
一、基础原理
我们知道 spark 是用 scala 开发的,而 scala 又是基于 Java 语言开发的,那么 spark 的底层架构就是 Java 语言开发的。如果要使用 python 来进行与 java 之间通信转换,那必然需要通过 JVM 来转换。我们先看原理构建图:
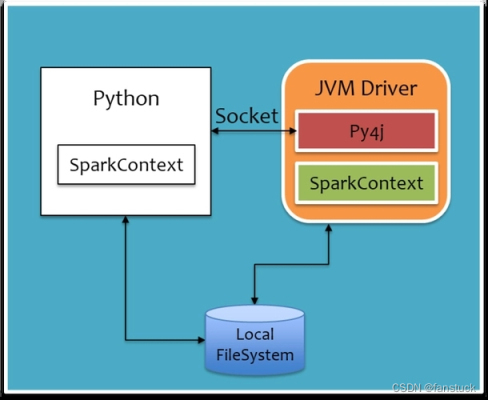

从图中我们发现在 python 环境中我们编写的程序将以 SparkContext 的形式存在,Pythpn 通过于 Py4j 建立 Socket 通信,通过 Py4j 实现在 Python 中调用 Java 的方法,将我们编写成 python 的 SpakrContext 对象通过 Py4j,最终在 JVM Driver 中实例化为 Scala 的 SparkContext。
那么我们再从 Spark 集群运行机制来看:
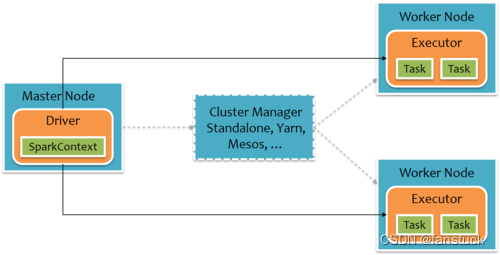
主节点运行 Spark 任务是通过 SparkContext 传递任务分发到各个从节点,标橙色的方框就为 JVM。通过 JVM 中间语言与其他从节点的 JVM 进行通信。之后 Executor 通信结束之后下发 Task 进行执行。
此时我们再把 python 在每个主从节点展示出来:
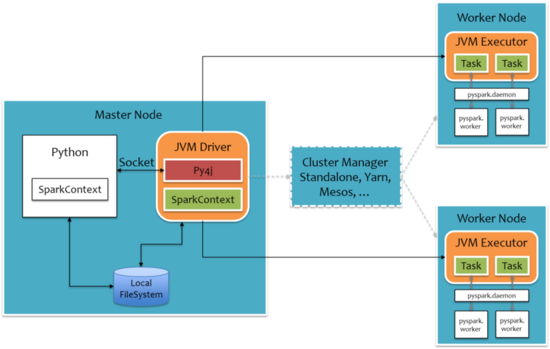
这样就一目了然了:主节点的 Python 通过 Py4j 通信传递 SparkContext,最后在 JVM Driver 上面生成 SparkContxt。主节点 JVM Driver 与其他从节点的 JVM Executor 通信传输 SparkContext,JVM Executor 通过分解 SparkContext 为许多 Task,给 pyspark.daemon 调用 pyspark.work 从 socket 中读取要执行的 python 函数和数据,开始真正的数据处理逻辑。数据处理完成之后将处理结果写回 socket,jvm 中通过 PythonRDD 的 read 方法读取,并返回结果。最终 executor 将 PythonRDD 的执行结果上报到 drive 上,返回给用户。
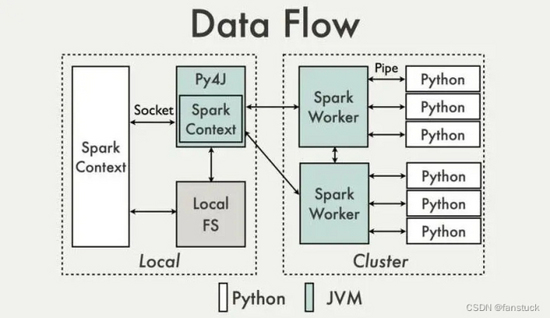
完整了解 PySpark 在集群上运行的原理之后,再看上图就很容易理解了。
Executor 端运行的 Task 逻辑是由 Driver 发过来的,那是序列化后的字节码,虽然里面可能包含有用户定义的 Python 函数或 Lambda 表达式,Py4j 并不能实现在 Java 里调用 Python 的方法,为了能在 Executor 端运行用户定义的 Python 函数或 Lambda 表达式,则需要为每个 Task 单独启一个 Python 进程,通过 socket 通信方式将 Python 函数或 Lambda 表达式发给 Python 进程执行。
二、程序运行原理
1.主节点 JVM 运行过程
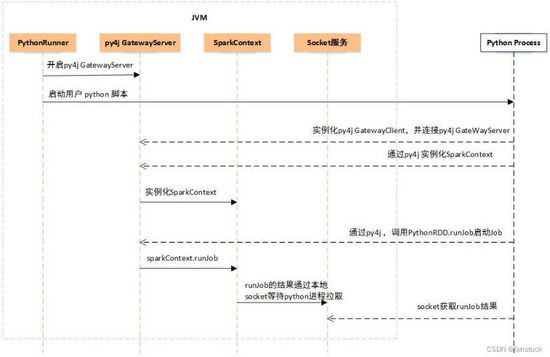
当我们提交 pyspark 的任务时,会先上传 python 脚本以及依赖并申请资源,申请到资源后会通过 PythonRunner 拉起 JVM。
首先 PythonRunner 开启 Pyj4 GatewayServer,通过 Java Process 方式运行用户上传的 Python 脚本。
用户 Python 脚本起来后,首先会实例化 Python 版的 SparkContext 对象,并且实例化 Py4j GatewayClient,连接 JVM 中的 Py4j GatewayServer,后续在 Python 中调用 Java 的方法都是借助这个 Py4j Gateway。然后通过 Py4j Gateway 在 JVM 中实例化 SparkContext 对象。
过上面两步后,SparkContext 对象初始化完毕,与其他从节点通信。开始申请 Executor 资源,同时开始调度任务。用户 Python 脚本中定义的一系列处理逻辑最终遇到 action 方法后会触发 Job 的提交,提交 Job 时是直接通过 Py4j 调用 Java 的 PythonRDD.runJob 方法完成,映射到 JVM 中,会转给 sparkContext.runJob 方法,Job 运行完成后,JVM 中会开启一个本地 Socket 等待 Python 进程拉取,对应地,Python 进程在调用 PythonRDD.runJob 后就会通过 Socket 去拉取结果。
2.从节点 JVM 运行过程
当 Driver 得到 Executor 资源时,通过 CoarseGrainedExecutorBackend(其中有 main 方法)通信 JVM,启动一些必要的服务后等待 Driver 的 Task 下发,在还没有 Task 下发过来时,Executor 端是没有 Python 进程的。当收到 Driver 下发过来的 Task 后,Executor 的内部运行过程如下图所示。
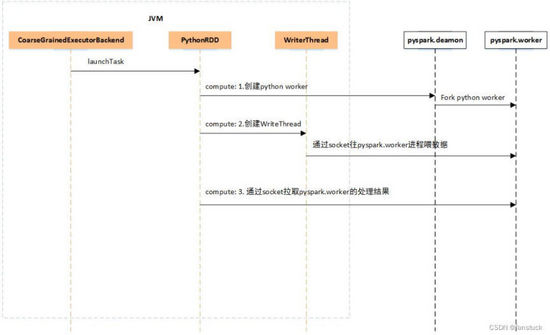
Executor 端收到 Task 后,会通过 launchTask 运行 Task,最后会调用到 PythonRDD 的 compute 方法,来处理一个分区的数据,PythonRDD 的 compute 方法的计算流程大致分三步走:
-
如果不存在 pyspark.deamon 后台 Python 进程,那么通过 Java Process 的方式启动 pyspark.deamon 后台进程,注意每个 Executor 上只会有一个 pyspark.deamon 后台进程,否则,直接通过 Socket 连接 pyspark.deamon,请求开启一个 pyspark.worker 进程运行用户定义的
-
Python 函数或 Lambda 表达式。pyspark.deamon 是一个典型的多进程服务器,来一个 Socket 请求,fork 一个 pyspark.worker 进程处理,一个 Executor 上同时运行多少个 Task,就会有多少个对应的 pyspark.worker 进程。
-
紧接着会单独开一个线程,给 pyspark.worker 进程输入数据,pyspark.worker 则会调用用户定义的 Python 函数或 Lambda 表达式处理计算。在一边输入数据的过程中,另一边则通过 Socket 去拉取 pyspark.worker 的计算结果。
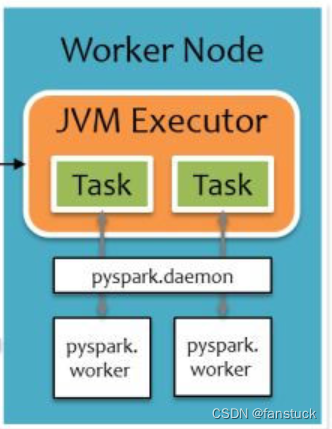
把前面运行时架构图中 Executor 部分单独拉出来,如下图所示,橙色部分为 JVM 进程,白色部分为 Python 进程,每个 Executor 上有一个公共的 pyspark.deamon 进程,负责接收 Task 请求,并 fork pyspark.worker 进程单独处理每个 Task,实际数据处理过程中,pyspark.worker 进程和 JVM Task 会较频繁地进行本地 Socket 数据通信。
三、总结
总体而言,PySpark 是借助 Py4j 实现 Python 调用 Java,来驱动 Spark 应用程序,本质上主要还是 JVM runtime,Java 到 Python 的结果返回是通过本地 Socket 完成。虽然这种架构保证了 Spark 核心代码的独立性,但是在大数据场景下,JVM 和 Python 进程间频繁的数据通信导致其性能损耗较多,恶劣时还可能会直接卡死,所以建议对于大规模机器学习或者 Streaming 应用场景还是慎用 PySpark,尽量使用原生的 Scala/Java 编写应用程序,对于中小规模数据量下的简单离线任务,可以使用 PySpark 快速部署提交
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/94756.html

