
目录
为什么设置id
服务消费者发送请求到服务提供者,在请求体中可以设置一个字段是该请求的id,发送出去之后只需要在一个while循环中去restMap中根据id去找结果即可,因为服务提供者在处理完后会把结果发给客户端,客户端会把这个结果放在这个全局的restMap中,这样就能够实现请求和响应的一一对应。
那么id需要保证它的唯一性,否则可能会有若干请求的响应和请求id是多对一。
采用哪种算法生成id
UUID
UUID是指在一台机器上生成的数字,它保证对在同一时空中的所有机器都是唯一的
UUID由以下几部分的组合:
(1)当前日期和时间,UUID的第一个部分与时间有关,如果你在生成一个UUID之后,过几秒又生成一个UUID,则第一个部分不同,其余相同。
(2)时钟序列。
(3)全局唯一的IEEE机器识别号,如果有网卡,从网卡MAC地址获得,没有网卡以其他方式获得。
通过组成可以看出,首先每台机器的mac地址是不一样的,那么如果出现重复,可能是同一时间下生成的id可能相同,不会存在不同时间内生成重复的数据.
可以使用uuid,需要注意的是 uuid 的生成,因为在一台机器上可能会并发的发送请求,那么此时uuid可能会重复,所以在代理类中,需要这样设置
private static final Object lock = new Object(); // 类变量
// 在生成uuid 时加锁
synchronized (lock){
rpcInvocation.setUuid(UUID.randomUUID().toString());
}雪花算法
雪花算法(snowflake)生成Id重复问题_暗夜猎手-大魔王的博客-CSDN博客_雪花算法生成id重复的坑
分布式多个机器生成id,如何保证不重复?_trigger333的博客-CSDN博客_生成不重复的id
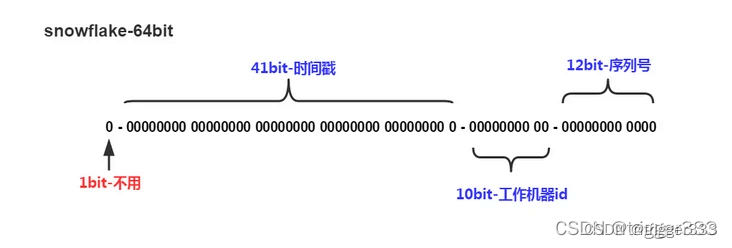
snowflake是Twitter开源的分布式ID生成算法,结果是一个long型的ID(64位)。其核心思想是:使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID),12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID),最后还有一个符号位,永远是0。
可以表示的时间长度是69年,表示1024台机器,一个毫秒内可以有4096个ID。
可以看到,生成ID的方法是加了synchronized 关键词,确保了线程安全,否则在并发情况下,生成的Id就有可能重复了
/**
* 获得下一个ID (该方法是线程安全的)
* @return SnowflakeId
*/
public synchronized long nextId() {优点:
1.毫秒数在高位,自增序列在低位,整个ID都是趋势递增的。
2.不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的。
3.可以根据自身业务特性分配bit位,非常灵活。
缺点:
强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。
dubbo中的id生成算法
使用的是AtomicLong 生成自增的id,相比较上面的加锁,会更高效。
为什么还有个mid呢,我猜想是因为 这个消息id需要在网络中传输,所以如果long 的话占用的字节数比AtomicLong 少,传输更快,而且如果是个long 那么可以放在消息头中,不需要参与序列化。
public class Request {
private static final AtomicLong INVOKE_ID = new AtomicLong(0);
private final long mId;
public Request() {
mId = newId();
}
public long getId() {
return mId;
}
private static long newId() {
// getAndIncrement()增长到MAX_VALUE时,再增长会变为MIN_VALUE,负数也可以做为ID
return INVOKE_ID.getAndIncrement();
}
}版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/92795.html

