
学习目标
1、容器类别
2、每种容器的数据结构
3、每种容器的适用场景
4、优缺点
一、Collections【存放单一元素】
1.1List【有序,可重复】
(1)LinkList
数据结构:链表
优点:适合在链表的中间添加和删除元素的场景【注:在尾部操作元素效率还是数组高】
缺点:查询慢【原因:链表需要遍历】
适用场景:增删多的场景
(2)ArrayList
数据结构:数组
优点:检索速度快【数组能根据下标定位】
缺点:对中间的元素进行增删的时候慢【每个内存地址都需要移动】
适用场景:查询多的场景;对尾部增删多的场景
扩容:1.5倍左右,位操作
int newCapacity = oldCapacity + (oldCapacity >> 1);
- 当不传初始值的时候,赋初始值10;有初始值直接赋值
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
// 强制初始值10
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("Illegal Capacity: "+
initialCapacity);
}
}
- 当满的时候进行扩容通过位运算加原来的长度约定于扩容原来的1.5倍;将老list中的值copy到一个新的list中(扩容图片和源码)
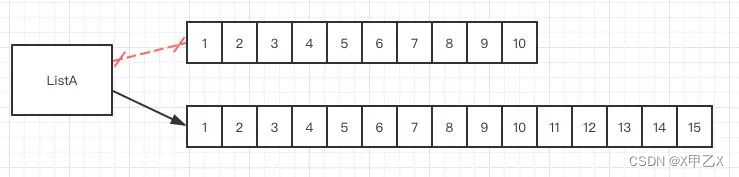

private void grow(int minCapacity) {
// overflow-conscious code
int oldCapacity = elementData.length;
// 扩容算法
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// minCapacity is usually close to size, so this is a win:
// 将原来的list中的值copy到新的扩容好的list中
elementData = Arrays.copyOf(elementData, newCapacity);
}
(3)Vector【过时:加锁太多,影响效率】
类似ArrayList,不一样的地方就是Vector线程安全,扩容机制不同
1.2Set【不可重复】
(1)HashSet
使用HashMap的key来存储元素,无序
(2)LinkedHashMap
使用HashSet+LinkedList,有序
(3)TreeHash
数据结构:红黑树
总结:Set底层都是map中的key
1.3Queue
(1)LinkedList
略
(2)ArrayDeque
ArrayDeque和LinkedList之间的区别
- ArrayDeque 是一个可扩容的数组,LinkedList 是链表结构;
- ArrayDeque 里不可以存 null 值,但是 LinkedList 可以;
- ArrayDeque 在操作头尾端的增删操作时更高效,但是 LinkedList 只有在当要移除中间某个元素且已经找到了这个元素后的移除才是 O(1) 的;
- ArrayDeque 在内存使用方面更高效
- 不存null值尽量使用ArrayDeque
(3)PriorityQueue
二、Map【k-v方式存放】
(1)HashMap(线程不安全)
- JDK8之前
- 数据结构:数组+链表
- 插入方式:头插法(扩容时可能并发死链)
- JDK8
- 数据结构:数组+链表+红黑树
- 插入方式:尾插法
- 基于JDK8
- put流程
- 1.判断数组是否为空,为空进行初始化
- put流程
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
2.计算hash值(n - 1) & hash 定位下标
if ((p = tab[i = (n - 1) & hash]) == null)
- 3.判断当前的下标是否有值,没有就创建一个node节点存放到当前下标位置处
tab[i] = newNode(hash, key, value, null);
- 4.存在数据,hash冲突,先判断key是否相同,相等就使用新的value进行替换
if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k))))
e = p;
- 5.不相等的话,就判断当前节点是不是树型节点,是树型节点就以树节点的方式插入
p instanceof TreeNode)
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
- 6.如果不是树型节点就以链表节点的方式插入,并且判断数组的长度是否大于64(底层先通过数组扩容的方式提高查询效率),链表的长度是否大于8,若满足就将链表转化为红黑树
else {
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
- 7.插入完成后判断当前节点是否大于阈值,如果大于的话将数组的大小扩容为原来的两倍
if (++size > threshold)
resize();// 调用该方法
- hash算法(原始key的hash值和数组的长度进行取模)=》优化:(n-1)&hash
目标:
为什么数组的长度是2^n;
hash值的优化为什么;

- 2^n原因:
在进行与运算时,长度-1和hash值相与,反证法:那么如果是15不是2^n那么15-1=14,14的二进制数最后一位0,0和任何相与都是0。那么就会导致不能完全散列,因为有些下标位一定计算不到 - hash值的计算优化:由上图可知,取hashcode的最后四位计算,那么前面的值就浪费了,会导致散列不完全。优化取hashcode的高16位和低16位进行异或运算得到hash,再进行n-1相与运算,得到最散列的下标的值
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
(2)ConcurrentHashMap(线程安全)
学习目标
1、和hashTble之间的区别
2、为什么线程安全,怎么实现的1.7和1.8的实现区别
- key的键值可以为空=》原因上代码:当key是null的时候直接存在0处()这是上面计算hash值和n-1相与的时候
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
- 怎么实现
- JDK1.7 使用Segment分段锁实现
- JDK1.8 使用CAS和Synchronized和volatile去修饰node节点实现
- get方法整个过程没有加锁
- put方法总体和hashMap一致,区别在于再写入数据的时候,利用 CAS 尝试写入,失败则自旋保证成功。
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
// 1、如果为空,先使用casTabAt该方法cas
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
// 如果hashcode==moved则扩容
else if ((fh = f.hash) == MOVED)
tab = helpTransfer(tab, f);
else {
V oldVal = null;
// 2.如果到不满足利用synchronized写入数据
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
(3)HashTable(线程安全)
- key键值不能为null=》报空指针异常
- 线程安全,但是效率不容乐观=》原因对数据操作的时候都会进行加锁【全是锁】
public synchronized int size() {
return count;
}
public synchronized boolean isEmpty() {
return count == 0;
}
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/96253.html

