HBase的启动与停止
- 需要提前启动HDFS及ZooKeeper集群
- 如果没开启hdfs,请在hadoop102运行
start-dfs.sh命令 - 如果没开启zookeeper,请在3个节点分别运行
zkServer.sh start命令
- 如果没开启hdfs,请在hadoop102运行
- 第一台机器hadoop102(HBase主节点)执行以下命令,启动HBase集群
[root@hadoop102 ~]$ start-hbase.sh
-
启动完后,jps查看HBase相关进程
hadoop102、hadoop103上有进程HMaster、HRegionServer
hadoop10上有进程HRegionServer
[root@hadoop102 module]$ jpsall =============== hadoop102 =============== 2065 NameNode 5521 HRegionServer # HRegionServer 6452 Jps 3895 NodeManager 4648 QuorumPeerMain 2204 DataNode 2572 JobHistoryServer 5340 HMaster # HMaster =============== hadoop103 =============== 2352 ResourceManager # HRegionServer 4368 HMaster # HMaster 5250 Jps 3450 QuorumPeerMain 2142 DataNode 2495 NodeManager =============== hadoop104 =============== 3558 SecondaryNameNode 3686 NodeManager 3481 DataNode 4297 QuorumPeerMain 4988 HRegionServer # HRegionServer 5228 Jps
其他
- 警告提示:HBase启动的时候会产生一个警告,这是因为jdk7与jdk8的问题导致的,如果linux服务器安装jdk8就会产生这样的一个警告

-
可以注释掉所有机器的hbase-env.sh当中的
“HBASE_MASTER_OPTS”和“HBASE_REGIONSERVER_OPTS”配置 来解决这个问题。
不过警告不影响我们正常运行,可以不用解决
-
我们也可以执行以下命令,单节点启动相关进程
#HMaster节点上启动HMaster命令
hbase-daemon.sh start master
#启动HRegionServer命令
hbase-daemon.sh start regionserver
1.8 访问WEB页面
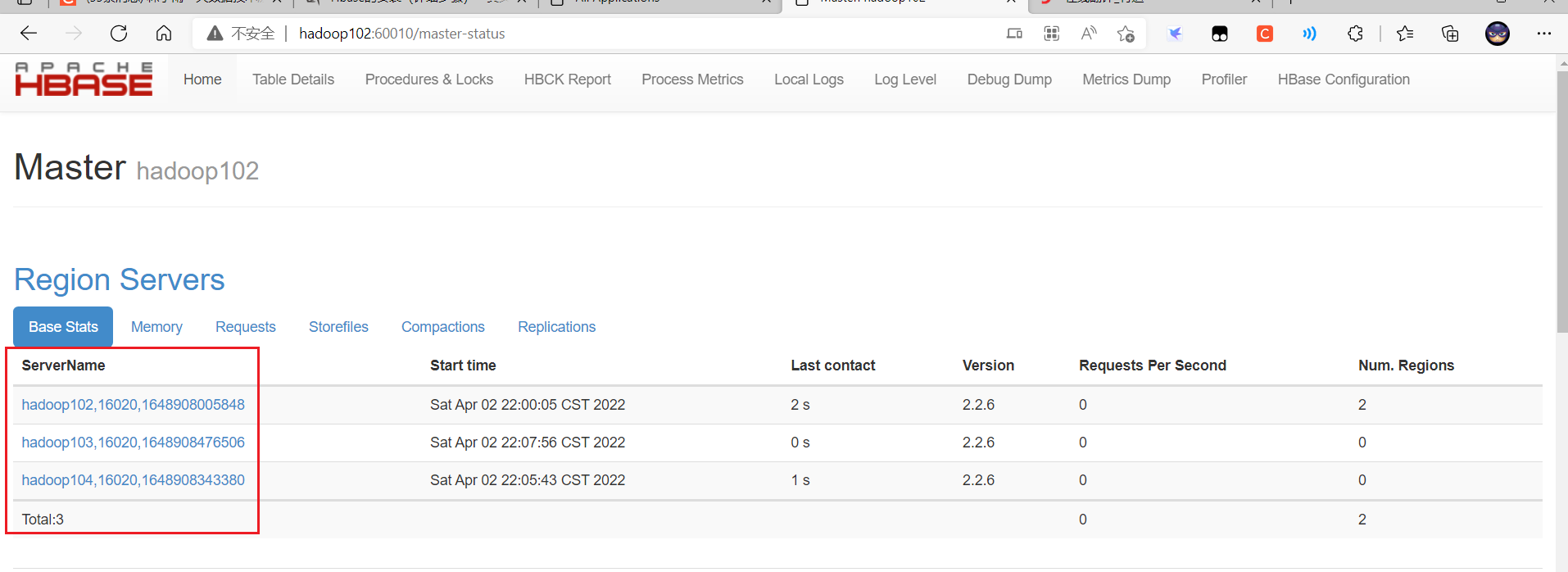
-
浏览器页面访问
http://hadoop102:60010/master-status
1.9 停止HBase集群
停止HBase集群的正确顺序
- hadoop102上运行,关闭hbase集群
$ stop-hbase.sh
- 关闭ZooKeeper集群
- 关闭Hadoop集群
2、Hbase shell入门
2.1 基本命令
1、进入shell环境
$ hbase shell
2、list 列出HBase所有的表的相关信息,例如表名;
hbase(main):001:0> list
TABLE
0 row(s)
Took 0.7845 seconds
=> []
3、其他
#获取帮助
> help
#获取命令的详细信息
> help 'status'
# 查看版本信息
version
2.2 表操作
2.2.1 创建表
- 命令格式1:create ‘表名’,‘列簇名1’,‘列簇名2’…
- 命名格式2:create ‘表名’,{NAME=>‘列簇名1’},{NAME=>‘列簇名2’}…
#创建一张名为Student的表,包含基本信息(baseinfo)、学校信息(schoolinfo)两个列簇
create 'student','haseinfo','schoolinfo'
hbase(main):005:0> create 'student','haseinfo','schoolinfo'
Created table student
Took 2.4659 seconds
=> Hbase::Table - student
- 查看
hbase(main):010:0> list
TABLE
student
1 row(s)
Took 0.0238 seconds
=> ["student"]
2.2.2 删除表
#删除表前需要先禁用表
disable 'student'
#删除表
drop 'student'
2.2.3 修改表名
命令格式:
- snapshot ‘表名’,‘镜像名’
- clone_snapshot ‘镜像名’,‘新表名’
- delect_snapshot ‘镜像名’
snapshot 'student','temp'
clone_snapshot 'temp','stu'
delect_snapshot 'temp'
2.2.4 查看表的基本信息
命令格式:desc ‘表名’
desc 'student'
2.2.5 检查表是否存在
exists 'student'
2.2.6 表的启用和禁用
#禁用表
disable 'student'
#检查表是否被禁用
is_disabled 'student'
#启用表
enable 'student'
#检查表是否被启用
is_enabled 'student'
2.3 增删改
2.3.1 添加列簇
- 命令格式:alter ‘表名’,‘列簇名’
alter 'student','teacherinfo'
hbase(main):014:0> alter 'student','teacherinfo'
Updating all regions with the new schema...
1/1 regions updated.
Done.
Took 2.6110 seconds
2.3.2 删除列簇
- 命令格式:alter ‘表名’,{NAME=>‘列簇名’,METHOD=‘delete’}
alter 'student',{NAME => 'teacherinfo', METHOD => 'delete'}
2.3.3 更改列簇存储版本的限制
默认情况下列族只存储一个版本的数据,如果需要存储多个版本的数据,则需要修改列族的属性。修改后可通过 desc 命令查看。
alter 'student',{NAME=>'baseinfo',VERSIONS=>3}
2.3.4 插入数据
- 命令格式:put ‘表名’,‘行键’,‘列簇名:列名’,‘值’[,时间戳]
命令格式:
put ‘表名’, ‘行键’,‘列簇名:列名’, ‘值’[,时间戳]
put 'student', '1','haseinfo:name','tom'
put 'student', '1','haseinfo:birthday','1990-01-09'
put 'student', '1','haseinfo:age','29'
put 'student', '1','haseinfo:localtion','Boston'
hbase(main):021:0> put 'student', '1','haseinfo:name','tom'
Took 0.0234 seconds
2.3.5 获取指定行、指定行中的列族、列的信息
# 获取指定行中所有列的数据信息
get 'student','1'
# 获取指定行中指定列族下所有列的数据信息
get 'student','1','haseinfo'
# 获取指定行中指定列的数据信息
get 'student','1','haseinfo:name'
hbase(main):027:0> get 'student','1'
COLUMN CELL
haseinfo:name timestamp=1648954173414, value=tom
haseinfo:age timestamp=1648954057153, value=29
haseinfo:birthday timestamp=1648954052884, value=1990-01-09
haseinfo:localtion timestamp=1648954065369, value=Boston
1 row(s)
Took 0.1582 seconds
hbase(main):032:0> get 'student','1','haseinfo:name'
COLUMN CELL
haseinfo:name timestamp=1648954173414, value=tom
1 row(s)
Took 0.0134 seconds
2.3.6 删除指定行、指定行中的列
# 删除指定行
delete 'student','1'
# 删除指定行中指定列的数据
delete 'student','1','haseinfo:name'
2.4 查询
hbase 中访问数据有两种基本的方式:
- 按指定 rowkey 获取数据:get 方法;
- 按指定条件获取数据:scan 方法。
scan 可以设置 begin 和 end 参数来访问一个范围内所有的数据。get 本质上就是 begin 和 end 相等的一种特殊的 scan。
2.4.1 get查询
# 获取指定行中所有列的数据信息
get 'student','1'
# 获取指定行中指定列族下所有列的数据信息
get 'student','1','haseinfo'
# 获取指定行中指定列的数据信息
get 'student','1','haseinfo:name'
2.4.2 scan查询
#查询整表数据
scan 'student'
#查询指定列簇的数据
scan 'student', {COLUMN=>'haseinfo'}
# 查询指定列的数据
scan 'student', {COLUMNS=> 'haseinfo:birthday'}
# 查看指定列两个版本的数据
scan 'student', {COLUMNS=> 'haseinfo:birthday',VERSIONS=>2}
# 查看前3条数据
scan 'student',{LIMIT=>3}
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/92647.html

