
前言
近期优化SQL的次数越来越多了,优化的思路可以从SQL结构、执行计划、统计信息、执行计划缓存、索引合理性(数据离散度、联合索引等)、程序的数据库连接池参数、数据库自身参数、数据库部署架构等方面看。
这次优化涉及了PostgreSQL的分区表,和单表不同,分区表有一些特性,导致它和普通表有一些区别,例如数据库版本(影响分区表特性)、分区类型(Hash分区、range分区、List分区等)。
本次优化的都是Hash分区的,亿级别的基础数据,根据Hash分区
优化过程
数据库版本
PostgreSQL 11.1 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.9.4, 64-bit
要注意,数据库版本对优化方案有关键影响,每一版
总体思路
慢SQL是根据监控平台发现的,有一些是分区表,单表查询也很慢,也有分区表和普通表联表的。
其实分区和其他类型数据库的水平分库分表是类似的,抓住最关键的分区键即可,也可以叫全局唯一id。
分区键是多表联合查询的关键,在带分区键的时候,可以直接命中子分区表,不带的时候会扫描所有子分区表。
分区键
原SQL未使用无分区键的执行计划
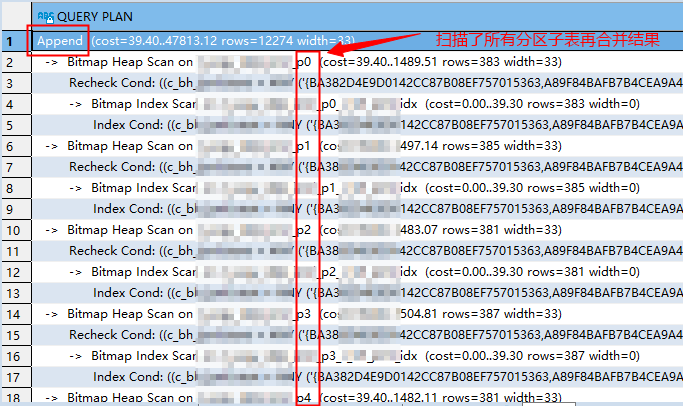
在SQL的查询条件中使用分区键,直接名中分区键所在分区子表

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/93690.html

