
一、前言
小编最近在做到一个检索相关的需求,要求按照一个字段的每个字母或者数字进行检索,如果是不设置分词规则的话,英文是按照单词来进行分词的。
小编以7.6.0版本做的功能哈,大家可以根据自己的版本去官网看看,应该区别不大
例子:
C6153PE-冬日恋歌,要可以通过任何一个数字和字母进行检索到,并且不区分大小写。c,6,c6等等!
今天官网上有一些例子,觉得和实战还是有点区别,小编这里通过了测试抓紧来记录一下,希望帮助后来人哈!
二、测试分词策略
我们进入官网找到我们需要的策略:
Elasticsearch策略官网
N-gram 分词器
每当遇到指定字符列表中的一个时,ngram标记器首先将文本分解为单词,然后发出 指定长度的每个单词的N-gram。
N-gram 就像一个在单词上移动的滑动窗口——一个指定长度的连续字符序列。它们对于查询不使用空格或复合词长的语言很有用。
我们去kibana进行测试分词策略是否符合我们的要求:
POST _analyze
{
"tokenizer": "ngram",
"text": "C6153PE-冬日恋歌"
}
分词分得细,会导致检索的效率降低,但是需求如此,没办法,最重要的是小编这里的数据量只有1w,其实换了这种分词,是无感知的!


分词策略规则:
ngram分词器接受以下参数:
| 参数 | 解释 |
|---|---|
| min_gram | 以 gram 为单位的最小长度。默认为1. |
| max_gram | 以 gram 为单位的最大字符长度。默认为2. |
| token_chars | 应包含在令牌中的字符类,Elasticsearch 将根据不属于指定类的字符进行拆分。默认为[](保留所有字符)详细参数见下表 |
| custom_token_chars | 应被视为令牌一部分的自定义字符。例如,将此设置为±_将使标记器将加号、减号和下划线符号视为标记的一部分。 |
min_gram将和设置max_gram为相同的值通常是有意义的。长度越小,匹配的文档越多,但匹配的质量越低。长度越长,匹配越具体。三元组(长度3)是一个很好的起点。官方比较推荐使用3,可能是因为效率分词粒度两不误吧,这里不符合小编的,小编这里使用是1,2,也就是默认的值
| token_chars参数 | 解释例子 |
|---|---|
| letter | 字母,例如a, b,ï或京 |
| digit | 数字,例如3或7 |
| whitespace | 空白,例如” “或”\n” |
| punctuation | 标点,例如!或” |
| symbol | 标记, 例如$或√ |
| custom | 自定义,需要使用 custom_token_chars设置设置的自定义字符 |
custom_token_chars:
应被视为令牌一部分的自定义字符。例如,将此设置为±_将使标记器将加号、减号和下划线符号视为标记的一部分。
三、在索引字段中使用
官方是使用一个字段进行测试的,这里小编就直接使用公司的索引进行演示了!
这里是官网的例子:

下面放出来小编实战后的例子:
总结就是在settings配置分词策略,在mappings中进行使用即可!!
PUT /product
{
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0,
"index": {
"max_result_window": 100000000
},
# 这里使用分词策略
"analysis": {
"analyzer": {
"my_analyzer": {
# 这里分词指定下面策略的具体配置的名称
"tokenizer": "my_tokenizer",
# 这里忽略大小写配置
"filter": [
"lowercase"
]
}
},
# 具体策略配置
"tokenizer": {
"my_tokenizer": {
"type": "ngram",
"min_gram": 1,
"max_gram": 2,
"token_chars": [
"letter",
"digit"
]
}
}
}
},
"mappings": {
"dynamic": "strict",
"properties": {
"@timestamp": {
"type": "date"
},
"@version": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"cargoNo": {
"type": "text"
},
"name": {
"type": "text"
},
"sort": {
"type": "integer"
},
"attribute13": {
"type": "text",
# 在需要的字段指定我们写的分词策略
"analyzer": "my_analyzer"
},
"isDeleted": {
"type": "integer"
}
}
}
}
四、在springboot中实战
为了公司,小编只粘贴部分条件构建规则:
SearchRequest searchRequest = new SearchRequest("product");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
BoolQueryBuilder bool = new BoolQueryBuilder();
BoolQueryBuilder boolQueryBuilder = new BoolQueryBuilder();
boolQueryBuilder.should(QueryBuilders.matchPhraseQuery("name", model))
.should(QueryBuilders.matchPhraseQuery("cargoNo", model))
.should(QueryBuilders.wildcardQuery("cargoNo", "*" + model + "*"))
// 我们分词规则的字段查询
.should(QueryBuilders.matchPhraseQuery("attribute13", model));
bool.must(boolQueryBuilder);
searchSourceBuilder.query(bool);
searchRequest.source(searchSourceBuilder);
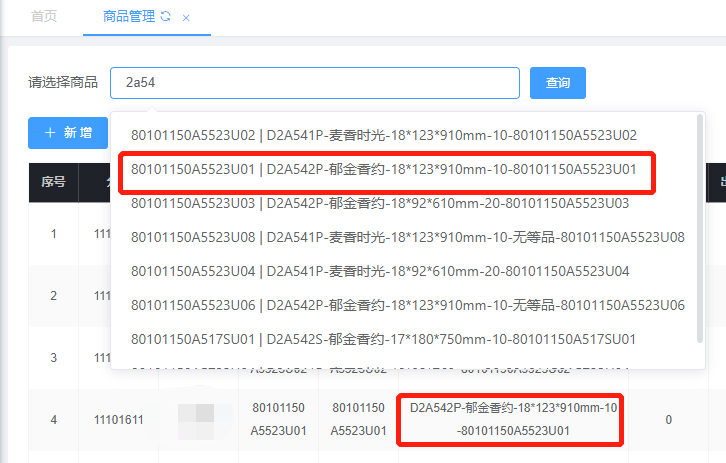
我们拿着页面感受一下分词带来的效果:
效果实现,随便一个字母都可以查询出来,这里只显示名称和一个数字,其实是使用attribute13来进行查询的,是因为attribute13是名称的第一个-之前的截出来的。
五、总结
这样我们就完成了一些定制化的需求,完美交差,还得是看官网啊!!一定要去看官网!搜了好多都没有这种的教程,写出来帮助后来人,但是详细的还得是看官网哈!小编这里也是把官网的一些概念写到了博客里!!
如果对你有帮助还请不要吝啬你的发财小手给小编来个一键三连哦!谢谢大家了!!
有缘人才可以看得到的哦!!!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/92967.html

