
JVM内存结构,串池,虚拟机栈,堆区等。
目录
JVM架构图
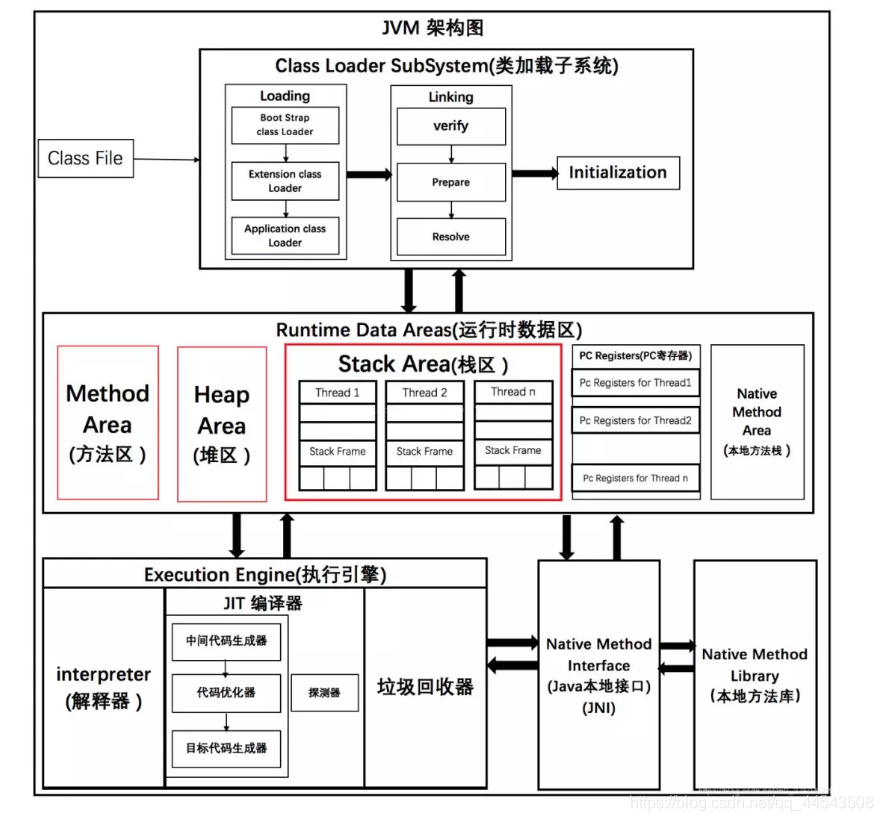

jvm内存结构主要指的是运行时数据区
内存结构
1. 程序计数器
寄存器物理实现,记录下一条jvm指令的地址。
每一个线程有一个程序计数器,是线程私有的,内存不会溢出。
2. 虚拟机栈
虚拟机栈是一个线程调用时的内存,由栈帧构成,每一个方法对应一个栈帧,每一个栈帧由局部变量,返回地址,等等构成。
栈内存 其他操作系统默认大小是1M,windows会有变动。 所以1GB内存的电脑大概可以启动
1000 000个线程。
线程数 = 物理内存/栈内存
物理内存越大 可以有更多的线程同时运行
内存溢出
1.递归调用24800多次 就会溢出
2.或者使用json包把类转化为相应的字符串时,会出现类之间的循环引用,从而导致栈帧过大,内存溢出。尽管只有一个方法不存在递归调用,但是这个方法中存储的信息过大,甚至大于阈值。
方法内的局部变量是否线程安全?
如果方法内局部变量没有逃离方法的作用访问,它是线程安全的
如果是局部变量引用了对象,并逃离方法的作用范围,需要考虑线程安全
比如一些 返回值 和 调用的参数 把一些对象比如 list 逃离了方法的作用范围
线程运行诊断
CPU占用过高,比如 while true 循环
- Linux环境下运行某些程序的时候,可能导致CPU的占用过高,这时需要定位占用CPU过高的线程
- top命令,查看是哪个进程占用CPU过高
- ps H -eo pid, tid(线程id), %cpu | grep 刚才通过top查到的进程号 通过ps命令进一步查看是哪个线程占用CPU过高
- jstack 进程id 通过查看进程中的线程的nid,刚才通过ps命令看到的tid来对比定位,注意jstack查找出的线程id是16进制的,需要转换
可以在linux下通过jstack去判断 死锁或者其他问题(死循环)程序僵死
看java 的所有运行线程以及 对应的状态
windows也可以进行
3. 本地方法栈
native方法
wait noitfy 重量级锁实现 要用 monitor 管程
clone hashcode 都是 native方法
一般是C++ 写的
4. 堆
垃圾回收机制
线程共享
创建的对象所在地方
设置堆内存 大小-Xmx 8m
jvisualvm 工具 在命令行输入: jvisualvm
查看 堆内存使用情况 以及 堆转储(当前时刻堆的快照,里面有堆的详细信息)
5. 方法区
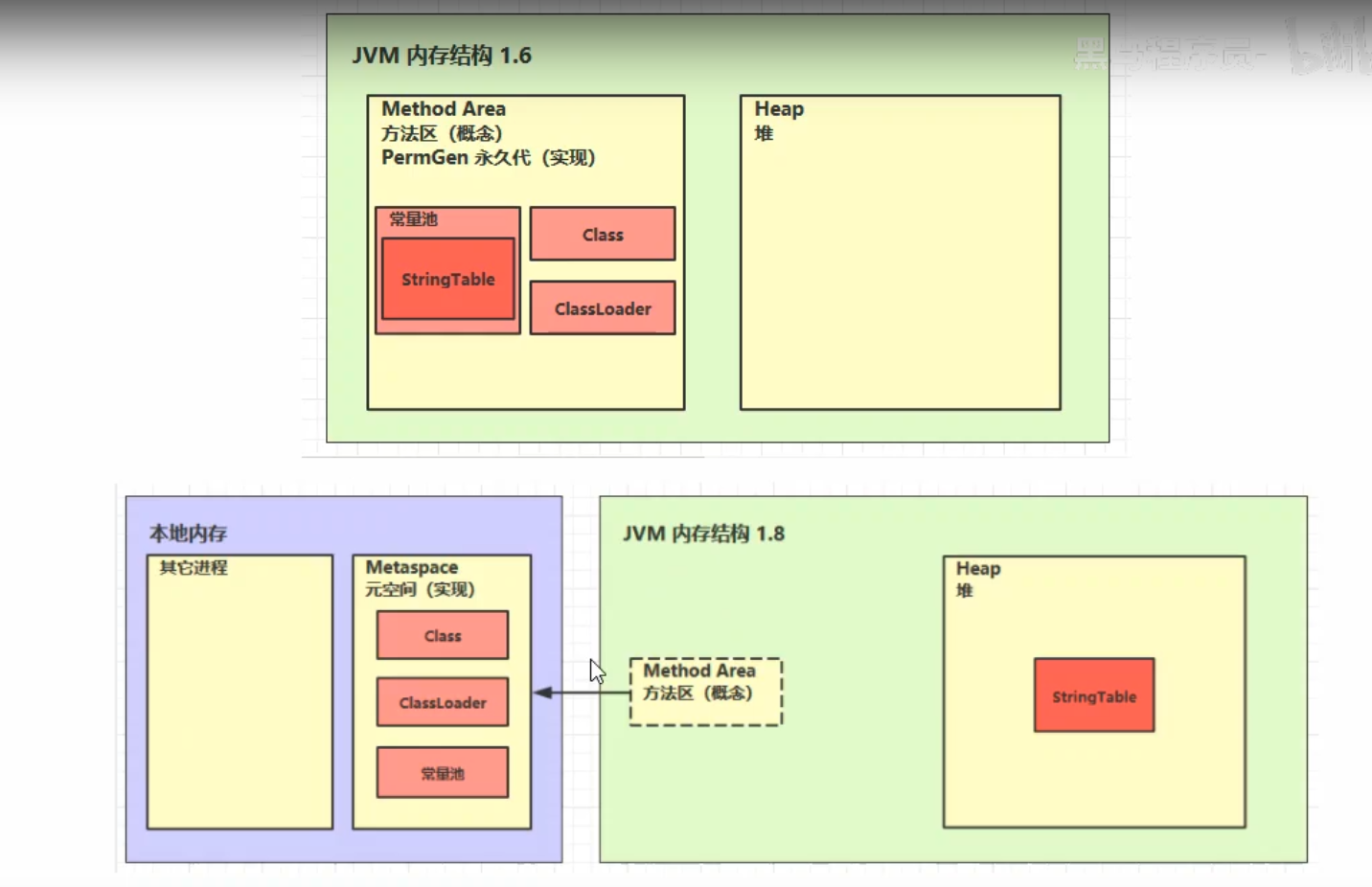
总的来说就是,JDK1.7之前,运行时常量池(字符串常量池也在里边)是存放在永久代。
JDK1.7字符串常量池被单独从永久代移到堆中,运行时常量池剩下的还在永久代(方法区)
JDK1.8,永久代更名为元空间(方法区的新的实现),但字符串常量池池还在堆中,运行时常量池在元空间(方法区)。
实际场景中 会动态加载类 cglib
就容易出现 方法区溢出,尤其是 一些框架 比如 spring等
不过目前 元空间的内存较大 所以溢出的概率就变小了
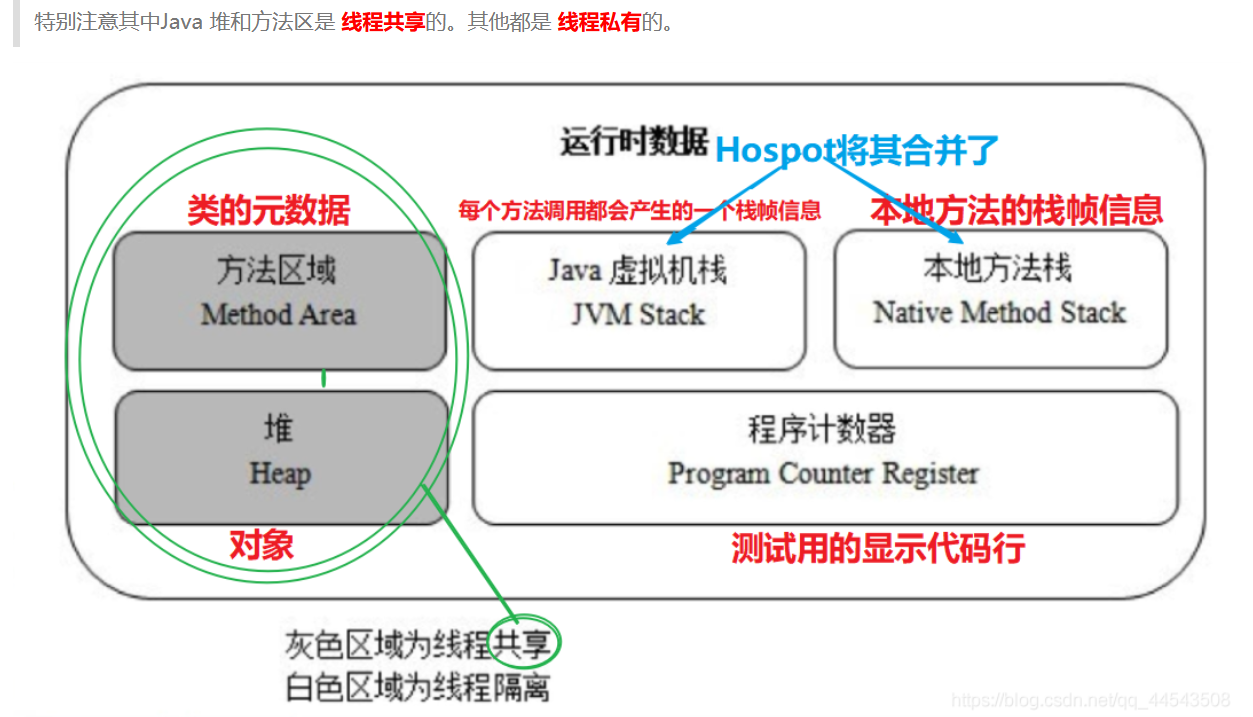
方法区(Method Area)与上面讲的Java堆一样,都是各个线程共享的,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。虽然Java虚拟机规范把方法区描述为堆的一个逻辑部分,但是它却有一个别名叫做Non-Heap(非堆),目的应该是与Java堆区分开来。
Java虚拟机规范中是这样定义方法区的:
它存储了每个类的结构信息,例如运行时常量池、字段、方法数据、构造函数和普通方法的字节码内容,还包括一些在类、实例、接口初始化时用到的特殊方法。
运行时常量池
概念上是在 方法区中,常量池,就是一张表,虚拟机指令根据这张常量表找到要执行的类名、方法名、参数类型、字面量等信息,之后转到解释器中解释为机器码指令 然后交给cpu执行。
stringtable 串池
常量池中的字符串仅是符号,第一次用到时才变为字符串对象
利用串池的机制,来避免重复创建字符串对象 ,如果两个字符串(作为key)一样,那么就会使用同一份。
字符串常量拼接的原理是编译期优化
可以使用 intern 方法,主动将串池中还没有的字符串对象放入串池
1.6 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有会把此对象复制一份(原来的对象没有变,只是在常量池中多了一个字符串), 放入串池, 会把串池中的对象返回。
1.8 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有则放入串池(移动而不是复制,也就是说堆中的对象消失了), 会把串池中的对象返回 。
只有一份 是移动不是复制
stringtable在1.6的时候是在永久代中,但是table使用比较频繁,而永久代的垃圾回收比较晚,所以效率较低。
String table又称为String pool,字符串常量池,其存在于堆中(jdk1.7之后改的)。最重要的一点,String table中存储的并不是String类型的对象,存储的而是指向String对象的索引,真实对象还是存储在堆中。
此外String table还存在一个hash表的特性,里面不存在相同的两个字符串。
面试题
串池StringTable基本了解_zhanlijuan-CSDN博客
java-方法区 (二) – StringTable串池_404QAQ的博客-CSDN博客
Stringtable 串池经典面试题_trigger的博客-CSDN博客
public class StringTable {
public static void main(String[] args) {
String s1="a";
String s2="b";
String s3="a"+"b"; // 相当于 "ab"
String s4= s1+s2; // 在堆中
String s5="ab";
String s6=s4.intern();
// 1.8 将这个字符串对象尝试放入串池,如果有则并不会放入,如果没有则放入串池(移动而不是复制,也就是说堆中的对象消失了),
// 会把串池中的对象返回 返回的就是 “ab”所在的位置
System.out.println(s3==s4);//false s3就是"ab" 在串池中 s4在堆中
System.out.println(s3==s5);// true
System.out.println(s3==s6);// true 入池后返回引用
String x2=new String("c")+new String("d");
String x1="cd";
String x3 = x2.intern();
//问,如果调换了【最后两行代码】位置呢? true 如果是jdk1.6呢 如果是1.6 都是false
System.out.println(x1==x2);// false x2无法入池 所以x2的的指向还是在堆区中
System.out.println(x1 == x3); // true 返回串池中的对象
}
}
stringtable 会发生gc,怎么调优:
如果你的程序中会用到很多的常量,stringtable的桶的个数可以设置的大一点,hash查找的速度会变快
那么存入的时间就会变快。
例子:
twitter在存储用户地址的时候本来是要放到堆内存的,使用intern后放到常量池中,内存占用由30G变为了上百M。因为地址有重复 所以串池实现了去重
6 直接内存
直接内存是java和os都可以调用 使用的内存,
分配回收成本较高,但读写性能高
应用场景:
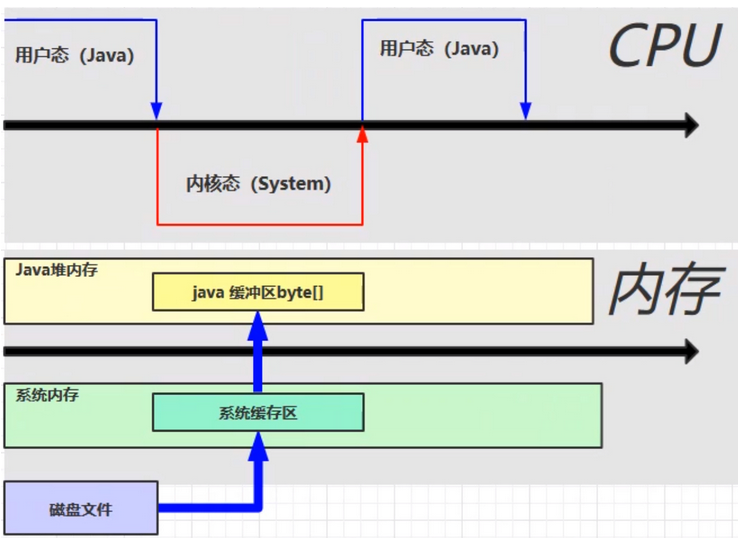
在传统的NIO操作的buffer 中,如果进行大文件的读写,
会建立一个系统缓冲区,这个缓冲区不属于jvm管控的,而是 os的
在读写时,效率就会比较低。
如果使用直接内存,那么就可以减少一次复制拷贝,效率会提升。
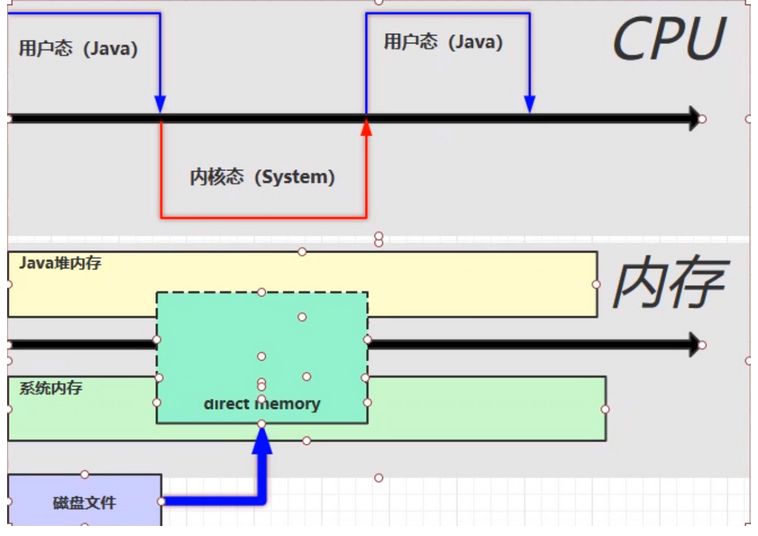
直接内存的创建和释放
直接内存可以由代码显示的创建,但是回收并不直接受到垃圾回收机制的管理,而是通过虚引用对象cleaner间接的回收。
比如bytebuffer
使用了 Unsafe 对象完成直接内存的分配回收,并且回收需要主动调用 freeMemory 方法
ByteBuffer 的实现类内部,使用了 Cleaner (虚引用)来监测 ByteBuffer 对象,一旦
ByteBuffer 对象被垃圾回收,那么就会由 ReferenceHandler 线程通过 Cleaner 的 clean 方法调
用 freeMemory 来释放直接内存
在进行jvm调优的时候,通常会禁用显式的系统gc,也就是程序员自己 gc。
那么直接内存这时就不会被释放,如何解决这个问题呢?
通常来讲还是通过显式的调用 freememory函数去释放直接内存。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/92862.html

