
一.均值 RFM模型算法
从csv文件中读取相应的数据
data=pd.read_csv('./dataset.csv',encoding='ISO-8859-1')
#读取2014年的客户信息
data_14=data[data['Order-year']==2014]
data_14
2.获取相应的列
data_14 = data_14[['CustomerID','OrderDate','Sales']]
data_14
CustomerID为用户id
OrderDate为下单日期
Sales 为销售金额
3.复制数据(以免修改时改变原有数据)
customerdf=data_14.copy()
customerdf
4.设置CustomerID为索引
customerdf.set_index('CustomerID',drop=True,inplace=True)
5添加交易次数字段(后期计算F时方便)
customerdf['orders']=1
customerdf
6做透视表
最后一次购买时间 购买次数 购买总金额
rfmdf=customerdf.pivot_table(
index=['CustomerID'],
values=['OrderDate','orders','Sales'],
aggfunc={
'OrderDate':'max',
'orders':'sum',
'Sales':'sum'
}
)
aggfunc为各个字段的设置运算 OrderDate 取出最大值,orders为下单次数去和,Sales求每个用户的销售总金额
7. 每一位用户的 R F M
用相同的的标准减去每一位用户最后购买的时间即可算出R,标准一样,则R标准一样
rfmdf['R']=(rfmdf.OrderDate.max()-rfmdf.OrderDate).dt.days
rfmdf.rename(columns={'Sales':'M','orders':'F'},inplace=True)
rfmdf
rfmdf.OrderDate.max()为整个2014年下单日期的最大值,此值可任意选择,选定一个值,则求出的每一列的值都是标准值.
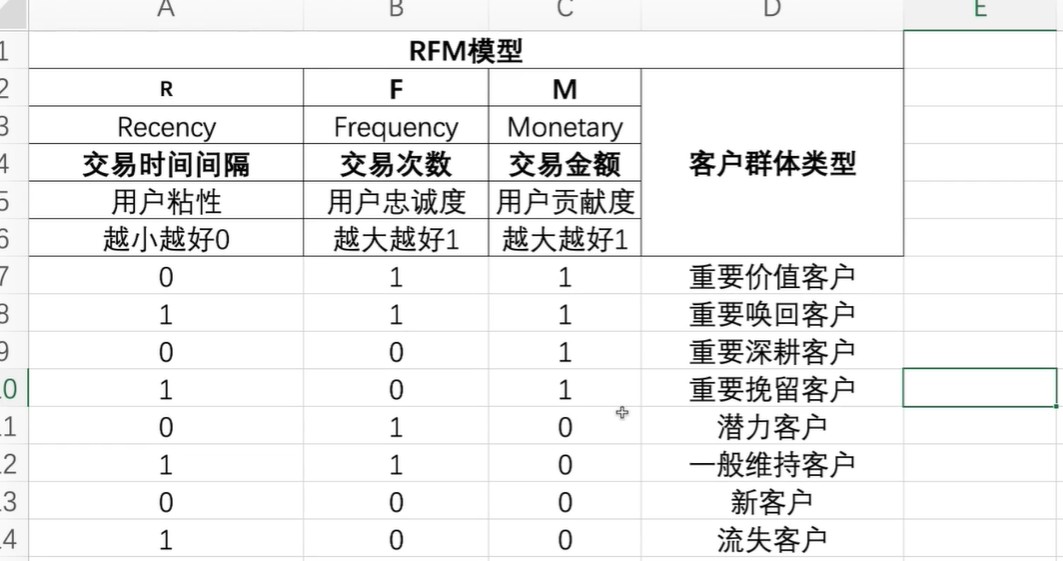
8用户打标签算法
判断结果返回字符串.以便后面将其拼接,整型数字无法拼接
def rfm_func(x):
#与均值的差设置成0和1状态
res=x.apply(lambda x:'1'if x>0 else '0')
label=res.R+res.F+res.M
d={
'011':'重要价值客户',
'111':'重要唤回客户',
'001':'重要深耕客户',
'101':'重要挽留客户',
'010':'潜力客户',
'110':'一般维持客户',
'000':'新客户',
'100':'流失客户'
}
result=d[label]
return result
9.将RFM进行连接,每个RFM之分别于均值做差,然后用函数将每个用户打上标签
rfmdf['label']=rfmdf[['R','F','M']].apply(lambda x:x-x.mean()).apply(rfm_func,axis=1)
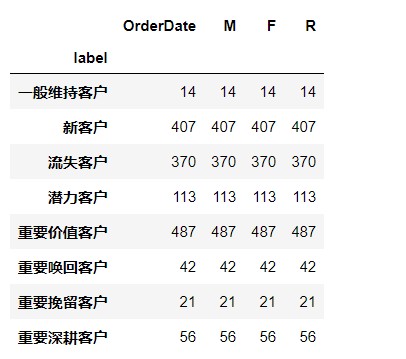
10.计算每种客户类型的数量
rfmdf.groupby('label').count()
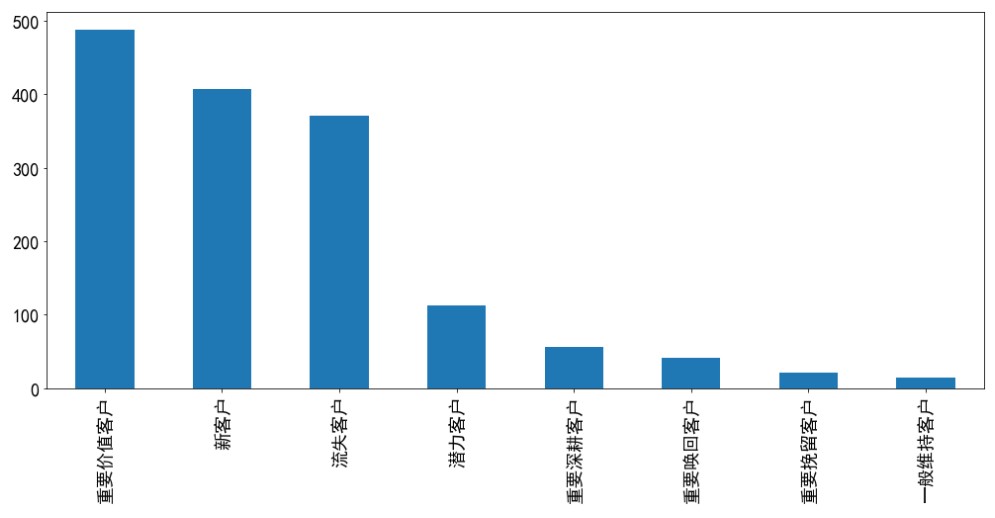
11.将每种客户类型作为横坐标,客户类型的值即数量作为纵坐标进行绘图
rfmdf.label.value_counts().plot.bar(figsize=(20,8),fontsize=15)
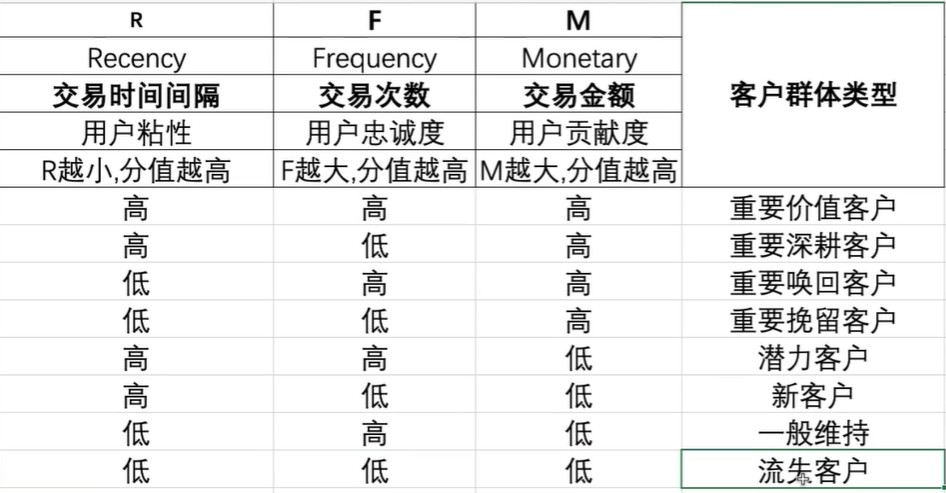
二 RFM评分算法
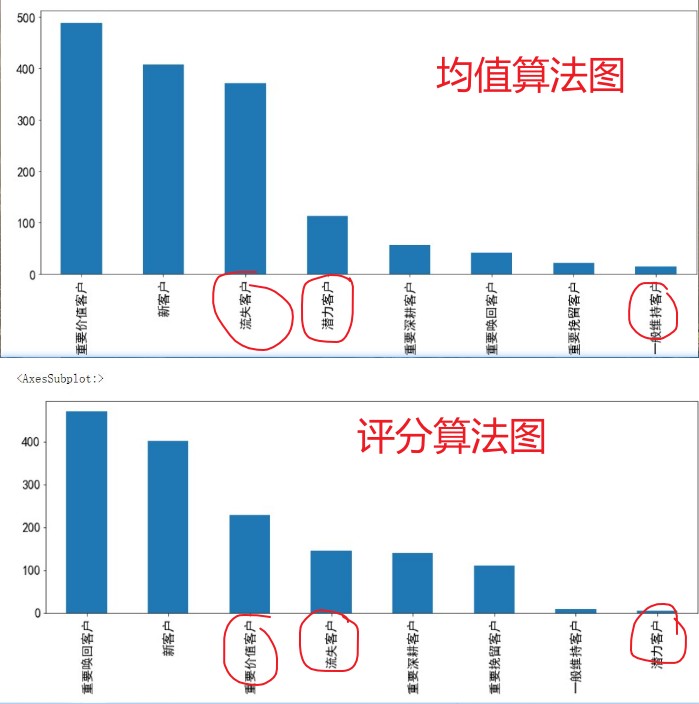
注:均值算法将最大值和最小值的误差拉小,从而使得整个统计误差变大.
评分算法就是为每个用户根据一定的区间为其用户进行打分,使得整体统计精确值提升.
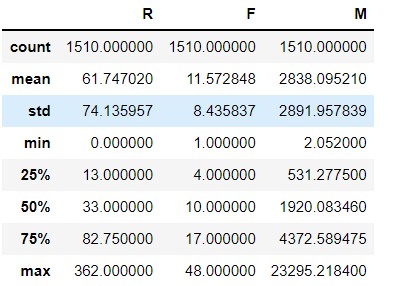
1.统计表的基本信息
customer_grade_df = rfmdf[['R','F','M']]
customer_grade_df.describe()
2.设置打分区间
#1.1 F值区间打分 F值越大,分越高
section_list_F=[0,5,10,15,20,50]
grade_F=pd.cut(customer_grade_df['F'],bins=section_list_F,labels=[1,2,3,4,5])
grade_F
customer_grade_df['F_S']=grade_F.values
#1.2 M值区间打分 M值越大,分越高
section_list_M=[0,500,1000,5000,10000,30000]
grade_M=pd.cut(customer_grade_df['M'],bins=section_list_M,labels=[1,2,3,4,5])
grade_M
customer_grade_df['M_S']=grade_M.values
#1.3 R值区间打分 R值越小,分越高
section_list_R=[-1,32,93,186,270,365]
grade_R=pd.cut(customer_grade_df['R'],bins=section_list_R,labels=[5,4,3,2,1])
grade_R
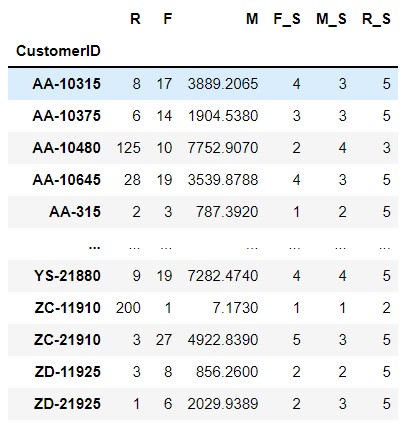
customer_grade_df['R_S']=grade_R.values
customer_grade_df
注意:每个RFM的区间的设定是根据上表的最大值和最小值设定的,一定要将字段的数值都包含在内,否则会使整个统计值出现误差
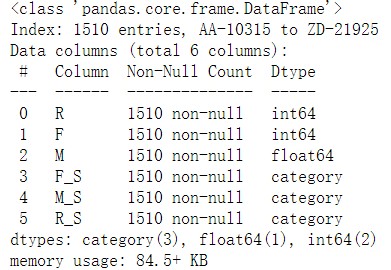
3.查看表的基本信息
customer_grade_df.describe()
#可以查到R_S,F_S,M_S 不是浮点型数字,是个category类型
#无法进行计算,需要进行转换,这是由于pandas库cut函数导致
customer_grade_df.info()
4.修改category类型为int64
rfm_score_grade=pd.DataFrame(customer_grade_df[['R_S','F_S','M_S']],dtype=np.int64)
rfm_score_grade.dtypes

5.根据打分情况,给用户打标签(同均值算法一样)
def rfm_score_func(x):
level=x.apply(lambda x: '1'if x>=0 else '0')
label = level.R_S+level.F_S+level.M_S
d={
'011':'重要价值客户',
'111':'重要唤回客户',
'001':'重要深耕客户',
'101':'重要挽留客户',
'010':'潜力客户',
'110':'一般维持客户',
'000':'新客户',
'100':'流失客户'
}
result=d[label]
return result
rfm_score_grade['RFM']=rfm_score_grade[['R_S','F_S','M_S']].apply(lambda x:x-x.mean()).apply(rfm_score_func,axis=1 )
rfm_score_grade
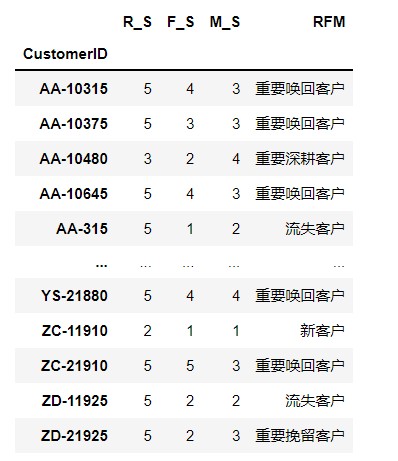
6.计算每种每种类型客户的数量
rfm_score_grade.groupby('RFM').count()

7. 绘图
rfm_score_grade.RFM.value_counts().plot.bar(figsize=(20,8),fontsize=16)
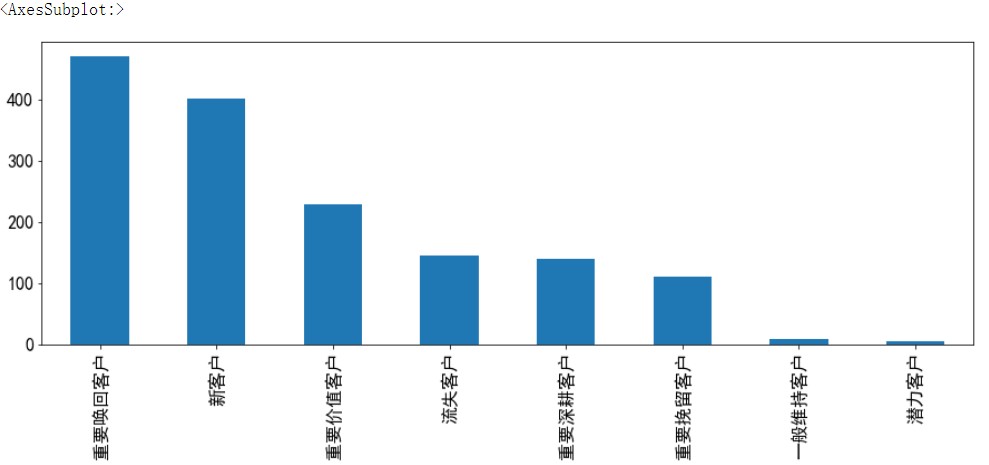
三 类比均值算法图和评分算法图,由此可看出 均值误差大
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
文章由极客之音整理,本文链接:https://www.bmabk.com/index.php/post/98023.html

