
目录
RPC框架业务线程池的作用
如果只用Netty的主从多线程模型去监听连接和读写事件,并用 worker去处理业务逻辑,在业务逻辑耗时比较短的情况下是ok 的,如果耗时比较长,那么这个workerGroup中的worker 就会一直被占用。
这样第一它不能处理其他绑定到该worker上的读写事件,第二即使是本连接中的读写事件也会阻塞,因为本连接的所有的读写事件都是由这个连接来处理的。
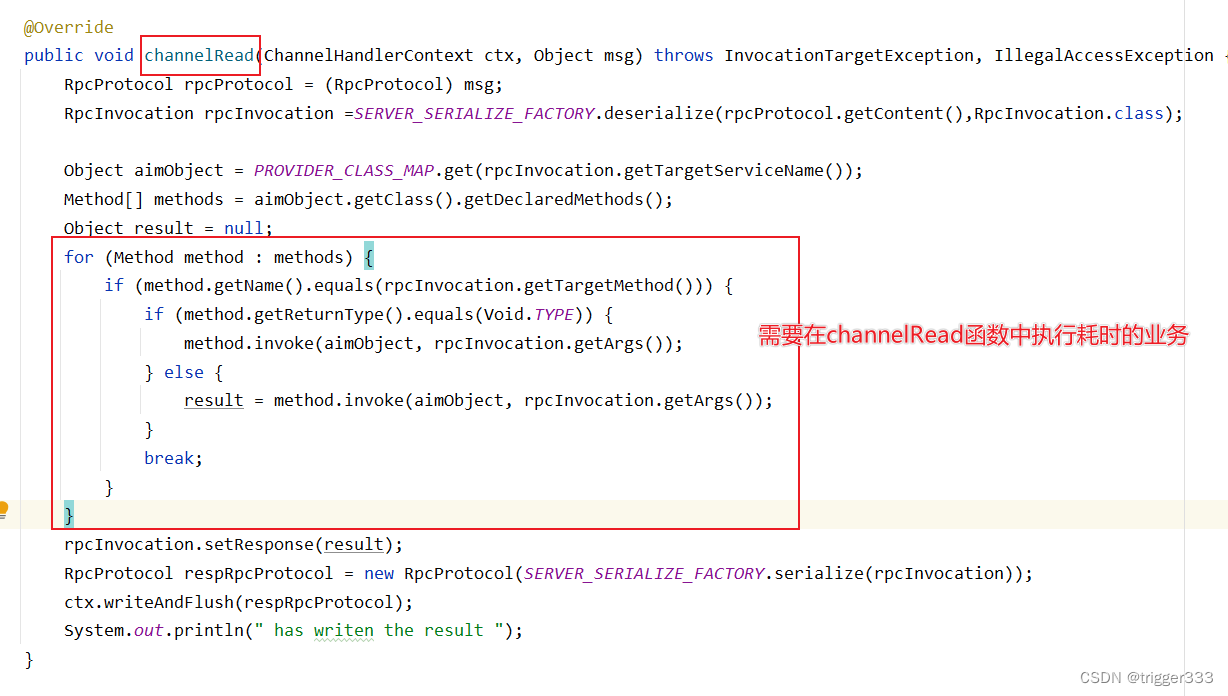
添加业务线程池之后,把传过来的数据 msg和channel 封装成一个对象丢给业务线程池。
这样可以提升整个系统的吞吐性,也就是提升整个RPC服务框架的并发承载能力

业务线程池的参数设置
根据具体的业务来定,如果是CPU密集型的,那么就设置核心线程数为CPU核数+1,IO密集型的就设置为2倍核心数(最大线程数等于核心数)。
具体的:
为什么IO密集型线程池是CPU的两倍_coffee_babe的博客-CSDN博客
单个任务总时间=CPU运算时间+IO等待时间,当任务A在等待IO时,CPU可以切到任务B进行CPU运算。如果你想拉满CPU利用率,那理想线程数 = ((CPU运算时间+IO等待时间) / CPU运算时间) * CPU核心数 ;当你认为CPU和IO时间相等时,这时就是2CPU核心数;但是在常规的Web场景下,IO时间总是远大于CPU时间,比如一个简单的数据库查询,计算可能只有0.1ms,IO则可能达到2ms,这样一算,得21CPU核心数;Tomcat和Dubbo默认核心线程数都是200,而不是简单的2*核心数。真实场景下,每个接口/任务可能时间占比和执行量都不一样,应该通过压测来确定。
实验对比
不加业务线程池,只用netty 的workerGroup,如果一个请求耗时1s,那么执行n个请求需要n s,因为是串行执行的。
添加业务线程池之后,执行n个任务需要至多 n/coreSize +1 s, (最大线程数 = 核心线程数)。
long startTime = System.currentTimeMillis();
int threadNum = 500;
CountDownLatch countDownLatch = new CountDownLatch(threadNum);
for (int i = 0; i < threadNum; i++) {
int num = i+1;
new Thread(()->{
try {
String result = dataService.sendData("test" + num);
System.out.println(result);
}catch (Exception e){
e.printStackTrace();
}finally {
countDownLatch.countDown();
}
}).start();
}
countDownLatch.await();
long endTime = System.currentTimeMillis();
System.out.println(" time cost : " + (double)((endTime - startTime)/1000) + " s");
System.out.println(" qps is : " + ( (double) threadNum/((endTime - startTime)/1000)) );版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/92797.html

