
前言
在爬虫中,经常需要请求其他服务器的数据(网络I/O),普通的单线程爬虫脚本在请求数据的时候需要等待服务器响应,得到服务器响应了才能运行程序的下一步,而在此期间,CPU在“摸鱼”。
本着物尽其用的原则,我们可以使用多线程进行爬虫,减少CPU资源的浪费。在使用多线程爬虫的时候,主线程可以创建子线程,并把I/O工作丢给子线程,CPU资源可以在I/O等待的时候被其他线程使用,减少CPU资源的浪费。
需求说明
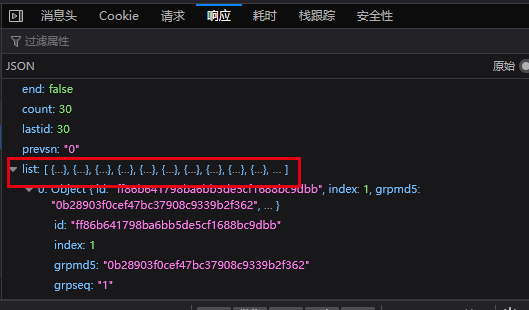
爬取链接https://image.so.com/zjl?ch=pet&t1=234&sn=0返回json格式结果中键list每一项的图片文件,并保存为文件
通过抓包分析,我们可以观察到返回的json数据中,键
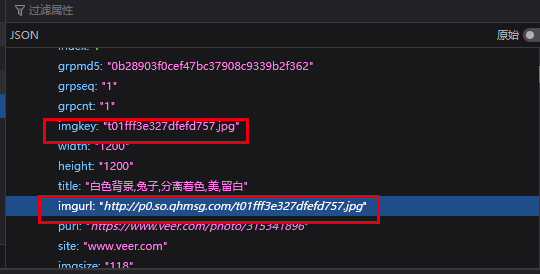
list是个列表,列表的每个元素是字典,而字典里的imgurl是图片链接,imgkey是图片名
单线程爬虫实现
- 按照单线程爬虫的思路,第一步先get请求一下
import requests
url = "https://image.so.com/zjl?ch=pet&t1=234&sn=0"
res = requests.get(url)
imgurl是图片链接,imgkey是图片名。由此,我们可以提取出图片链接进行下载,并写入到文件夹result1中,并记录开始和结束
for item in res.json()['list']:
print(item['imgkey'], "start")
res = requests.get(item['imgurl'])
with open(f"result1/{item['imgkey']}", "wb") as f:
f.write(res.content) # 图片是二进制文件,这里使用content返回二进制值
print(item['imgkey'], "end")
- 最后,添加测试爬取图片所用时间的功能就算是完成了。下面是整个完整的程序(记得运行时现在本目录下创建子目录result1)
import requests
from time import time
if __name__ == "__main__":
url = "https://image.so.com/zjl?ch=pet&t1=234&sn=0"
res = requests.get(url)
start = time() # 开始时间
for item in res.json()['list']:
print(item['imgkey'], "start")
res = requests.get(item['imgurl'])
with open(f"result1/{item['imgkey']}", "wb") as f:
f.write(res.content)
print(item['imgkey'], "end")
print(time()-start) # 输出总用时
- 运行结果(用时3.9978415966033936秒)
t01fff3e327dfefd757.jpg start
t01fff3e327dfefd757.jpg end
t012bc7fa426e375590.jpg start
t012bc7fa426e375590.jpg end
t01e9237ba6affc4709.jpg start
t01e9237ba6affc4709.jpg end
t018548c82afd6fe4fa.jpg start
t018548c82afd6fe4fa.jpg end
t012452c44ae1e03ee9.jpg start
t012452c44ae1e03ee9.jpg end
t017e1e64ec2ef320eb.jpg start
t017e1e64ec2ef320eb.jpg end
t01c31d0adabb06e139.jpg start
t01c31d0adabb06e139.jpg end
t011137992b3e445e62.jpg start
t011137992b3e445e62.jpg end
t010fe4279f75464165.jpg start
t010fe4279f75464165.jpg end
t013b6ed19044dc444d.jpg start
t013b6ed19044dc444d.jpg end
t013efc4bbf36588482.jpg start
t013efc4bbf36588482.jpg end
t0120e7235fd4985d5c.jpg start
t0120e7235fd4985d5c.jpg end
t0175b8b85154cd124e.jpg start
t0175b8b85154cd124e.jpg end
t014f09a78ef3d57c60.jpg start
t014f09a78ef3d57c60.jpg end
t01970874ca3cb8632d.jpg start
t01970874ca3cb8632d.jpg end
t01214a2e5515e5e5c2.jpg start
t01214a2e5515e5e5c2.jpg end
t01f168443b2b9c1bff.jpg start
t01f168443b2b9c1bff.jpg end
t016fb140dc2c4c4b99.jpg start
t016fb140dc2c4c4b99.jpg end
t0163ced1cc024d5c38.jpg start
t0163ced1cc024d5c38.jpg end
t014a7875829ab1432a.jpg start
t014a7875829ab1432a.jpg end
t019098acecc9bc7c84.jpg start
t019098acecc9bc7c84.jpg end
t01f49c1fbc29c5c628.jpg start
t01f49c1fbc29c5c628.jpg end
t01e9a2ebd3155ef46b.jpg start
t01e9a2ebd3155ef46b.jpg end
t01bd0d7979824853e0.jpg start
t01bd0d7979824853e0.jpg end
t01e7c0642fefbfd573.jpg start
t01e7c0642fefbfd573.jpg end
t016172b23bed477cc6.jpg start
t016172b23bed477cc6.jpg end
t01f186adbed44375da.jpg start
t01f186adbed44375da.jpg end
t01954ee1c79c0797b1.jpg start
t01954ee1c79c0797b1.jpg end
t01273160790d7c134c.jpg start
t01273160790d7c134c.jpg end
t0174fc8cd05506a1c6.jpg start
t0174fc8cd05506a1c6.jpg end
3.9978415966033936
多线程爬虫实现
- 首先,还是一样的,get方法请求图片资源列表
import requests
url = "https://image.so.com/zjl?ch=pet&t1=234&sn=0"
res = requests.get(url)
- 接下来这一步是关键,我们要在循环里创建并开启子线程
def save_img(url, filename):
'''
将链接为url的图片下载并保存到文件夹result2中,文件名为filename
'''
print(filename, "start")
res = requests.get(url)
with open(f"result2/{filename}", "wb") as f:
f.write(res.content)
print(filename, "end")
threads = [] # 线程列表
for item in res.json()['list']:
thread = Thread(target=save_img, args=(item['imgurl'], item['imgkey'])) # 创建线程对象,target是处理线程所使用的函数,元组args是函数的参数
thread.start() # 开启线程
threads.append(thread) # 将线程添加进线程列表
for thread in threads:
thread.join() # 线程阻塞
- 添加用时测试后,完整程序如下(记得创建目录result2)
import requests
from time import time
from threading import Thread
def save_img(url, filename):
print(filename, "start")
res = requests.get(url)
with open(f"result2/{filename}", "wb") as f:
f.write(res.content)
print(filename, "end")
if __name__ == "__main__":
url = "https://image.so.com/zjl?ch=pet&t1=234&sn=0"
res = requests.get(url)
start = time()
threads = []
for item in res.json()['list']:
thread = Thread(target=save_img, args=(item['imgurl'], item['imgkey']))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
print(time()-start)
- 运行结果(用时2.5666840076446533秒)
t01fff3e327dfefd757.jpg start
t012bc7fa426e375590.jpg start
t01e9237ba6affc4709.jpg start
t018548c82afd6fe4fa.jpg start
t012452c44ae1e03ee9.jpg start
t017e1e64ec2ef320eb.jpg start
t01c31d0adabb06e139.jpg start
t011137992b3e445e62.jpg start
t010fe4279f75464165.jpg start
t013b6ed19044dc444d.jpg start
t013efc4bbf36588482.jpg start
t0120e7235fd4985d5c.jpg start
t0175b8b85154cd124e.jpg start
t014f09a78ef3d57c60.jpg start
t01970874ca3cb8632d.jpg start
t01214a2e5515e5e5c2.jpg start
t01f168443b2b9c1bff.jpg start
t016fb140dc2c4c4b99.jpg start
t0163ced1cc024d5c38.jpg start
t014a7875829ab1432a.jpg start
t019098acecc9bc7c84.jpg start
t01e9a2ebd3155ef46b.jpg start
t01bd0d7979824853e0.jpg start
t01e7c0642fefbfd573.jpg start
t016172b23bed477cc6.jpg start
t01f186adbed44375da.jpg start
t01954ee1c79c0797b1.jpg start
t01273160790d7c134c.jpg start
t0174fc8cd05506a1c6.jpg start
t01f49c1fbc29c5c628.jpg start
t0120e7235fd4985d5c.jpg end
t017e1e64ec2ef320eb.jpg end
t012bc7fa426e375590.jpg end
t01e9a2ebd3155ef46b.jpg end
t01f49c1fbc29c5c628.jpg end
t016fb140dc2c4c4b99.jpg end
t019098acecc9bc7c84.jpg end
t01bd0d7979824853e0.jpg end
t01214a2e5515e5e5c2.jpg end
t01fff3e327dfefd757.jpg end
t01e7c0642fefbfd573.jpg end
t010fe4279f75464165.jpg end
t014a7875829ab1432a.jpg end
t014f09a78ef3d57c60.jpg end
t011137992b3e445e62.jpg end
t013b6ed19044dc444d.jpg end
t01273160790d7c134c.jpg end
t0163ced1cc024d5c38.jpg end
t01f186adbed44375da.jpg end
t012452c44ae1e03ee9.jpg end
t01954ee1c79c0797b1.jpg end
t01f168443b2b9c1bff.jpg end
t018548c82afd6fe4fa.jpg end
t016172b23bed477cc6.jpg end
t0175b8b85154cd124e.jpg end
t0174fc8cd05506a1c6.jpg end
t013efc4bbf36588482.jpg end
t01970874ca3cb8632d.jpg end
t01e9237ba6affc4709.jpg end
t01c31d0adabb06e139.jpg end
2.5666840076446533
创建并开启子线程后,程序的运行大概过程是这样:
- 主线程创建子线程1
- 子线程1发起请求,马上进入I/O等待,并把CPU资源释放
- 主线程创建子线程2
- 子线程2发起请求,马上进入I/O等待,并把CPU资源释放
- ……
- 子线程12收到服务器响应,调用CPU资源,将文件写入,并把CPU资源释放(这个过程没有明确的先后顺序,谁先收到服务器响应就谁先开始后续操作)
- 子线程6收到服务器响应,调用CPU资源,将文件写入,并把CPU资源释放
- ……
- 程序结束
总结
多线程爬虫相较于单线程爬虫有比较明显的性能提升,具体表现在网络I/O的时候多线程爬虫的CPU资源会释放给其他线程使用,当这种I/O数量越高的时候这种效果就越明显。
如果觉得有学到东西的话,不要吝啬你手中免费的赞哟
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/97111.html

