
📖摘要
在使用msyql进行模糊查询的时候,很自然的会用到like语句,通常情况下,在数据量小的时候,不容易看出查询的效率,但在数据量达到百万级,千万级的时候,查询的效率就很容易显现出来。这个时候查询的效率就显得很重要!
😱LIKE查询
一般情况下like模糊查询的写法为(field已建立索引):
SELECT `column` FROM `table` WHERE `field` like '%keyword%';
上面的语句用explain解释来看,SQL语句并未用到索引,而且是全表搜索,如果在数据量超大的时候,可想而知最后的效率会是这样
对比下面的写法:
SELECT `column` FROM `table` WHERE `field` like 'keyword%';
这样的写法用explain解释看到,SQL语句使用了索引,搜索的效率大大的提高了!
但是有的时候,我们在做模糊查询的时候,并非要想查询的关键词都在开头,所以如果不是特别的要求,”keywork%”并不合适所有的模糊查询
这个时候,我们可以考虑用其他的方法
LOCATE('substr',str,pos)方法
SELECT LOCATE('xbar',`foobar`);
###返回0
SELECT LOCATE('bar',`foobarbar`);
###返回4
SELECT LOCATE('bar',`foobarbar`,5);
###返回7
备注:返回 substr 在 str 中第一次出现的位置,如果 substr 在 str 中不存在,返回值为 0 。如果pos存在,返回 substr 在 str 第pos个位置后第一次出现的位置,如果 substr 在 str 中不存在,返回值为0。
SELECT `column` FROM `table` WHERE LOCATE('keyword', `field`)>0
备注:keyword是要搜索的内容,field为被匹配的字段,查询出所有存在keyword的数据
🌂优化
数据如下
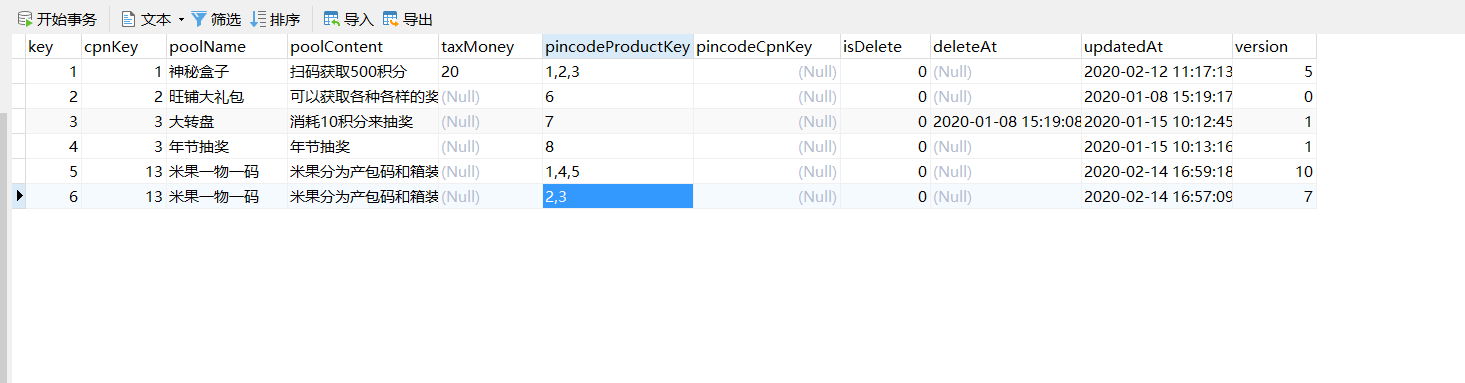
一、POSITION('substr' INfield)方法
position可以看做是locate的别名,功能跟locate一样
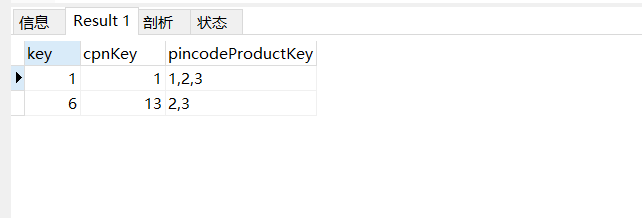
SELECT `key`,cpnKey,pincodeProductKey FROM hotkidclub_draw.`cpn_pool` WHERE POSITION('2' IN `pincodeProductKey`);

二、INSTR(str,'substr')方法
SELECT `key`,cpnKey,pincodeProductKey FROM hotkidclub_draw.`cpn_pool` WHERE INSTR(`pincodeProductKey`, '2' )>0 ;
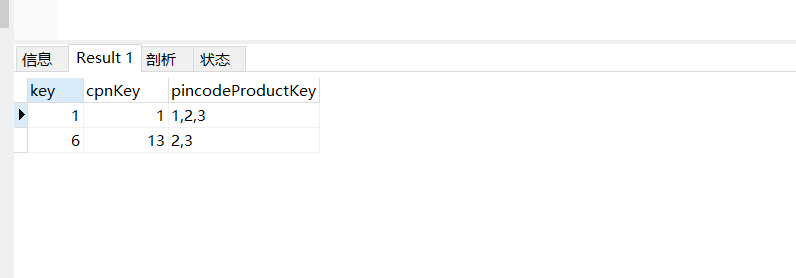
三、除了上述的方法外,还有一个函数FIND_IN_SET('值',filed);
返回str2中str1所在的位置索引,其中str2必须以”,”分割开。
SELECT `key`,cpnKey,pincodeProductKey FROM hotkidclub_draw.`cpn_pool` WHERE FIND_IN_SET('2',`pincodeProductKey`);
🎉最后
-
更多参考精彩博文请看这里:《陈永佳的博客》
-
喜欢博主的小伙伴可以加个关注、点个赞哦,持续更新嘿嘿!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/97502.html

