
文章目录
一、概念
二、哈希冲突
冲突的发生是必然的,但应该是尽量的
降低冲突率。
三、如何解决哈希冲突?
1.哈希函数
引起哈希冲突的一个原因可能是:哈希函数设计不够合理。 哈希函数设计原则: 哈希函数的定义域必须包括需要存储的全部元素,而如果散列表允许有m个地址时,其值域必须在0到m-1之间哈希函数计算出来的地址能均匀分布在整个空间中。
常见的哈希函数:直接定制法(Hash(Key)= A*Key + B)、除留余数法(Hash(key) = key% p)、平方取中法(假设关键字为1234,对它平方就是1522756,抽取中间的3位227作为哈希地址)、随机数法(即H(key) = random(key),random为随机函数)等等。哈希函数设计的越精妙,产生哈希冲突的可能性就越低,但是还是无法避免哈希冲突。
2.负载因子调节

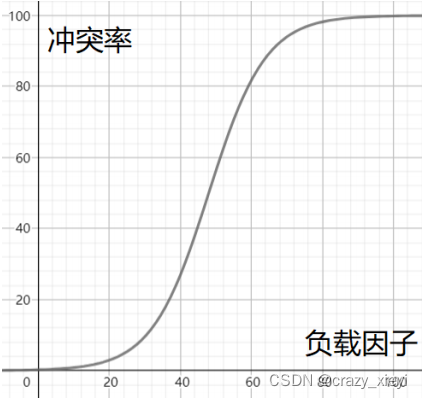
哈希表中已有的元素个数是不可变的,那能调整的就只有哈希表中的数组的大小了。
3.闭散列
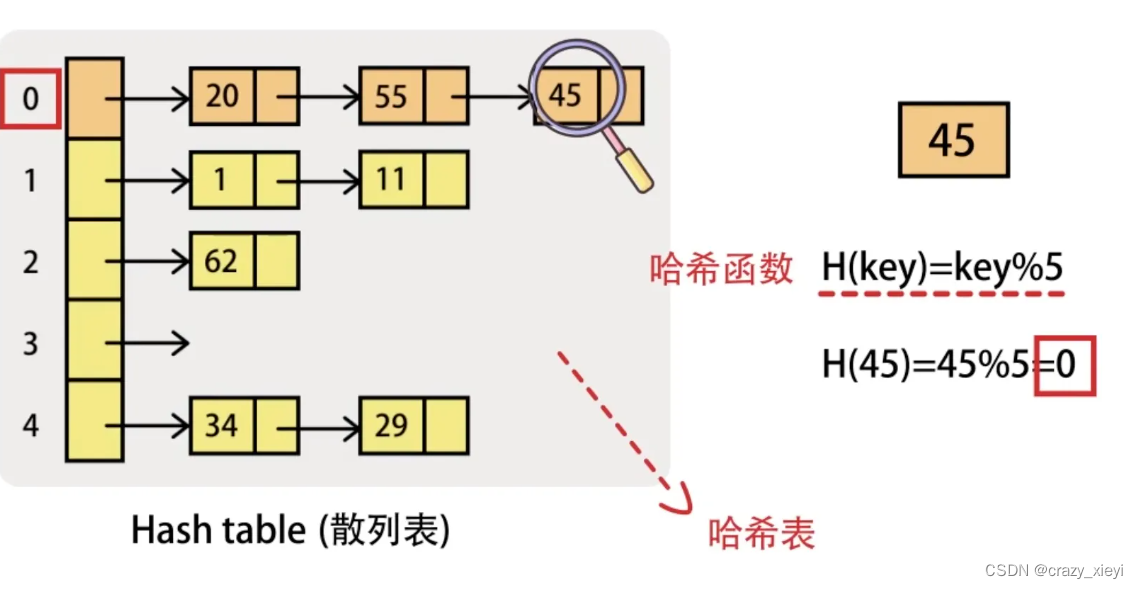
4.开散列(哈希桶)
开散列法又叫链地址法(开链法),首先对元素集合用散列函数计算散列地址,具有相同地址的元素归于同一子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表链接起来,各链表的头结点存储在哈希表中。开散列中每个桶中放的都是发生哈希冲突的元素。开散列,可以认为是把一个在大集合中的搜索问题转化为在小集合中做搜索了。那如果冲突严重,就意味着小集合的搜索性能其实也时不佳的,这个时候我们就可以将这个所谓的小集合搜索问题继续进行转化,例如:
四、模拟实现哈希桶
public class HashBucket<K,V> {
static class Node<K,V>{
public K key;
public V val;
public Node<K,V> next;
public Node(K key,V val){
this.key = key;
this.val = val;
}
}
public Node<K,V>[] array;
public int size;
private static final double LOAD_FACTOR = 0.75;
private static final int DEFAULT_SIZE = 8;
public HashBucket(){
this.array = new Node[DEFAULT_SIZE];
}
public Node<K,V> put(K key, V value) {
int hash = key.hashCode();
int index = hash % array.length;
Node<K,V> cur = array[index];
while (cur != null){
if (cur.val == value){
cur.val = value;
return cur;
}
cur = cur.next;
}
Node<K,V> node = new Node<>(key,value);
node.next = array[index];
array[index] = node;
size++;
if (loadFactor() >= LOAD_FACTOR){
resize();
}
return node;
}
private void resize() {
Node<K,V>[] newArray = new Node[2*array.length];
for (int i = 0; i < array.length; i++) {
Node<K,V> cur = array[i];
while (cur != null){
Node<K,V> curNext = cur.next;
int hash = cur.key.hashCode();
int newIndex = hash % newArray.length;
cur.next = newArray[newIndex];
newArray[newIndex] = cur;
cur = curNext;
}
}
array = newArray;
}
public Node<K,V> get(K key,V val){
int hash = key.hashCode();
int index = hash % array.length;
Node<K,V> node = array[index];
while (node != null){
if (node.key == key){
return node;
}
node = node.next;
}
return null;
}
private double loadFactor() {
return size * 1.0 / array.length;
}
}总结
哈希表的插入
/
删除
/
查找时间复杂度是
O(1)
。
hashCode 方法,进行 key 的相等性比较是调用 key 的
equals 方法。所以如果要用自定义类作为 HashMap 的 key 或者 HashSet 的值,
必须重写
hashCode
和
equals
方
法,而且要做到 equals 相等的对象,hashCode 一定是一致的。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/94568.html

