
Python的json、pickle和shelve模块!
今天博主跟大家聊一聊如何使用Python的json、pickle和shelve模块!不喜勿喷,如有建议欢迎补充、讨论!
关于安装和汉化可以观看博主的这篇文章《下载安装及汉化 》以及Python系列:windows10配置Python3.0开发环境!,安装完毕重启VsCode!以及VSCode配置Python开发环境!
Come on!json模块
在之前的Python内置函数,提到eval可以将一个字符串转换为一个python对象,然而不幸的是,eval只能处理简单的普通的类型,但遇到特殊类型的时候,eval就不好使了,所以eval的重点还是通常用来执行一个字符串表达式,并返回表达式的值。例如:
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
'''
@File : built-inDemo.py
@Time : 2019/10/21 10:53:02
@Author : YongJia Chen
@Version : 1.0
@Contact : chen867647213@163.com
@License : (C)Copyright 2018-2019, Liugroup-NLPR-CASIA
@Desc : None
'''
# here put the import lib
x = "['null',True,False,1]"
print(eval(x), type(eval(x)))
#若使用json模块则需有个序列化和反序列化的过程,如下:
import json
y = ["null", True, False, 1]
#序列化
st1 = json.dumps(y)
print(st1, type(st1))
#反序列化
lis1 = json.loads(st1)
print(lis1, type(lis1))
# 输出为:
#['null', True, False, 1] <class 'list'>
#["null", true, false, 1] <class 'str'>
#['null', True, False, 1] <class 'list'>
什么是序列化:
我们把对象(或者变量)从内存中变为可存储或者可传输的过程称为序列化。在python中为pickling,在其他语言中也被称之为serialization,marshalling,flattening等等。
即序列化之后既可以将内存中的程序内容写入硬盘或者通过网络传输到其他机器上去。
而反序列化的过程则相反:将硬盘中的内容变为可以在内存中运行的程序的过程称为反序列化。
看一下实现序列化和反序列化的几种方法:dump、dumps、load、loads等
dumps 和 loads
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
'''
@File : xuliehuademo.py
@Time : 2019/10/21 11:03:26
@Author : YongJia Chen
@Version : 1.0
@Contact : chen867647213@163.com
@License : (C)Copyright 2018-2019, Liugroup-NLPR-CASIA
@Desc : None
'''
# here put the import lib
#通过序列化和反序列化将内容存储到文件
import json
info = {"name": "little-five", "age": 22, "hobby": "dance"}
#dumps --> 序列化
info_str = json.dumps(info)
with open("information.txt", "w") as f1:
f1.write(info_str)
with open("information.txt", "r") as f2:
# print(f2.read(),type(f2.read()))
#loads --> 反序列化
info_dict = json.loads(f2.read())
print(info_dict, type(info_dict))
# 输出为:
# {'name': 'Mr_Chen', 'age': 21, 'hobby': 'dance'} <class 'dict'>
dump 和 load
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
'''
@File : xuliehuademo2.py
@Time : 2019/10/21 11:04:22
@Author : YongJia Chen
@Version : 1.0
@Contact : chen867647213@163.com
@License : (C)Copyright 2018-2019, Liugroup-NLPR-CASIA
@Desc : None
'''
# here put the import lib
import json
info = {"name": "Mr_Chen", "age": 21, "hobby": "dance"}
f1 = open("information.txt", "w")
json.dump(info, f1) #== 1、info=json.dumps(info) 2、f.write(info)
f1.close()
f2 = open("information.txt", "r")
info_dic = json.load(f2) #== info_dic =json.loads(f2.read())
print(info_dic, type(info_dic))
# 输出为
# {'name': 'Mr_Chen', 'age': 21, 'hobby': 'dance'} <class 'dict'>
pickle模块
pickle和json的用法几乎相同,但是pickle可以处理的数据类型更多,但是仅限于python的使用,而无法应用到其他的语言中去,并且可能不同版本的Python彼此都不兼容,因此,只能用Pickle保存那些不重要的数据,不能成功地反序列化也没关系。
- 1、pickle序列化后处理成字节格式,而json序列化后处理成字符串格式。
- 2、pickle的序列化和反序列化必须同用。而json不必。
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
'''
@File : pickleDemo.py
@Time : 2019/10/21 11:14:03
@Author : YongJia Chen
@Version : 1.0
@Contact : chen867647213@163.com
@License : (C)Copyright 2018-2019, Liugroup-NLPR-CASIA
@Desc : None
'''
# here put the import lib
import pickle
dic = {'name': 'sunny chen', 'age': 21}
dic = pickle.dumps(dic) #处理成字节格式
print(dic, type(dic))
#输出为:b'\x80\x03}q\x00(X\x04\x00\x00\x00nameq\x01X\n\x00\x00\x00sunny chenq\x02X\x03\x00\x00\x00ageq\x03K\x15u.' <class 'bytes'>
#由于写入的是字节格式,故必须用wb模式写入
with open("pickle_test", "wb") as f1:
# f1.write(bytes("hello world",encoding="utf-8"))
f1.write(dic)
#写入的文本是不可读的,即打开pickle_test显示为不可读
f2 = open("pickle_test", "rb")
data = pickle.loads(f2.read())
print(data, type(data))
#输出为:{'name': 'sunny chen', 'age': 21} <class 'dict'>
shelve模块
shelve模块比pickle模块简单,只有一个open函数,返回类似字典的对象,可读可写;key必须为字符串,而值可以是python所支持的数据类型。
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
'''
@File : shelveDemo.py
@Time : 2019/10/21 11:15:43
@Author : YongJia Chen
@Version : 1.0
@Contact : chen867647213@163.com
@License : (C)Copyright 2018-2019, Liugroup-NLPR-CASIA
@Desc : None
'''
# here put the import lib
import shelve
f = shelve.open(r"shelve_test.txt")
f["stu1"] = {"name": "Mr_Chen", "age": 21}
f["stu2"] = {"name": "Sunny Chen", "age": 21}
f["school"] = {"name": "shehui_university", "addr": "China"}
# f.close()
stu1_info = f.get("stu1")
print(stu1_info["age"]) #21
shelve模块在存储时,会创建三个文件,即也是以特殊文件的形式,可以使用字典的存储功能,相当于更加高级的内容管理文件。如下:
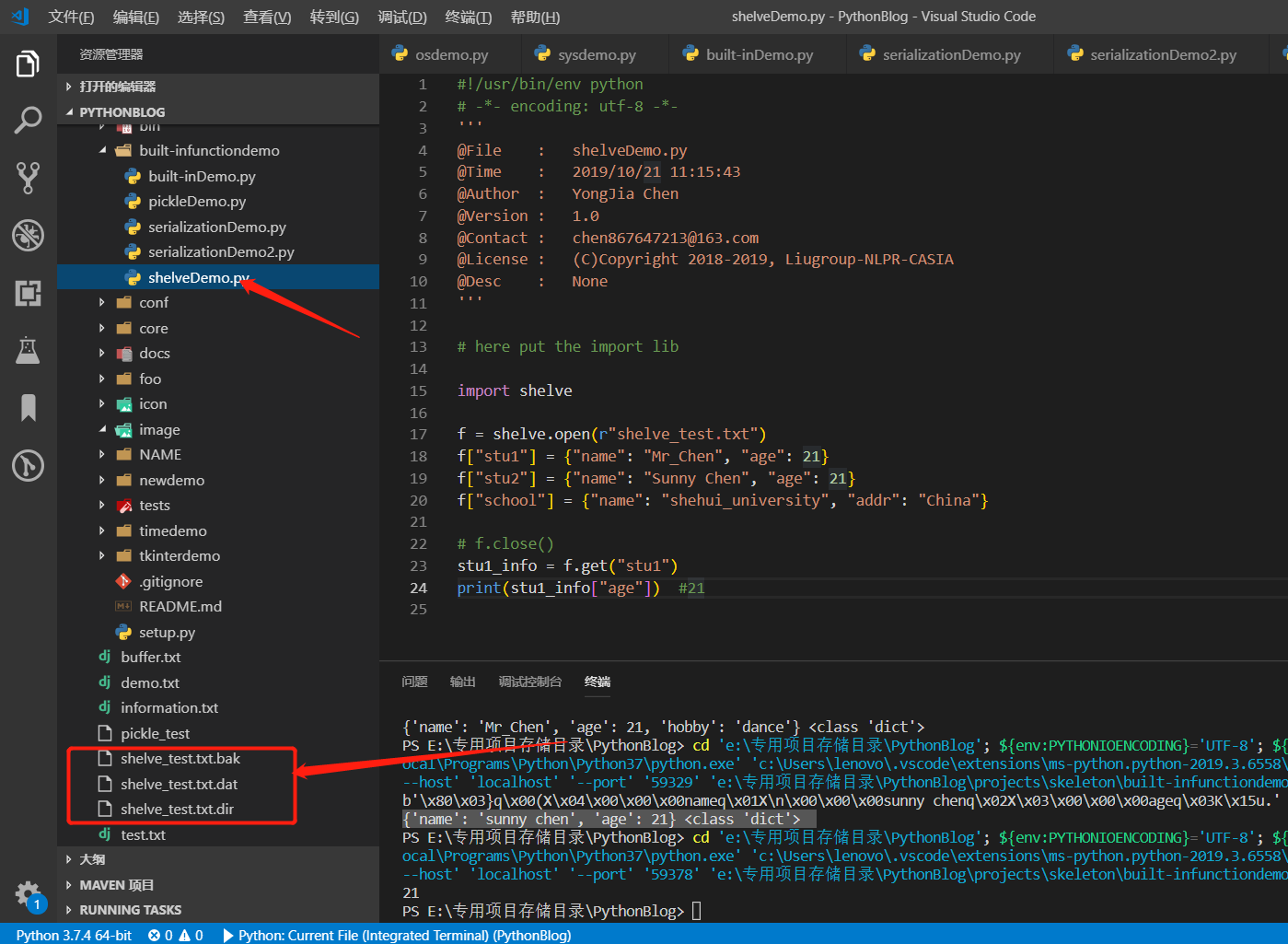

这三种模块主要针对序列化和反序列化的操作,用于内存中程序的存储和网络传输。三者均有不同点,各有利弊。
快去动手试试吧!
到这里:Python的json、pickle和shelve模块!分享完毕了,快去试试吧!
最后
-
更多参考精彩博文请看这里:陈永佳的博客
-
喜欢博主的小伙伴可以加个关注、点个赞哦,持续更新嘿嘿!
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/97701.html

