
第一章 MySQL原理
需要解决的问题:
脑海中构建一个属于总结的思维导图
数据结构间的区别
b树和b+树区别,b到b+树优化了什么,为什么要这么优化
myisam和innodb区别,共同点
什么叫聚集索引和非聚集索引
为什么建议要设主键索引,为什么要整型,自增为什么
hash数据结构和b+树,hash快为什么不使用呢
二级索引,为什么不能放data,不能放所有数据呢【回表】
联合索引用的最多—不建议太多单值索引
最左前缀原理,为什么不用左边第一个就没用了
1、索引数据结构
总:索引是排好序的数据结构(后面的很多分析都要考虑到这个点【如:索引为什么会失效】)
主要需要了解,hash,b树,b+树,了解底层数据结构原理、区别
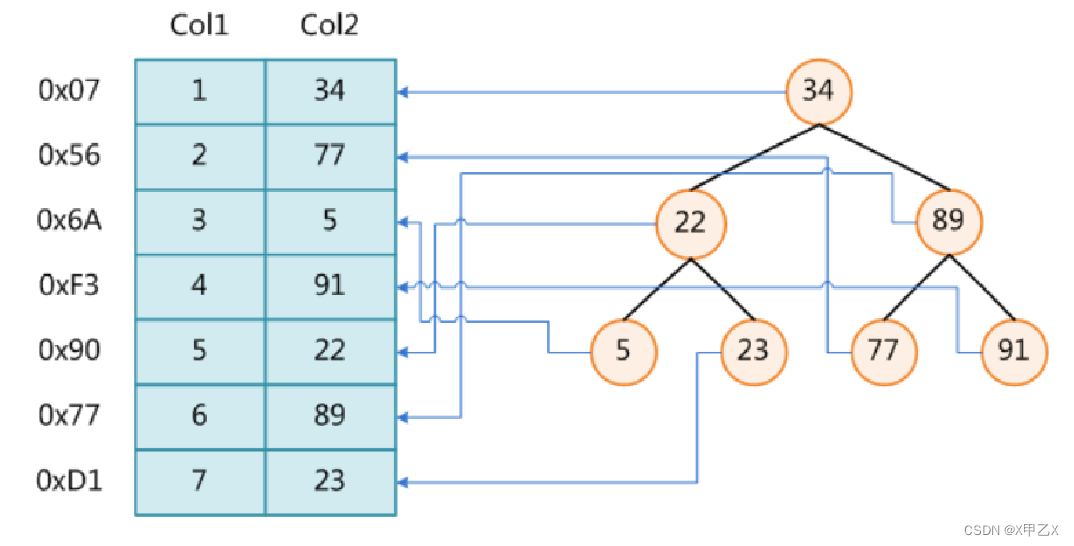
- (1)二叉树
-
二叉树:
- 缺点:因为左小右大的原则,当索引一次递增可能造成成链的问题—想办法优化成红黑树
-
红黑树
- 缺点:当数据量太大时,树的高度太高。从树的根节点出发的话,查询次数太多—–想办法优化树的高度=》b树
-
(2)hash
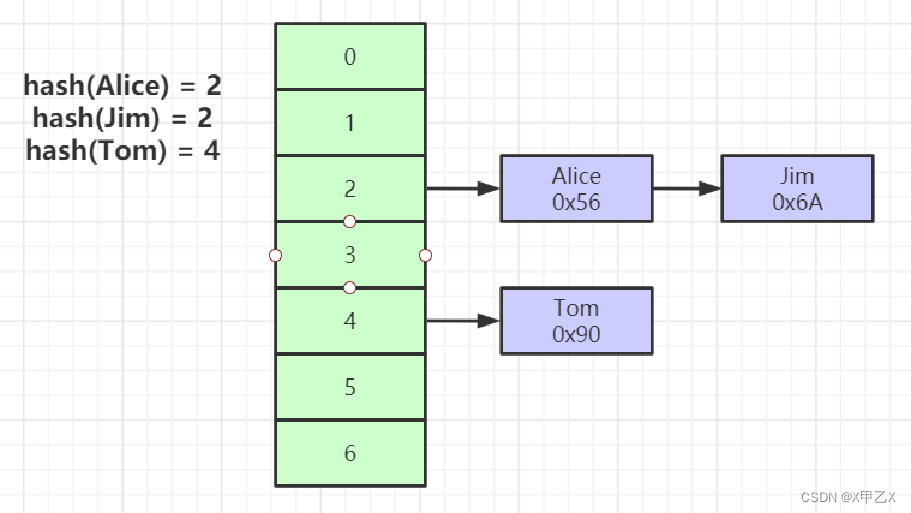
- 对key进行hash计算
- hash比b+树快
- 那为什么不使用hash呢?
- 不支持范围查找,仅支持等职查找
- 所以推荐b+树,原因叶子节点排好序并且有双向指针(详细见下面的b+树)
- 缺点:hash碰撞会
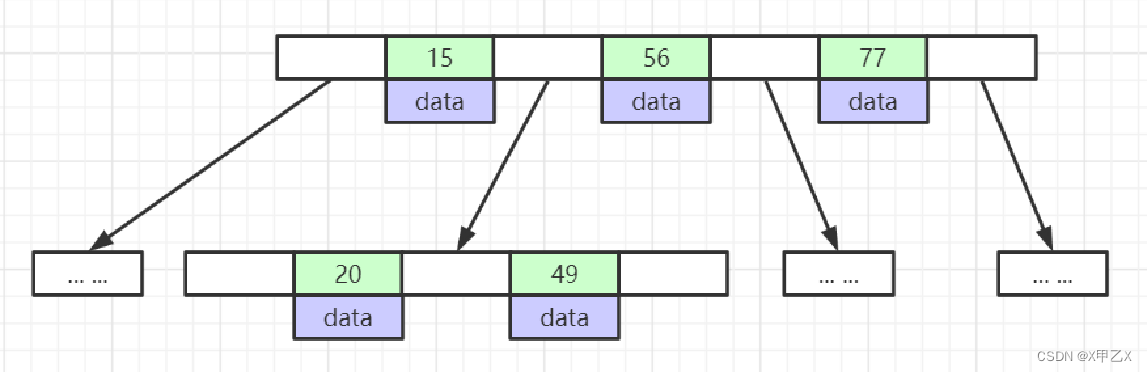
- (3)b树
-
1、通过索引构建出b树
-
2、 以key-value的形式存在,索引和值
-
3、节点中的值都是从左到右依次递增的
-
4、缺点:每个节点有data元素==》造成树的高度太高,查询次数会增加
-
5、缺点:b+树范围查找效率高,b树范围查询不高原因叶子节点没有双向指针
-
(4)b+树
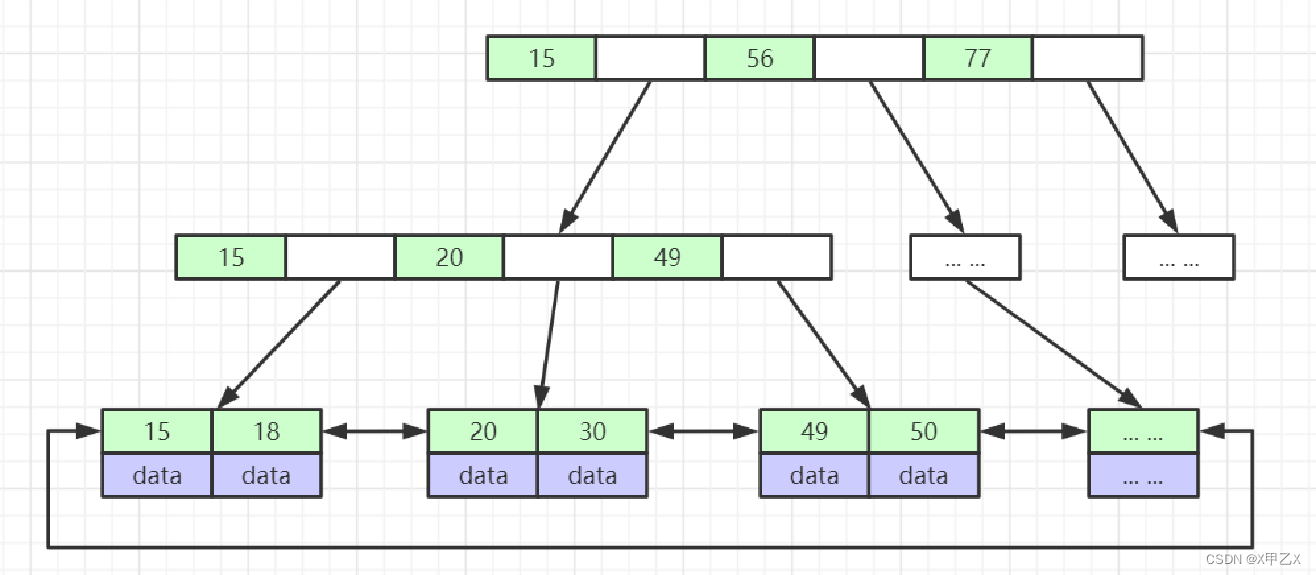
- 1、非叶子节点仅存冗余索引,不存放data(目的是为了节省空间,可以存放更多的索引;如果像b树一样以k-v的结构存放的话,那v一定会占一定的空间,导致索引放的数量减少了==》那么树的高度也会减少)
- 2、叶子节点包含所有的索引字段+data
- 3、叶子节点使用双向环形链表完成,提高访问性能
- 4、mysql将叶子节点常驻再内存中,避免了I/O的性能损耗,提高效率
2、存储引擎
- 1、MyISAM(使用b+树)
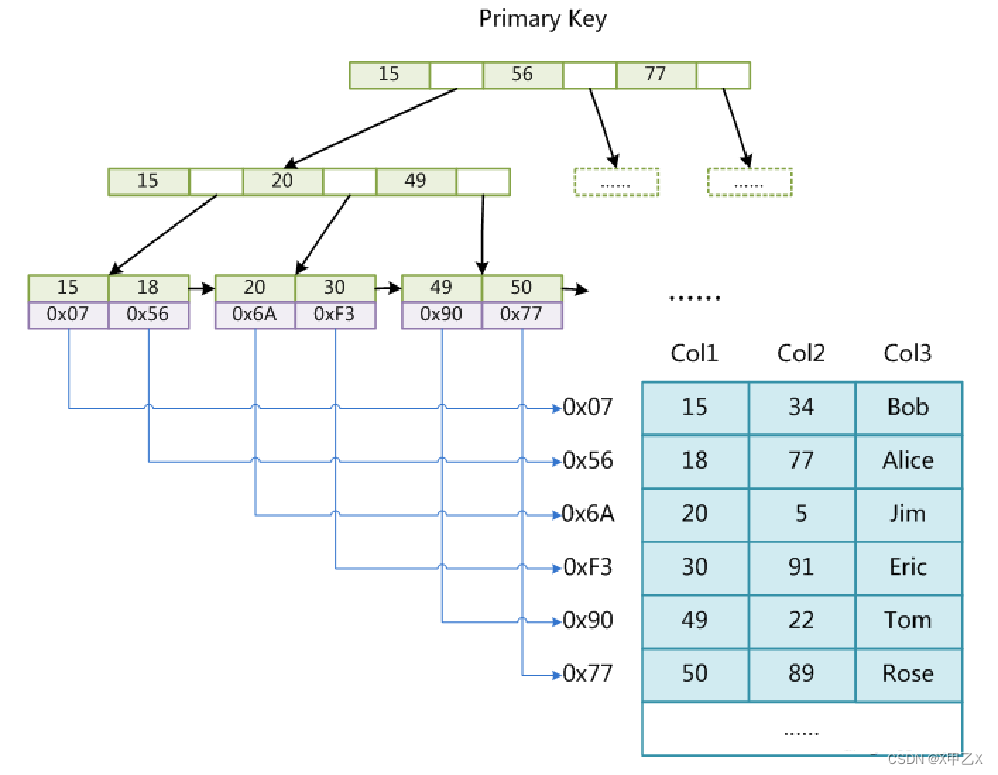
- (1)使用索引在MyISAM中查找的过程
- 通过索引查询到内存地址
- 然后通过内存地址找到对应的数据
- ==》非聚集索引
- (2)叶子节点中data存放的是内存地址
- 总结
- MyISAM是非聚集索引,通过内存地址回表进行数据查找
- InnoDB(使用b+树)
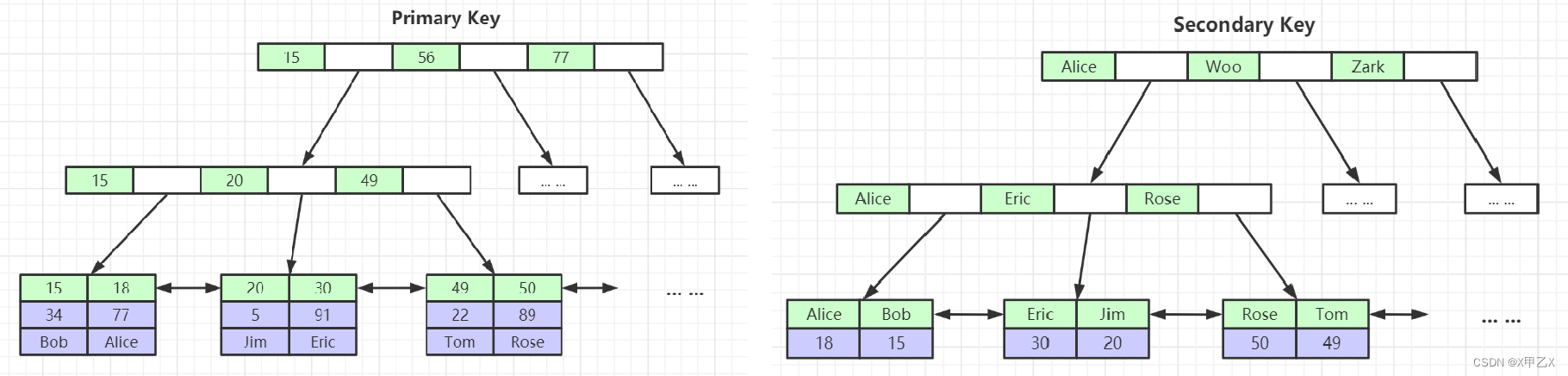
图一、主键索引 图二、二级索引
- (1)查询过程
- 通过索引定位到值直接查询
- ==》聚集索引
- (2)和MyISAM不一样的是,叶子节点data存放的完整的数据
- (3)为什么建议要设主键索引,为什么要整型,自增为什么
- 3.1:自己不建的话,mySQL自己去挑一个不会重复的列或者隐藏列,去维护一个主键索引去存储数据(建立聚集索引),这样一定是损耗性能的,那么还不如自己干
- 3.2:整型的速度比较的一定比别的快、节约空间
- 3.3:自增:因为索引都是排号序的,如果硬插入一个不是自增的元素,树会自己平衡一次(效率就下降了)
- 二级索引:在叶子节点的data中存放的是主键索引的值,然后回表到主键索引,查询到所有数据
- 总结:
- innoDB只有主键索引是聚集索引,别的索引类型不是聚集索引,还是要通过回表操作的
- 父节点中的冗余索引都是其子节点第一个节点最小的元素
3、最左前缀原则
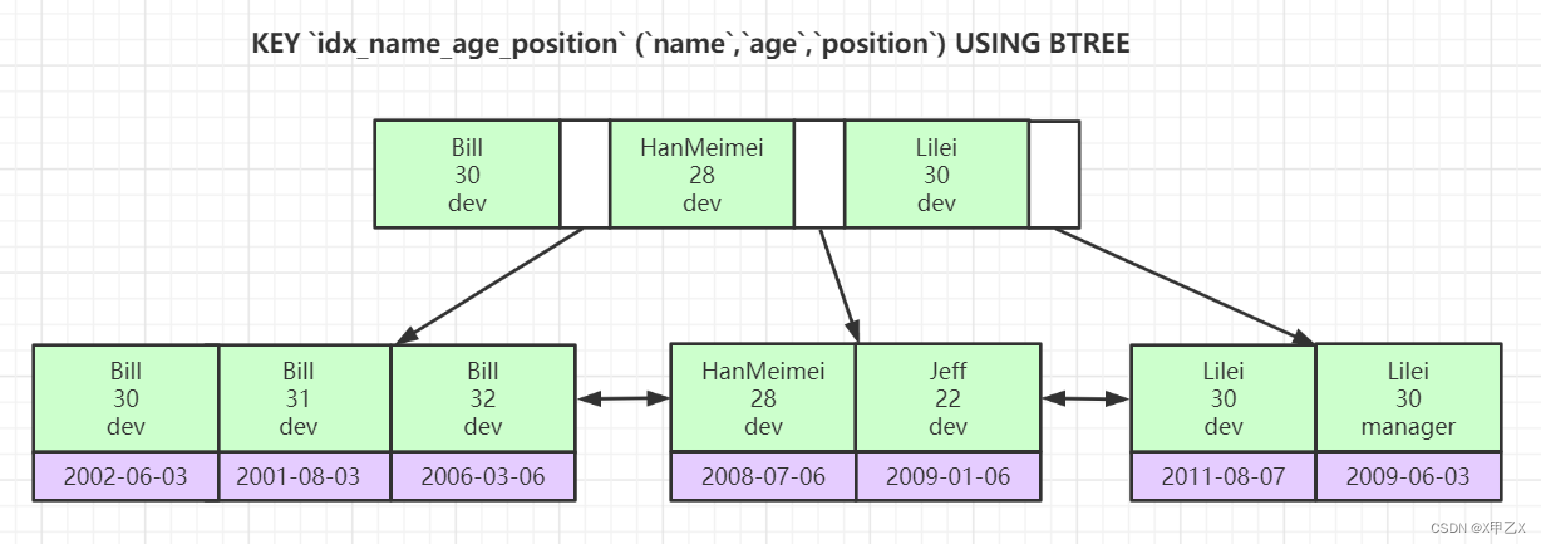
- 1、联合索引(复合索引)
- 排好序的数据结构==》先排name,name相等排age,依次类推
- 在使用索引的时候必须使用联合索引的最左边的第一个列==》原因就是在构建树的时候,每个节点都是按照你所设置好的索引排好序的,举个例子:联合索引a、b、c;在构建树的时候如果a不相同,那么直接使用a进行排序构建树,但是你使用的是b进行查询的话,它就不能够定位了。【一定要理解排好序的原理】
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/96254.html

