
一、概念
索引是一种特殊的文件,包含着对数据表里所有记录的引用指针。可以对表中的一列或多列创建索引,并指定索引的类型,各类索引有各自的数据结构实现。
二、作用
- 数据库中的表、数据、索引之间的关系,类似于书架上的图书、书籍内容和书籍目录的关系。
- 索引所起的作用类似书籍目录,可用于快速定位、检索数据。
- 索引对于提高数据库的性能有很大的帮助。
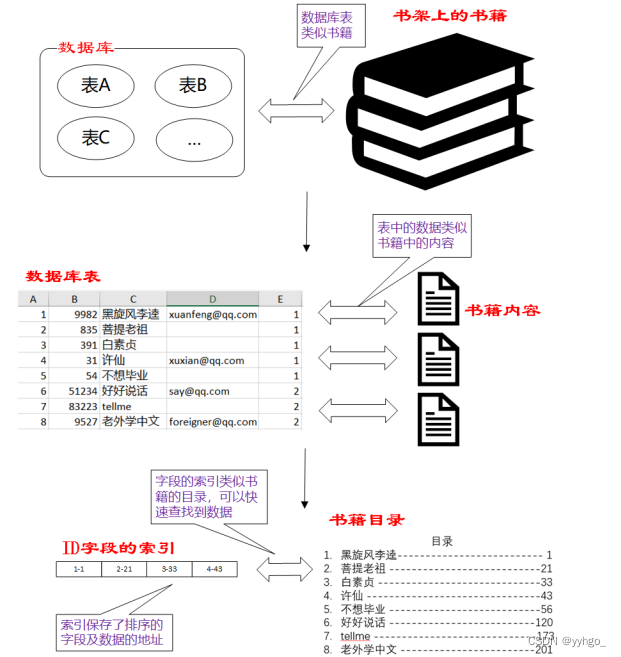

索引本质上相当于“书的目录”,通过目录,就可以快速查找到某个章节对应的位置。所以索引的效果就是加快了查找的速度~~(我们进行数据库操作,无非就是增删改查。而在多数场景中,查的概率是比增删改要多很多的)
但是索引也提高了增删改的开销。因为此时进行增删改,就需要调整已经创建好了的索引(目录)了。(其次索引还提高了空间的开销:构造索引,也就需要额外的硬盘空间来保存了)
而查的概率是比增删改要多很多的,因此大多数情况下,引入索引还是划算的。
三、使用场景
要考虑对数据库表的某列或某几列创建索引,需要考虑以下几点:
- 数据量较大,且经常对这些列进行条件查询。
- 该数据库表的插入操作,及对这些列的修改操作频率较低。
- 索引会占用额外的磁盘空间。
满足以上条件时,考虑对表中的这些字段创建索引,以提高查询效率。
反之,如果非条件查询列,或经常做插入、修改操作,或磁盘空间不足时,不考虑创建索引。
四、使用
这里我们用student表来举例!
4.1 查看索引
show index from student;
4.2 创建索引
创建主键约束(PRIMARY KEY)、唯一约束(UNIQUE)、外键约束(FOREIGN KEY) 时,会自动创建对应列的索引。
主动创建:
如果查询操作很多时候是按照名字来查询的,那么这个时候就需要去根据名字这一列来创建索引了:
create index idx_student_name on student(name);
创建索引,最好是在表创建之初就把索引给搞好。如果是针对一个已经有很多很多记录的表来创建索引,这也是一个危险操作! 这个时候就会吃掉大量的磁盘IO,花很长的时间,可能是几十分钟到几个小时(根据数据量),在这段时间里,数据库是无法被正常使用的!
索引是为了加快查询的速度,也不是所有的情况加上索引就一定快!如果是针对像性别这样的列加索引,或者针对大学生管理系统的年龄这样的列加索引,就无法提高查找速度。
如果姓名有重复,索引能不能加上,会不会报错呢?不会报错,能加上。只要重名不是很多,这个时候还是能大大提高查询的速度~~
4.3 删除索引
drop index idx_student_name on student;
和刚才的创建索引类似,删除索引也可能会吃大量的磁盘IO,也是比较危险的操作!
所以最开始设计数据库的时候、创建表的时候,就要规划好。如果已经有大量数据,再进行操作,就得慎重!
4.4 索引的使用
咱们把索引创建好了之后,不需要手动使用,直接查询的时候就会自动来走索引。
SQL是通过数据库的执行引擎来进行执行的,这里涉及到一些“优化”操作。
具体这一次查询,实际上是否在走索引,以及怎么走的,其实咱们是不好预期的。执行引擎会自动评估哪种方案是成本最低、速度最快的~~
可以使用explain这个关键字,显示出查询过程中具体的使用索引的情况。
(补充:代码优化,不只是SQL有。C、C++、Java 这些主流的语言都有代码优化的能力。你自己写的一段代码,这个代码不一定就是最优解,可能会有一些更好的写法,编译器 / 运行环境(虚拟机)就会综合评估,可能就会在保持你原有代码含义不变的基础上,对你的代码进行调整。这些都是编译器开发者 / 运行环境开发者,这些牛逼的大佬们,为了能够降低程序猿之间的水平的差值而给出的方案~)
五、索引在MySQL中的底层
索引在mysql中的数据结构是什么呢?
现在我们知道,索引主要的目的是为了加快查找速度。那么哪种数据结构合适呢?
我们可以想到:
-
哈希表
但是很遗憾,哈希表不适合做数据库的索引,因为哈希表只能比较相等,而无法进行<、>这样的范围查询!很明显,数据库经常需要范围查询~ -
二叉搜索树
二叉搜索树好像可以范围查询了:查起点,查终点(树里的元素中序遍历是有序的)
但是很遗憾,数据库并没有使用二叉搜索树。因为二叉意味着当元素个数多了的时候,树的高度就会比较高,树的高度就决定了查找的时候元素的比较次数,而数据库进行比较都是要读硬盘的,更慢~ -
所以我们考虑用N叉搜索树:每个节点上有多个值,同时有多个分叉。这时树的高度就降低了~
其中的一种典型实现,叫作B树:
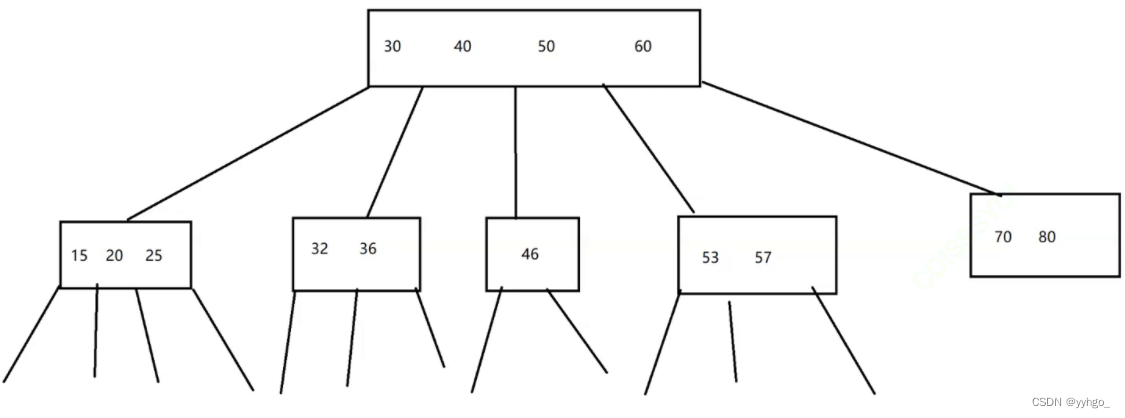
比较次数虽然没咋减少(一个节点上可能需要比较多次了),但是读写硬盘的次数减少了(每个节点都是在硬盘上存储的)。 -
B树已经可以比二叉搜索树更适合于做数据库的索引了,但是还不够~~针对这里,又引入了B+树,是对B树进行了进一步的改进,可以说B+树就是为了索引这个场景而量身定做的数据结构(也是N叉搜索树,又有一些新的特点):
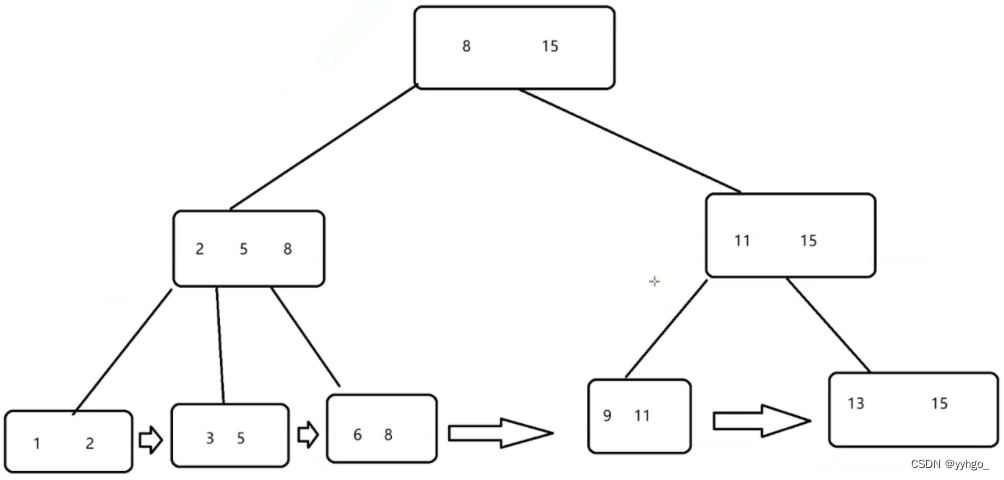
1.B+树也是一个N叉搜索树,每个节点上可能包含N个key,N个key划分出N个区间。最后一个key就相当于最大值了。
2.父元素的key会在子元素中重复出现,并且是以最大值的姿态出现的。这样的重复出现就导致叶子节点就包含了所有数据的全集!(非叶子节点中的所有值都会在叶子节点中体现出来)
3.会把叶子节点,用类似于链表的方式首尾相连。
上述B+树的特点,就带来了一些好处:
1.作为一个N叉搜索树,高度降低下来,比较的时候硬盘IO次数就比较少了(同B树)。
2.更适合进行范围查询。
3.所有的查询,都是要落在叶子节点上的。无论查询哪个元素,中间比较的次数差不多,查询操作比较均衡(对于B树来说,可能是有的值查得快,有的查得慢,可能就不均衡了,而不均衡是有风险的~(在根节点,或者深度不深的位置都查得快);而B+树,大家都是一样的速度)。
4. 由于所有的key都会在叶子节点中体现,因此非叶子节点不必存表的真实记录(不必存数据行),只需要把所有的数据行给放到叶子节点上即可~~非叶子节点只需要存索引列的值(比如id)。由于非叶子节点只存了简单id,没有存一整行,这就意味着非叶子节点所占用的空间是大大降低的,有可能可以缓存在内存中,更进一步地降低了硬盘IO!!!提高查询速度,本质上就是减少硬盘IO次数!!!
因此,数据库里不一定就是按照连续的空间来组织表这样的结构(不一定),有很大概率是基于B+树结构来构造的,尤其是带有主键的表~~(主键自带索引)
补充:
1.有的表不只是有主键索引,还有别的非主键列也有索引,这个情况会构造另一个B+树,B+树非叶子节点里面存的都是这一列里面的key。到了叶子节点这一层,不再是存完整的数据行,而是存主键id!
因此使用主键列来查询,只需要查一次B+树就可以了;而如果是使用非主键列的索引来查询,则需要先查一遍索引列的B+树,再查一遍主键列的B+树(这个操作叫作“回表”)!!!
2.当前B+树这个结构,只是针对MySQL的 InnoDB(最主流使用的一种存储引擎)这个数据库引擎里面所典型使用的数据结构。不同的数据库,不同的引擎,里面的存储数据的结构还可能存在差异~~
像咱们前面说的哈希表这样的结构,不太适合作索引,但也不是完全没有。有的特殊的存储引擎,为了应付特定场景,也是可能会使用哈希表的。(存储引擎:引擎这个词其实还是挺常见的,往往指的是“最核心的模块”,数据库的存储引擎其实就是实现了数据库具体如何在硬盘上组织数据。除此之外还有SQL解析执行引擎等)
面试题:
谈谈数据库索引,你是怎么理解的?
回答就是以上的内容~~
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/93254.html

![[Abp 源码分析]十一、权限验证](https://www.bmabk.com/wp-content/uploads/2022/05/post-loading-480x300.gif)