
1 集群脑裂
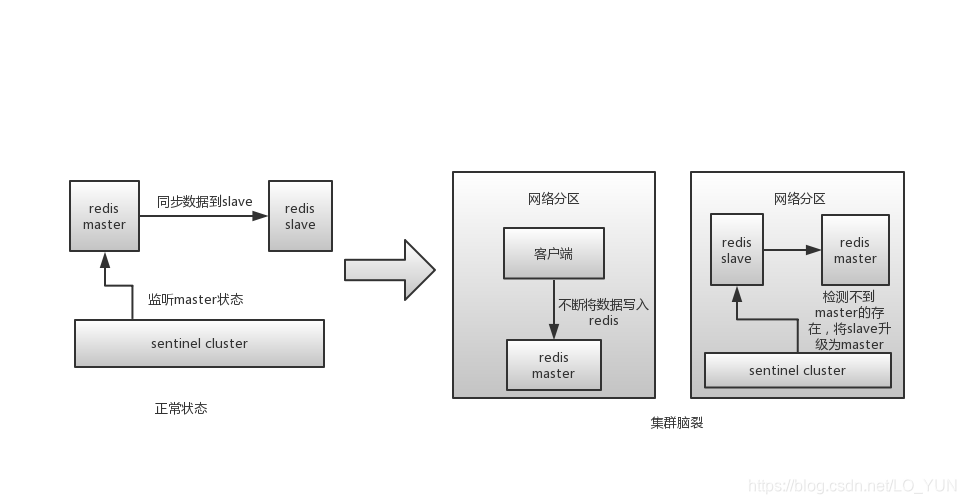
redis 的集群脑裂是指因为网络问题,导致 redis master 节点跟 redis slave 节点和 sentinel 集群处于不同的网络分区,此时因为 sentinel 集群无法感知到 master 的存在,所以将 slave 节点提升为master 节点。此时存在两个不同的 master 节点,就像一个大脑分裂成了两个。
集群脑裂问题中,如果客户端还在基于原来的 master 节点继续写入数据,那么新的 master 节点将无法同步这些数据,当网络问题解决之后,sentinel 集群将原先的master节点降为 slave 节点,此时再从新的 master 中同步数据,将会造成大量的数据丢失。

2 解决方案
redis的配置文件中,存在两个参数:
min-slaves-to-write 3
min-slaves-max-lag 10
- 第一个参数表示连接到master的最少slave数量
- 第二个参数表示slave连接到master的最大延迟时间
按照上面的配置,要求至少3个slave节点,且数据复制和同步的延迟不能超过10秒,否则的话master就会拒绝写请求,配置了这两个参数之后,如果发生集群脑裂,原先的master节点接收到客户端的写入请求会拒绝,就可以减少数据同步之后的数据丢失。
注意:较新版本的 redis.conf 文件中的参数变成了
min-replicas-to-write 3
min-replicas-max-lag 10
redis中的异步复制情况下的数据丢失问题也能使用这两个参数。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/9473.html

