
背景
分布式、缓存、异步和多线程被称为互联网开发的四大法宝。今天我总结一下项目开发中常接触的四种缓存实际项目中遇到过的问题。
JVM 堆内缓存
JVM 堆内缓存因为可以避免 Memcached、Redis 等集中式缓存网络通信故障问题,目前还在项目中广泛使用。
堆内缓存需要注意 GC 的问题。假如我们的设计是定时的从远程来拉取数据更新本地缓存。一定要注意两点:第一不要全量拉取覆盖,第二不要把一个大对象整体替换为新对象。
先说全量拉取覆盖。全量拉取会有很大的网络开销,会造成网络流量尖刺。有人说没事,我们带宽很足,内网访问,不怕不怕。但是稳定性需要修炼的一项是削峰填谷。让系统在平稳的环境中运行。不然,在拉取大缓存新数据的数据突然来了个突发流量?根据墨菲定律,凡是有几率会发生的事情就一定会发生。编程需谨慎。
再说大对象整体替换的问题,这会造成 GC 问题。伪代码如下:
List<POJO> oldList = initList();public void refresh() {List<POJO> newList = dataFromNetworkService.getAll();oldList = new List();for(POJO pojo : newList) {oldList.add(pojo);}}
如果从网上拉取的数据和在缓存里存储的数据,对象类型没有发生改变。引起的转换开销还稍微小点。因为比如对象 POJO 存在一个列表里。这个列表虽然很大,但是里面存的都是对象的引用。实际的 POJO 并没有发生变化。上面伪代码虽然新建一个 List 对象,遍历添加新对象比直接 oldList=newList 要傻些。但是遍历过程实际上 POJO 对象没有发生改变。所以这里影响 GC 的只是 oldList 这个对象(不包括从网络上拉取回来数据的过程)。
但是如果代码这样写:
List<POJO2> oldList = initList();public void refresh() {List<POJO1> newList = dataFromNetworkService.getAll();oldList = new List();for(POJO2 pojo : newList) {oldList.add(Beanutils.copy(new POJO2(), pojo));}}
遍历过程将会将原来的 POJO1 全部新建一遍,这些对象一般情况下全部先进入堆内存的新生代,再经过数次 Young GC 后进入老年代。会造成GC频繁。
我所做过的项目,一般认为一天一到两次 Full GC 为合理值。这样,如果比如预先知道某个时间点有大促,可通过提前触发 GC 等方式避免高峰期爆发 Full GC。Young GC 至少是 5 分钟一次,甚至更久触发认为是正常。这样可以通过控制避过秒杀等场景。
JVM 堆外缓存
堆外缓存的内存回收原理使用的是 Java 的虚引用 。这个设计可以避免 JVM 的 GC 问题,但是处理不好可能会造成更严重的后果:整个机器内存被打满,机器可能会挂掉。 其实挂掉一台在一般企业的生产环境还好,因为一般都会有容灾的冗余机器。 但是更常见的一种情况是机器忙于 swap 内存交换,机器活着但是响应很慢。 属于半死不活。 这个问题我没在线上遇到过,但是我同事之前在超级大厂的时候遇到过。
有的同学说那我严格算好内存,做好监控。这里面要就要依赖人为的因素来做紧急处理。而人是稳定性中最不可靠的。因为问题通常不发生在人清醒、手里事情很少的时候。而是一种雪上加霜的存在。比如大促时,流量上来了,线程数会增多,每个线程都会申请线程栈资源,系统处理 IO,这时候系统会申请更多的 buffers/cached 内存。
Linux 的 buffers/cached
Linux 系统上运行一下 top 命令或者 free 命令,都能够看到 buffers 和 cached 相关的数据。需要注意的是通常我们看到的监控数据空闲内存百分比,并非是下面显示的 free/total,而是 (free+buffers+cached)/total。
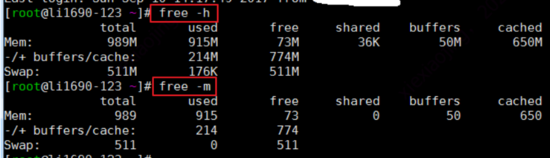
buffers 在 Linux 系统中通常被作为与块存储的 IO 缓存使用。所谓块存储可简单理解为将数据直接写到裸磁盘。而 cached 则一般会用于文件系统的 IO 缓存。比如 page cache 这种内存换页功能。
听不明白也没关系,因为事实上它们两个经常配合使用。比如与磁盘交换数据、进行网络通信时都会用。buffers 和 cached 是实实在在被操作系统的系统进程在使用的,但是如果用户进程需要可以很快释放。所以通常会将它算到剩余可用内存里。
但是这个也要注意了。比如在 IO 密集型的系统,如果 buffers/cached 被大幅占用,会降低 IO 速度,进而降低系统吞吐。甚至有可能一个请求几秒才能到达应用程序,造成请求超时。
集中式缓存
Redis 缓存其实也有本机代理,可以缓存一些活跃的数据在本机上,本机可以在取 不 到数据时不需要跨网络通信。但是因为 Redis 本质是 key-value 的结构。如果需要根据通配符取数据全量,如果网络出现故障,可能会影响数据的完整性。
但是 Redis 缓存最让人担心的是不规范的使用方法。比如存一个很大的 value。具体这个对网络和存储造成的问题就不详细说了。可以想象下马桶堵了的情景。
总结
贝尔实验室的面向对象编程专家 Tom Cargill 说:
最初 90% 的开发工作将会用去你最初 90% 的开发时间,剩下的 10% 的开发量将会用去你另外一个 90% 的开发时间。
我理解剩下 10% 占用了 90% 的时间是由于超出了原有知识贮备,需要临时抱佛脚,甚至需要拿着锤子找钉子造成的。所以或者也可以这样做:
每周持续投入 5% 的学习时间,10% 的思考时间,再用 100% 的时间去完成 100% 的开发
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/94707.html

