

row_number:它会为查询出来的每一行记录生成一个
序号,依次排序且不会重复。
rank&dense_rank:在各个分组内,rank()是跳跃排
序,有两个第一名时接下来就是第三名,dense_rank()
是连续排序,有两个第一名时仍然跟着第二名。
需求1:2019年1月,用户购买商品品类数量的排名
select user_name,count(distinct goods_category),
row_number()over(order by count(distinct goods_category)desc),
rank() over(order by count(distinct goods_category)desc),
dense_rank() over(order by count(distinct goods_category)desc)
from user_trade
where substr(dt, 1, 7) = '2019-01'
group by user_name;
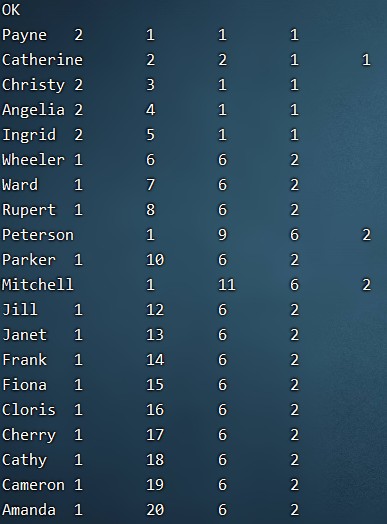
– 需求5:选出2019年支付金额排名在第10、20、30名的用户
select a.user_name,a.total_amount,a.total_rank
from
(select user_name,sum(pay_amount)as total_amount,
rank() over(order by sum(pay_amount)) as total_rank
from user_trade
where year(dt)=2019
group by user_name)a
where a.total_rank in (10,20,30);

– 为什么这里的2019没有引号?前面的2019-01有引号?
– year()函数获取出的内容可以和数字或字符串进行比较
– substr()截取的就是字符串 类型就已经限定了只能和字符串比较
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/98022.html

